Note : cet article a été mis à jour en décembre 2021, puis en août 2023 dans une optique d’épicénisation.
Le monde du test fait face à un paradoxe.
D’une part, peu de formations initiales proposent de se lancer dans la profession, et le métier, quoique de plus en plus recherché en entreprise, peine à sortir de l’ombre. A l’heure actuelle, il est relativement difficile d’attraper des QA dans son Pokédex.
D’autre part, un nombre croissant de personnes se tournent vers les métiers du test en ayant une vision très floue des activités auxquelles elles devront prendre part, ou qui ont des attendus parfois complètement erronés. Un exemple vécu ? « Je souhaite quitter mon poste de développeur pour un emploi de QA car c’est moins difficile et il y a moins de responsabilités ! »
Plus fréquemment, nous recevons des candidatures de la part de profils divers, plus ou moins intrigués par le métier, mais sans notions de test logiciel.
Pour essayer de faire coïncider un peu mieux offre et demande, voici donc quelques pistes à l’usage des personnes qui aspirent à embrasser ce métier.
Avertissement : dans cet article, nous employons le terme « QA » au sens générique du terme ; cela englobe beaucoup de dénominations particulières que l’on peut retrouver par ailleurs (analyste qualité, spécialiste en test logiciel, test manager, etc).
Sommaire
- Quels prérequis pour devenir QA ?
- Quelles sont les tâches des QA ?
- L’exécution des tests manuels à partir d’un référentiel de tests
- La conception des tests
- La gestion des anomalies
- Les tests exploratoires
- L’automatisation des tests
- En bref : un métier polyvalent
- Les outils des QA
- Les outils de gestion des tests
- Les outils d’automatisation des tests
- Les outils transverses
- Et surtout…
- Les formations
- Les formations universitaires
- Les formations éligibles au CPF
- La POE
- L’auto-formation
- Premier entretien !
- Pourquoi le métier de QA est-il si peu connu ?
- Une famille de métiers, une multitude de dénominations
- Une communication insuffisante auprès du grand public
- Comment faire connaître le métier du test ?
Quels prérequis pour devenir QA ?
Le métier du test est un métier complexe et passionnant, et peu de prérequis sont strictement exigés. Outre un goût pour l’informatique et le travail d’équipe, il est toutefois souhaitable d’avoir quelques-unes des qualités ci-dessous :
- Rigueur
- Curiosité
- Adaptabilité
- Aisance relationnelle
- Diplomatie
- Humilité
- Assertivité…
- Goût pour l’apprentissage continu
- Aisance rédactionnelle
Le contexte est important et les compétences et qualités requises dépendront d’un environnement à l’autre !
Pour vous épanouir dans cette carrière, il est avant tout important… d’en avoir envie ! A noter tout de même que beaucoup de QA le sont devenus « par hasard » et ne le regrettent pas. Ce choix de carrière est tout à fait pertinent dans une démarche de reconversion. Un passé dans la biologie, la comptabilité, l’enseignement, la traduction… ne peut être qu’un atout dans ce métier. Premièrement, parce que votre expertise peut vous être directement utile (connaissance fonctionnelle de l’applicatif à tester). Deuxièmement, parce qu’en tant qu’« outsider », vous porterez un regard neuf sur les process, les produits et tout ce qui gravite autour. Et cette prise de recul est bénéfique à toute entreprise !
Quelles sont les tâches des QA ?
Mais tout d’abord, à quoi faut-il s’attendre quand on candidate à un poste de QA ? Cette section s’adresse à tous les curieux de test logiciel qui sont attirés par cette activité et souhaitent savoir, concrètement, ce à quoi s’adonnent les QA.
Il faut garder à l’esprit le fait que l’activité de test varie d’une entreprise à l’autre, en fonction du type de projet, du mode de développement, du domaine métier et d’autres facteurs encore.
Voici tout de même une liste de quelques tâches qui brossent, dans les grandes lignes, un schéma grossier du quotidien d’un grand nombre de QA.
L’exécution des tests manuels à partir d’un référentiel de tests
L’exécution des tests est la partie la plus visible de l’iceberg du test. Selon les cas, elle représente 0 à 99% du temps de travail. Vous avez bien lu : 0%. C’est la première idée reçue à combattre sur le métier : on ne passe pas notre temps à cliquer machinalement sur des boutons en suivant minutieusement d’austères modes opératoires.
Quoi qu’il en soit ; quand cela se présente, les QA se trouvent devant une fiche de test (ou, bien plus souvent, devant un outil de gestion des tests) qui détaille un scénario de test à exécuter. Un scénario de test décrit d’une part les actions à réaliser, d’autre part les vérifications à effectuer.
Un exemple de cas de test : « Se rendre sur la page d’accueil et cliquer sur le bouton « En savoir plus ». Une popup doit s’ouvrir, dont le contenu doit être défilable verticalement mais pas horizontalement. »
Les QA lisent la fiche de test et exécutent le scénario indiqué. Si le logiciel fait ce qui est demandé, on signale et passe au test suivant. Sinon, on rédige un rapport d’anomalie en respectant le format en vigueur dans son organisation.
Le risque de s’ennuyer existe, car les tests sont souvent répétitifs. Mais il faudra plus que de la patience pour exceller en tant que QA : il faudra faire en sorte de toujours tester comme si c’était la première fois !
Si vous débutez, il est possible qu’on vous demande de suivre à la lettre les scénarios de tests du référentiel. Cependant, si le contexte vous le permet, n’hésitez pas à sortir des scénarios indiqués pour faire des tests en complément. Au fur et à mesure, vous allez « flairer » les bugs de mieux en mieux ! L’exécution des cas de tests est une activité qui peut être fastidieuse, mais qui sera d’autant plus efficace que vous vous autoriserez à être créatif.
La conception des tests
La conception des tests est l’activité qui permet de construire le référentiel de tests, qui est utilisé pendant l’exécution des tests.
A partir d’un cahier des charges ou de tout autre document décrivant comment un logiciel devra fonctionner, on imagine des scénarios à exécuter. La rédaction de cas de test est bien souvent outillée, de manière à améliorer la productivité de cette activité.
Les QA, pendant la conception des tests, doivent garder à l’esprit le fait que le temps alloué à l’exécution des tests est limité. Il doit donc cibler l’effort de test sur les fonctionnalités qui demandent le plus de test. Cela nécessite d’avoir une vue d’ensemble sur le logiciel à tester, et de définir, seul ou le plus souvent en équipe, une véritable stratégie de test.
La gestion des anomalies
Ce n’est pas tout de créer des rapports d’anomalies ; il faut aussi faire en sorte que les bugs soient corrigés. Les QA ne corrigent pas les bugs ; il doit donc les prioriser, les rendre faciles à reproduire, bref orchestrer au mieux le travail de correction. Ce travail se fait souvent en bonne intelligence avec d’autres acteurs du projet.
La gestion des anomalies est un travail effectué tout au long d’un projet ; la criticité, la priorité et les étapes de reproduction d’un bug peuvent évoluer au fil du temps. Il est important d’avoir toujours des informations fiables sur la qualité du logiciel.
Les QA doivent donner une visibilité des anomalies ouvertes. Il s’agit de créer notamment des rapports indiquant les informations importantes sur le nombre et la nature des anomalies ouvertes. Ces rapports sont très importants, car ils permettent de prendre des décisions impactant la vie du projet (changement de priorités, décalage de la mise en production du logiciel).
Les tests exploratoires
On parlait précédemment de l’exécution des tests à partir d’un référentiel. Sachez qu’un référentiel formel de tests n’est pas toujours utilisé, et que la conception des tests a parfois lieu… en même temps que l’exécution ! On parle alors de test exploratoire, qui représente un sous-ensemble important de méthodes de test. Ces pratiques permettent de sonder les produits en profondeur en se basant sur des hypothèses et problématiques spécifiques (exemple : « nos utilisateurs se plaignent du moteur de recherche ; passons 40 minutes à explorer à fond cette fonctionnalité »).
L’automatisation des tests
Ah, là on s’attaque à un gros morceau !
Jouer les tests à la main encore et encore, ça a un coût et ça prend du temps. En tant que QA, il vous sera peut-être (probablement !) demandé d’automatiser une partie de vos tests.
Concrètement, vous allez écrire des scripts qui, une fois lancés, vont simuler le scénario utilisateur au sein du logiciel à tester. Un petit exemple en vidéo ?
Cela demande encore une fois de mettre en place une stratégie : on ne peut pas tout automatiser. Pour cette activité, on vous demandera certainement des compétences techniques (souvent, des connaissances en développement orienté objet). Vous devrez aussi faire preuve d’esprit critique afin de mettre au mieux à profit ce temps d’automatisation.
Conseil : pour avoir bien en tête les tenants et les aboutissants de l’automatisation des tests, n’hésitez pas à parcourir cette ressource, qui a vocation à fournir un tour d’horizon assez complet sur le sujet.
En bref : un métier polyvalent
Bien d’autres activités encore pourraient être évoquées. Le métier de QA est un métier largement polyvalent. Vous aurez parfois l’opportunité d’inventer, de modeler votre poste selon les besoins en qualité que vous identifierez. L’esprit d’initiative sera valorisé, et il vous faudra développer vous-mêmes des stratégies, des tactiques et des astuces pour vous adapter à un grand nombre de situations ! Cela sera d’autant plus vrai dans les équipes agiles.
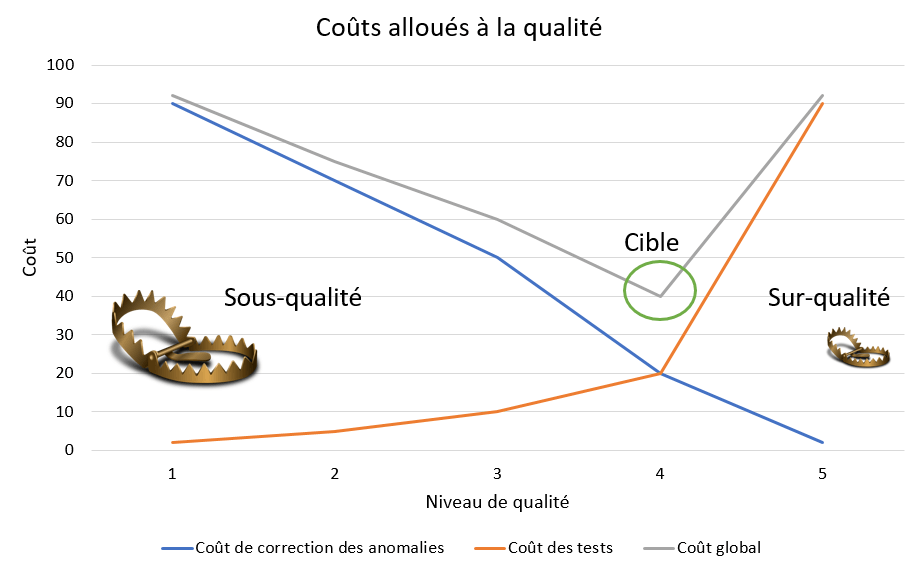
Ci-dessous, à titre d’exemple, voici la répartition du temps d’un QA sur une de nos dernières missions. Ce n’est pas un exemple à suivre absolument, simplement une illustration parmi d’autres de ce qu’il est possible de vivre dans le monde du test.
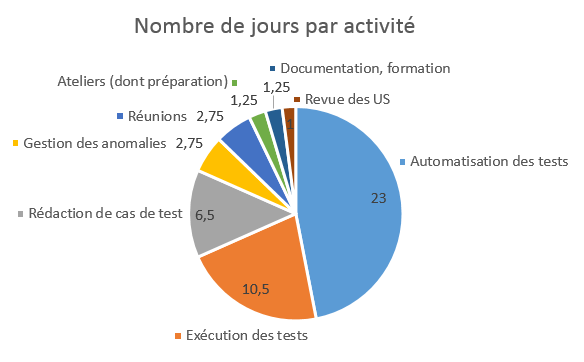
Pour finir, rien de tel que d’échanger avec d’autres QA pour se rendre compte des multiples facettes du métier ! Et pour ce faire, nous conseillons de rejoindre le groupe LinkedIn « Le métier du test ».
Les outils des QA
C’est une question récurrente, surtout de la part des étudiants. Pour maîtriser le métier du test, il est important d’en maîtriser les outils principaux. Toutefois, nul besoin de suivre tous les cours en ligne de tous les outils de test les plus utilisés ! Maîtriser un outil de chaque type vous donnera suffisamment d’aisance pour pouvoir évoluer et en maîtriser d’autres par la suite.
Les outils de gestion des tests
Peut-on organiser une campagne de test sur un fichier Excel ? Ce n’est sans doute pas impossible, mais nous conseillons d’utiliser plutôt un outil optimisé pour cet usage. Les outils de gestion des tests permettent de concevoir les tests, de les rédiger, de les maintenir, d’organiser les campagnes de test (qui fait quoi ?), de suivre les résultats de celles-ci et, souvent, de générer des rapports.
Chez Hightest, nous sommes fans de Squash TM, un outil français (cocorico !), open source et simple d’utilisation. Si vous découvrez l’outil, nous vous conseillons de vous penchez sur ces quelques bonnes pratiques.
Les outils d’automatisation des tests
Difficile de citer ne serait-ce que tous les différents types de tests qui peuvent être automatisés ! Toutefois, lorsqu’on parle de « tests automatisés », il est souvent question de tests fonctionnels dynamiques automatisés ; c’est-à-dire d’automates qui vont parcourir l’applicatif comme s’ils étaient des utilisateurs, réaliser des parcours clients, vérifier ce qui est affichés sur l’écran à l’issue d’une transaction, etc.
Il existe cependant beaucoup d’autres outils de tests automatiques : des scans de vulnérabilité, des outils de scripting de tests de performance, de charge, de stress, des outils permettant d’identifier les problèmes d’accessibilité, des plateformes permettant de mesurer la qualité d’un code source…
Chez Hightest, nous utilisons toutes sortes d’outils de tests automatisés ; cela dépend notamment du contexte, du besoin et des acteurs impliqués dans la démarche d’automatisation des tests.
Bien que l’ensemble des QA ne fassent pas d’automatisation, nous ne pouvons que vous encourager à découvrir cette importante facette du métier.
Les outils transverses
Beaucoup d’outils qui ne sont pas spécifiquement des outils de test pourront vous être utiles. Pensez à toutes les tâches transverses que vous devrez effectuer :
- reporting
- brainstorming
- rédaction, synthèses
- communication interne, voire externe
- gestion du temps, gestion de la productivité
- prise de notes
Nous vous invitons à rester en veille sur les outils transverses (notamment les plugins de navigateur si vous testez des sites web) qui pourraient vous aider dans vos multiples tâches de QA.
Et surtout…
Un seul outil vous manque, et tous les autres ne servent à rien. Il s’agit d’un freeware que tout le monde a sur soi ! C’est notre capacité d’attention et de réflexion. Si vous abordez chaque projet de test avec un regard neuf, que vous posez toutes les questions qui vous viennent, et que vous gardez toujours à l’esprit les enjeux réels de votre activité de test, vous aurez avec vous le meilleur outil de la place.
Les formations
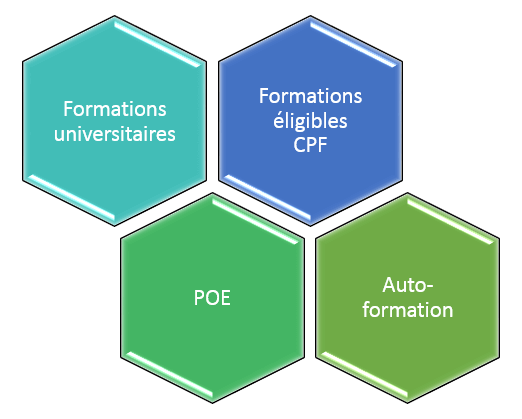
Si les activités que nous avons citées vous ont fait envie, voici quelques pistes pour vous préparer avant de candidater à un poste de QA junior.
Les formations universitaires
Il est important de noter qu’à l’heure actuelle, sur le territoire français, l’offre de formation universitaire en test logicielle est peu fournie.
Licence professionnelle Test et Qualité Logicielle (LP-TQL)
Proposée par l’IUT de Laval, cette formation est accessible à niveau bac +2 (filières informatiques ou scientifiques), en formation initiale, continue ou VAE. Elle existe depuis 2009 et accueille 28 étudiants par an. Classiquement, à l’issue de cette formation, les personnes l’ayant suivie rejoignent le monde du travail sans besoin de passer par la case master.
16 semaines de stages sont obligatoires (+ 150 heures de projet tuteuré), à moins que vous ne choisissiez d’augmenter ce nombre en optant pour l’alternance.
Quelques outils étudiés : Selenium, Jenkins, MaTeLo, TestLink, JavaUnit, PHPUnit, Squash, Android Studio. La formation comprend un passage de la certification ISTQB de niveau Fondation.
Voir la présentation de ce cursus.
Merci à Lahcen Ouhbassi, responsable de cette formation, d’avoir répondu à nos questions.
Master Ingénierie du Test et de la Validation Logiciels et Systèmes (ITVL)
Le master ITVL, proposé par Polytech Angers (anciennement ISTIA) en collaboration avec l’Université de Franche-Comté, offre un cursus de deux ans comprenant un stage de 6 mois, 50 heures de projet et le passage de plusieurs certifications reconnues (dont ISTQB et IREB).
Ce master est ouvert uniquement en formation continue. Il se déroule 75% à distance et 25% en présentiel, à Angers. Les promotions oscillent pour l’instant entre 8 et 10 personnes par promotion, mais la formation pourrait à l’avenir accueillir davantage de personnes (pour un total de 16 à 18 étudiants). La formation en est à sa troisième promotion en 2019, et à ce jour le taux d’obtention du diplôme est de 100 %. A l’issue de cette formation, la très grande majorité des personnes ont obtenu des évolutions importantes de poste, soit dans la même entreprise, soit dans une autre entreprise. Deux personnes ayant suivi la formation se sont mises à leur compte.
Pour ce qui est du processus d’entrée, les responsables de la formation organisent un entretien individuel pour comprendre les motivations du projet professionnel du candidat ainsi que ses compétences, son expérience métier et son niveau d’études – en relation ou non avec le métier. L’éventuelle prise en charge financière par l’entreprise est également évoquée, de même que l’organisation de cette formation et le travail à fournir pendant les 2 années. Suite à cet entretien, les responsables de la formation expriment leur avis sur cette candidature et la personne postule ou non à la formation.
Merci à Alexis Todoskoff, responsable de cette formation, de nous avoir communiqué ces éléments.
Ecole Française du Test Logiciel et de la Cybersécurité (EFTL-CYBER)
Cette école se situe à Rennes et propose 3 formations autour de la qualité logicielle :
Autres formations
Le site de l’association QTL-Sup mentionne quelques autres formations ; voir cette liste.
Les formations éligibles au CPF
Si vous êtes en poste, il vous est peut-être possible d’utiliser votre CPF pour bénéficier d’une formation au test logiciel. Si celle-ci prépare à passer la certification ISTQB de niveau Fondation, cela pourra donner un vrai plus à votre CV. En tant que QA qui débute, vous devez savoir que les certifications ISTQB, s’ils ne sont pas obligatoires pour trouver un emploi, sont tout de même une excellente manière de montrer patte blanche dans le monde du test ! Si vous souhaitez vous faire une idée du type de questions du test ISTQB de niveau Fondation, vous pouvez faire dès à présent notre test en ligne.
Comme elles sont assez nombreuses et que leur liste est amenée à fluctuer, nous ne listerons pas ici l’ensemble des établissements proposant ces formations.
La POE
La POE (Préparation Opérationnelle à l’Emploi, aussi appelée POEIC pour « individuelle et collective ») est un dispositif permettant d’acquérir une formation professionnalisante avec un emploi à la clé. Elle est particulièrement intéressante pour les entreprises recherchant des profils rares, et les QA avec de l’expérience sont en effet très recherchés.
Acial notamment propose des parcours de POE qui permettent d’acquérir les fondamentaux du test logiciel en 10 semaines, pour devenir ensuite consultant dans ce domaine. Deux parcours sont disponibles : un parcours axé sur l’automatisation et un autre parcours plus généraliste.
L’auto-formation
Des MOOCs en français sur le test logiciel ? Il y en a quelques-uns sur la plateform OpenClassroms, notamment :
Deux autres cours sur le sujet devraient être disponibles à l’été 2019 : « Testez en continu avec Jenkins » et « Testez vos fonctionnalités avec Selenium et Python ».
Des MOOCs en anglais abondent également sur plusieurs plateformes.
Pensez aussi à Test Automation University, une plateforme qui contient notamment des cours débutants en automatisation. Si vous partez de zéro, ce site vous aidera à acquérir de précieuses notions ! Pour en savoir plus, jetez un oeil à l’article que nous avons écrit sur cette plateforme.
A noter qu’il est possible, pour les très débrouillards, de passer la certification ISTQB en candidat libre pour 250 euros (prix pour un passage en France métropolitaine). Voir la liste des prochaines sessions. Il est également possible de passer l’examen en distanciel.
Un autre axe, non certifiant, mais qui permet de faire un premier pas dans le métier, est le crowdtesting. Même si cela ne vous occupera pas forcément à plein temps, l’expérience acquise peut être très riche et valorisante. Vous serez en contact avec un nombre important d’applications dans des domaines différents, ce qui représente autant d’opportunités de monter en compétences. Nous avons créé une plateforme de crowdtesting nommée Testeum, qui vous permettra, si cela vous intéresse, de découvrir cette activité.
Premier entretien !
Votre formation va bientôt s’achever et votre premier entretien d’embauche pour devenir QA se profile ? Nous vous recommandons de jeter un œil à l’article que nous avons dédié à ce grand moment ! On croise les doigts pour vous 🍀
Pourquoi le métier de QA est-il si peu connu ?
Nous espérons que cet article a pu permettre à certains d’avoir une idée plus précise sur le métier. Avant de se quitter, nous proposons de se pencher sur le problème de fond qui a mené à cet article : la méconnaissance importante dont souffre le métier de QA.
Une famille de métiers, une multitude de dénominations
Le métier de QA ne cesse de se développer et de se spécialiser, ce qui conduit à une diversification des dénominations, comme l’explique cet article de la Taverne du Testeur.
Cependant, selon nous, ce phénomène n’explique qu’une petite partie du problème.
Une communication insuffisante auprès du grand public
En effet, un nombre important de sources d’informations grand public donne une vision parcellaire voire erronée du métier de QA.
A titre d’exemple, la nomenclature 2018 du Cigref (EDIT : celle de 2021 aussi !) réserve le métier de QA aux « Bac + 2 (BTS ou DUT) » ou aux « ingénieurs débutants », avec comme possibilités d’évolution une bifurcation vers les « fonctions études » ou la maîtrise d’ouvrage. L’automatisation des tests n’est pas mentionnée, ni les multiples spécialisations possibles dans le domaine de la qualité (test management, test de performance, test de sécurité, UX, SDET…). Vu comme ça, le métier peut donc ressembler à une « seconde chance » pour ingénieurs médiocres, en attente de trouver mieux. Quel dommage de réduire le métier à cela !
Le site « Etudiant » du Parisien relève-t-il le niveau ? Un petit peu, même si dès la première phrase, on grince un peu des dents : « Le testeur repère et relève les anomalies et bugs présents dans un logiciel ou une application avant sa publication. » La partie la plus intéressante n’apparaît qu’en troisième dans la liste des activités qui incombent aux QA : « Établir une tactique opérationnelle, créer des outils de test et d’analyse des résultats trouvés, dans le but de rédiger des bilans précis des logiciels étudiés. »
En 2019, le site de l’Apec ne mentionnait tout simplement pas le métier de QA dans sa liste des fiches métier de l’informatique, même si on le retrouvait en filigrane sur les pages « Consultant maîtrise d’ouvrage », « Responsable de la maîtrise d’ouvrage bancaire / MOA » et « Ingénieur qualité/méthodes (informatique) ».
En 2021, ça y est, on trouve une fiche dédiée ! Celle-ci ne mentionne pas encore l’automatisation à proprement parler, mais rend tout de même justice à la polyvalence du métier, alors merci à l’Apec.
Comment faire connaître le métier du test ?
Nous espérons sincèrement que le métier deviendra plus connu grâce aux efforts de la communauté du test francophone. Les différents groupes, meetups, événements et blogs existants pourront sans doute faire rayonner le métier à leur échelle.
L’apparition de personnages de QA dans la culture populaire pourrait également mettre notre métier sous le feu des projecteurs (comme c’est largement le cas pour les métiers de développeur et d’administrateur système !) Un grand nombre de métiers sont entourés d’un imaginaire épique et enthousiasmant ; et si c’était notre tour ?