Un avis ? Un commentaire ?
Cet espace est pour vous.


Il est vrai, rien ne surpasse les id dans les techniques d’identification des objets dans un DOM. C’est le plus simple et aussi le plus rapide à trouver par Selenium. Mais parfois (souvent) on ne peut pas faire autrement que d’écrire des xPath tellement complexes qu’ils frisent le « write-only ». Ces moments de solitude arrivent souvent lorsqu’on interagit avec des tableaux. On met 10 minutes à trouver la bonne formule et deux semaines après on ne s’en souvient plus. Nous voulons que ce temps soit révolu !
Voici donc 8 défis pour vous entraîner à écrire des xPath pour attraper des éléments dans des tableaux.
Les réponses se trouvent en bas de l’article.
Pour vérifier vos réponses nous vous conseillons l’outil CSS and XPath checker.
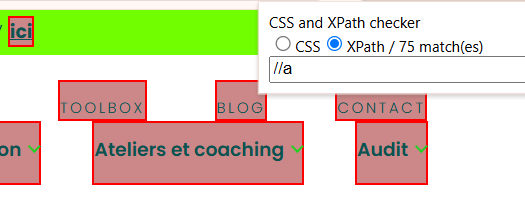
Toutefois, si vous ne souhaitez pas installer d’extension de navigateur (ou que vous n’avez pas le droit de le faire pour des raisons de sécurité !) il est tout à fait possible de se débrouiller autrement !
Sur votre navigateur, ouvrez l’inspecteur (touche F12 sur la plupart des navigateurs, ou « Option + Commande + I » sur Mac + Safari).
Ensuite, trouvez le bouton en forme de curseur, cliquez dessus, puis cliquer sur l’élément de la page dont vous souhaitez étudier le code source.
Pour écrire un xPath, nul besoin de retracer toute l’arborescence menant à l’élément en question ! Au contraire, plus votre xPath sera court et lisible, mieux ce sera pour la maintenance.
Voici quelques exemples d’xPath portant sur des liens (syntaxe « a » en HTML, en tant que diminutif de « anchor »).
Ce ne sont là que des fondamentaux, l’exercice ci-dessous est un peu plus corsé ! 😁
Dans cet exercice, nous nous baserons sur ce tableau fruité. Vous pourrez valider vous-mêmes les formules sur la présente page.
| Fruit | Description | Prix au kilo (XPF) |
|---|---|---|
| Pomme-liane | Un feu d’artifice de saveurs acidulées | 700 |
| Banane poingo | Le compromis entre la patate et la banane | 500 |
| Pomme-cannelle | De loin, ressemble à un artichaut | 630 |
| Letchi | Ce n’est plus la saison | 700 |
| Noix de coco | Son germe est délicieux | 350 |
| Chouchoute | Oups, ce n’est pas un fruit | 300 |
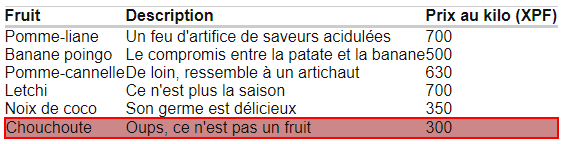
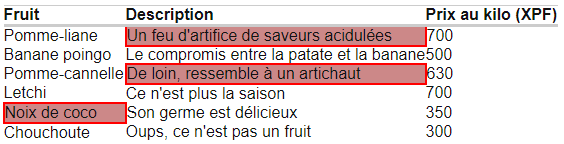
Sous chaque question se trouve une copie d’écran du tableau avec le résultat attendu en surbrillance.
1) Ecrire un xPath pour récupérer la deuxième cellule qui contient « Pomme ».

2) Ecrire un xPath pour récupérer la première case des lignes dont la colonne 3 contient la chaîne 700.
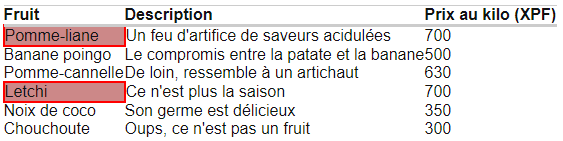
3) Ecrire un xPath pour récupérer la deuxième case après les cellules contenant « Pomme-cannelle ».

4) Ecrire un xPath pour récupérer les cases qui contiennent des prix entre 300 (inclus) et 630 (exclu).

5) En hommage à Georges Perec, écrire un xPath pour récupérer les cases qui ne contiennent pas de « e » minuscule (cases de l’entête du tableau comprises).

6) Ecrire un xPath pour récupérer les lignes qui contiennent une case dont le texte commence par « Oups ».
7) Ecrire un xPath pour récupérer les cellules du tableau (hors entête) qui contiennent la chaîne « de », qu’elle soit en minuscules ou en majuscules.
8) Allez, un bien compliqué pour finir. Ecrire un xPath pour récupérer les noms des fruits dont la description contient le texte « est » et dont le prix est entre 300 (inclus) et 630 (exclu).

Alors, combien d’exercices avez-vous réussi à faire ? 😀
Attention, même s’il est préférable d’avoir des sélecteurs simples à comprendre, ne faites pas reposer la lisibilité de votre projet d’automatisation sur la lisibilité de vos sélecteurs. Envisagez l’adoption de l’objet Selecteur tel que nous détaillions dans notre article sur la lisibilité des logs Selenium :
public class Selecteur {
public String nom;
public By chemin;
public Selecteur(String nom, By chemin){
this.nom = nom;
this.chemin = chemin;
}
public String getNom(){
return nom;
}
public By getChemin(){
return chemin;
}
}
Avec comme exemple d’application :
protected void clickElementTableau(int ligne, int colonne) {
Selecteur cellule = new Selecteur("la cellule située sur la ligne " + ligne + " et la colonne " + colonne + " du tableau", By.xpath("//tr[" + ligne + "]/td[" + colonne + "]"));
logger.info("Clic sur " + cellule.getNom());
driver.findElement(cellule.getChemin()).click();
}
En sortie, vous aurez des logs en langage naturel, par exemple : « Clic sur la cellule située sur la ligne 3 et la colonne 4 du tableau ».
Il existe souvent plusieurs solutions possibles, celles ci-dessous ne sont que des possibilités.
1. Un xPath pour récupérer la deuxième cellule qui contient « Pomme » :
(//td[contains(., 'Pomme')])[2]
2. Un xPath pour récupérer la première case des lignes dont la colonne 3 contient la chaîne 700 :
//td[3][contains(., '700')]//../td[1]
3. Un xPath pour récupérer la deuxième case après la cellule qui contient « Pomme-cannelle » :
//td[contains(., 'Pomme-cannelle')]/following-sibling::td[2]
4. Un xPath pour récupérer les cases qui contiennent des prix entre 300 (inclus) et 630 (exclu) :
//td[. >= 300 and 630 > .]
5. Un xPath pour récupérer les cases qui ne contiennent pas de « e » minuscule (cases de l’entête du tableau comprises) :
//td[not(contains(., 'e'))] | //th[not(contains(., 'e'))]
6. Un xPath pour récupérer les lignes qui contiennent une case dont le texte commence par « Oups » :
//td[starts-with(., 'Oups')]/parent::tr
7. Un xPath pour récupérer les cellules du tableau (hors entête) qui contiennent la chaîne « de », qu’elle soit en minuscules ou en majuscules :
//td[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'), 'de')]
Conseil : si possible encapsuler cette transformation de casse dans une fonction.
8. Un xPath pour récupérer les noms des fruits dont la description contient le texte « est » et dont le prix est entre 300 (inclus) et 630 (exclu).
//td[. >= 300 and 630 > .]/preceding-sibling::td[contains(., 'est')]/preceding-sibling::td
Mise à jour du 24 juin 2019 : nous avons découvert, grâce à une personne sur le Slack de la Test Automation University, un exercice en ligne pour s’entraîner à écrire des sélecteurs CSS. Un petit jeu interactif réjouissant et très bien fait : découvrez CSS Diner !
Cet espace est pour vous.