

Nous avons le plaisir de vous dire que cet article a été écrit à quatre mains, avec Brice Roselier. Expérimenté en test, il a mis en place des KPI afin de suivre la progression de la qualité des activités de test dans son contexte.
Comment communiquer sur la qualité des tests ? Quels indicateurs de performance produire ? Comment suivre l’évolution de ces indicateurs ? Nous abordons ces questions pour faire suite aux deux derniers articles, portant respectivement sur l’organisation du contrôle des tests et sur l’auto-évaluation de la qualité des tests.
Voilà en tous cas une épineuse question, et le sujet devient d’autant plus glissant lorsqu’il est motivé par des problématiques d’intéressement. Il a donné lieu à un passionnant débat il y a quelques mois sur LinkedIn, dans le groupe « Le métier du test » (si vous n’y êtes pas encore, c’est vraiment le moment de le rejoindre, ça représente plus de 3900 testeurs passionnés !).
Articles de la série :
- Organiser le contrôle des tests logiciels
- Auto-évaluer la qualité de ses tests
- L’épineuse question des KPI
Les métriques de la mort
Avant toute chose, et avant que vous ne fermiez cet onglet parce que votre collègue vous appelle sur un sujet plus urgent, voici une liste de KPI à ne jamais, jamais, jamais envisager. S’il vous plaît. Please. Por favor.
Le nombre de bugs créés
Vous voulez vraiment vous retrouver avec un gros paquet de bugs doublonneux ? Ou vous retrouver dans une situation horriblement paradoxale, où les testeurs auraient envie que l’application soit de mauvaise qualité…
Le nombre de cas de test écrits
Un référentiel de tests c’est comme une maison : tu peux y ajouter des objets, mais tu dois aussi te débarrasser de ceux qui t’encombrent et ne te servent à rien, lutter contre la poussière et ranger le mieux que tu peux.
Le nombre de scripts de tests automatisés
Bonjour la maintenance si vous optez pour ce KPI. C’est comme si un développeur était rémunéré à la ligne de code…
La durée des tests
« Nous visons à réaliser des campagnes de test qui durent moins de 8 heures. »
Quelle belle résolution, et quelle tentation de créer un KPI associé vu qu’il y a 3 semaines on a même tout bouclé en 7 heures. Hélas, encore une fois on se retrouve dans un champ de peaux de bananes. Les activités de test sont largement impactées par la qualité constatée de l’application à tester.
Comme le souligne Gerald M. Weinberg dans Perfect Software, and other illusions about testing (2008), si les testeurs trouvent un grand nombre de bugs et passent du temps à les analyser, l’avancement de leur campagne sera nécessairement ralenti. Pour autant, sans analyse, la plupart des rapports de bugs ne sont que de médiocres ânonnements.
Toutes les métriques citées sont intéressantes lorsqu’elles sont contextualisées, mais ne devraient pas être utilisées comme KPI au risque de se retrouver à faire de la « gonflette ». Comme le dit un de nos amis développeurs de Nouvelle-Calédonie, « No disco muscle boy, we want strength! »
Quelques prudentes suggestions
De manière générale, les KPI sont à définir en bonne intelligence avec les autres membres de l’équipe. Il faut en premier lieu garder en tête la grande différence qui existe entre une simple métrique et un véritable KPI, qui peut être une métrique à laquelle on attribue une valeur de performance, ou un ensemble de métriques consolidées.
Et de même qu’on distingue la notion de « Créer un produit bien fait » et de « Créer le bon produit », on peut distinguer d’une part la notion « Faire bien les tests » et « Faire les bons tests ».
Quelques pistes peuvent être réfléchies ensemble :
- Les bugs non trouvés dans l’environnement de test, et qui sont remontés par des utilisateurs en production
- Ça fait mal. Il faudrait aussi pouvoir s’assurer que le bug pouvait effectivement être trouvé en environnement de test. Ce n’est malheureusement pas toujours le cas… Ce KPI pourrait être remonté sous forme de ratio ou de valeur absolue, et être qualifié par exemple par le niveau de criticité du bug.
- Avec ce KPI, on vérifie qu’on « fait les bons tests ».
- La qualité des rapports d’anomalie
- Toute la difficulté sera d’établir des critères objectifs et de trouver le meilleur moyen de mettre en place cette évaluation. Sera-t-elle attribuée par un représentant de l’équipe de développement ? Par un collège de développeurs ? Par le team leader des testeurs ?
- Avec ce KPI, on vérifie qu’on « fait bien les tests ».
- Le ratio de tests de régression d’importance haute automatisés versus non automatisés
- Il est un peu moins facile de « tricher » avec ce chiffre, mais encore une fois attention à la gonflette…
- Avec ce KPI, on vérifie également qu’on « fait bien les tests ».
Ce ne sont là que quelques exemples assez génériques, la définition des KPI devant prendre en compte les caractéristiques du produit, du projet et de l’équipe. Un grand sage disait : « Les tests dépendent du contexte »…
Suivre ses KPI à la trace
Une fois en place, les KPI doivent être suivis et exploités, c’est d’ailleurs tout leur intérêt. Pour des raisons de simplicité, cherchez à automatiser la relevée de vos KPI, de façon à les mettre à jour simplement et rapidement. En effet, pour suivre vos KPI, ceux-ci devront être régulièrement mis à jour. Le faire manuellement est à la fois un risque d’erreur, chronophage et surtout peu réjouissant !
Une fois que les KPI donnent une valeur, idéalement de façon automatique, vous devez vous en servir pour progresser. Posez-vous la question sur la façon dont vous exploitez les données brutes (les indicateurs), c’est-à-dire les unités de mesure et leur contexte. Par exemple, si votre KPI se base sur une charge en jours-hommes, est-ce que cette valeur représente le sprint en cours, la release, toute la période depuis le début du projet, ou bien le mois en cours, depuis le début de l’année ou même une période glissante (les 12 derniers mois) ? Il y a plusieurs moyens de faire parler vos indicateurs qui sont la matière première de vos KPI.
Ensuite, fixez-vous des objectifs, SMART de préférence, de façon à voir vos KPI embellir avec l’âge. Un objectif SMART est, comme l’indique cet acronyme, Spécifique, Mesurable, Acceptable (à la fois Ambitieux et Atteignable), Réaliste et Temporellement défini.
Je doute que le simple affichage de vos KPI ne vous satisfasse. Ces valeurs, vous voulez les voir évoluer car elles traduiront un progrès (ou pas) de votre processus de test et/ou de votre équipe. Pour cela, fixez-vous une valeur légèrement meilleure, et tentez de l’atteindre dans un délai relativement court. Cela vous donnera une idée de ce à quoi vous pouvez prétendre. Enfin, si vous souhaitez améliorer votre KPI sur la durée, planifiez un plan de progrès sur une période (par exemple augmenter la valeur de votre KPI de 10% en un an) avec des jalons intermédiaires qui vous mèneront à votre objectif.
Quelques exemples d’indicateurs et KPI
Dans un premier temps, listez les indicateurs que vous souhaitez suivre et réfléchissez à la manière dont vous allez les alimenter. A partir de là, alimentez vos indicateurs et KPI progressivement. Le piège étant, comme dit plus haut, qu’un indicateur puisse s’exprimer de plusieurs façons.
Tout le monde le sait, à court terme, le test est une charge qui augmente le budget d’un projet. Vous devez donc chercher à améliorer le ratio entre la qualité apportée par les tests et l’énergie à fournir pour atteindre ce résultat. Un peu à l’image d’un compte-tours, plus la vitesse est élevée et moins le moteur tourne rapidement, plus il est efficace.
A ce stade, c’est bien l’efficacité des tests que l’on souhaite mesurer et non la qualité intrinsèque de l’objet de test. Le tout étant de faire vivre les indicateurs et KPI dans le temps et chercher à améliorer le processus de test.
A titre d’exemple, voici ci-dessous la liste de quelques indicateurs que Brice suit chez lui.
Indicateurs liés aux anomalies
KPI associés :
~ Anomalies détectées et confirmées / Anomalies non détectées
~ Anomalies corrigées / Anomalies non résolues
- Anomalie non détectée (faux négatif) : un classique de chez classique. Ce sont les anomalies qui passent entre les mailles du filet. L’utilisateur remonte une ano que le test n’a pas vu. On le mesure sous forme de coefficient qui représente la somme du nombre d’anomalies pondéré par leur criticité (on peut imaginer un barème 1, 3 et 20 pour mineur, majeur, bloquant). Pour aller plus loin vous pouvez même chercher à mesurer la quantité d’utilisateurs concernés par ces faux négatifs.
- Anomalies détectées et confirmées : on considère que l’anomalie n’est pas un faux positif et qu’elle n’est pas en doublon. Ici on ne se focalise pas sur la criticité, on compte simplement le nombre d’anomalies détectées via un test auto ou manuel.
Exemple de représentation des anomalies détectées :

Ici 2072 anomalies ont été détectées dont 64 critiques, 662 majeures et 1346 mineures.
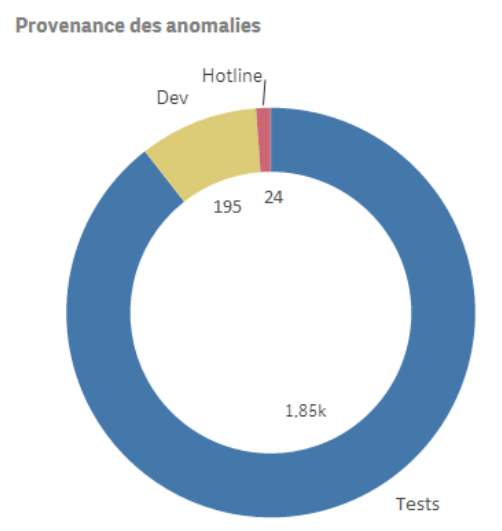
Représentation de graphique représentant la provenance des anomalies détectées :
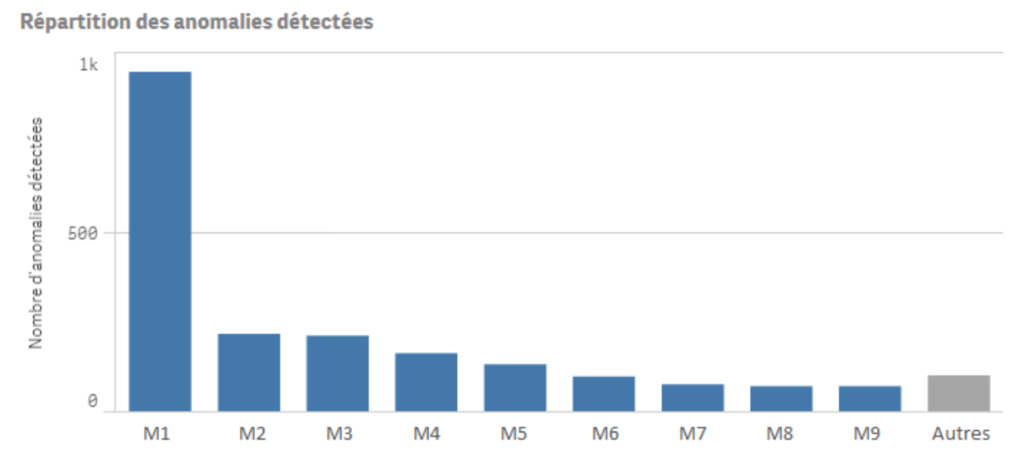
Exemple de graphique représentant la répartition des anomalies détectées par module :
- Anomalies non résolues : ça arrive, ce sont les anomalies peu impactantes que l’on accepte d’avoir en production, car elles sont coûteuses à corriger, liées à un contexte très particulier pour les reproduire et qu’il n’y a pas assez de temps pour les traiter avant la sortie de la version. Cet indicateur permet d’estimer l’effort de correction à court terme et la confiance à la clôture des tests. Comme les faux négatifs, on l’exprime sous forme de coefficient en pondérant la criticité des anomalies. Cet indicateur donne en premier lieu une information sur la qualité du livrable, mais dans un second temps on peut avoir ici un axe d’amélioration du processus de test : les anomalies sont peut-être découvertes trop tard. Cela donne aussi une estimation pour la campagne suivante car les anomalies non résolues donneront lieu à des tests de confirmation.
Exemple de représentation des anomalies non résolues :

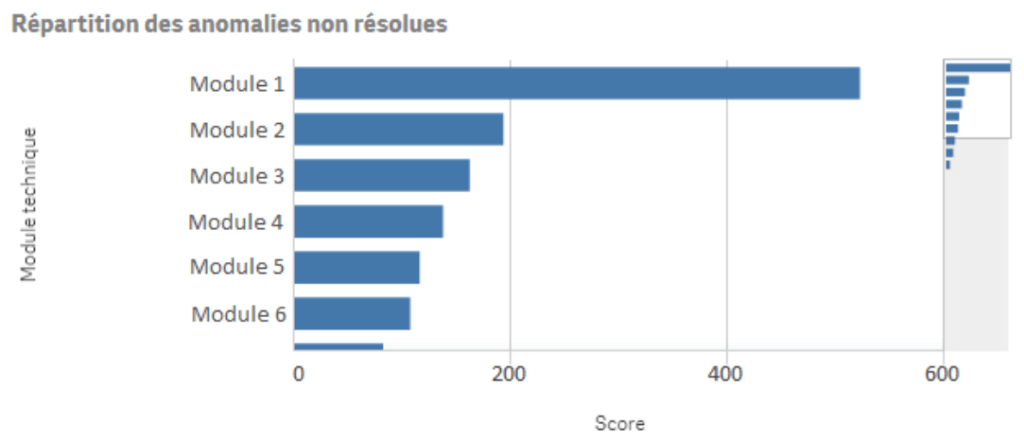
Dans cet exemple, depuis la première version de l’application, 650 anomalies n’ont pas été résolues, dont 16 critiques, 213 majeures et 421 mineures. En affectant un barème de 20 points pour une anomalie critique, 3 points pour une majeure et 1 point pour une mineure cela donne un coefficient global de 1380.
Exemple de graphique représentant la répartition des coefficients des anomalies non résolues :
- Anomalies corrigées : nombre d’anomalies pondérées par leur criticité ayant été corrigées (sous forme de coefficient). Ici on cherche à mesurer l’amélioration de la qualité apportée grâce aux tests.
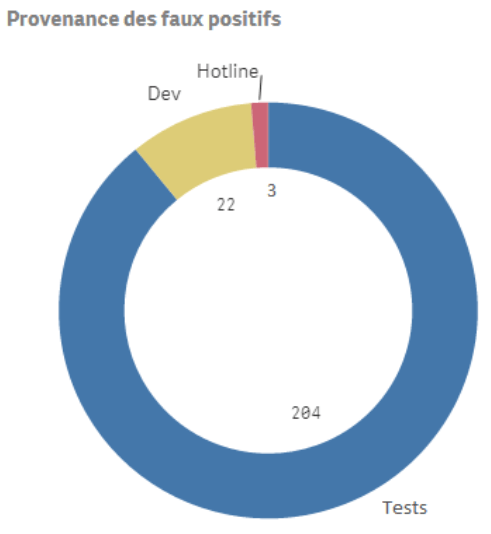
- Faux positifs et doublons : avec cet indicateur, on va chercher à mesurer l’effort de test sans valeur ajoutée. C’est-à-dire ce qui génère du temps passé pour rien. On peut le mesurer sous forme d’entier positif et le mesurer en pourcentage par rapport au nombre d’anomalies détectées. 10 faux positifs sur 20 anomalies c’est beaucoup, pour 1000 anomalies c’est mieux !
Représentation de graphique représentant la provenance des faux positifs :
Indicateurs liés à la complétude des tests
KPI associé :
~ Couverture du code
- Couverture du code : quantité du code exécuté au moins une fois pendant les tests. On cherche à mesurer la profondeur (in)suffisante des tests. On la mesure en pourcentage sur les fichiers, les lignes et les conditions couvertes. Cette couverture peut être calculée avec un outil d’analyse statique tel que SonarQube pour les tests unitaires, mais pas seulement. Chez Brice le code métier est en C, à la compilation peuvent être ajoutées des options pour générer des traces à l’exécution. En manipulant ces traces on peut donc calculer la couverture même sur du test système réalisé en boîte noire.
- Couverture des exigences : mesure la profondeur (in)suffisante des tests et la confiance à la clôture des tests. Cela permet également de prioriser les tests. On l’exprime sous forme de pourcentage, qui correspond au nombre de tests en succès divisé par le nombre de tests rattachés à l’exigence.
Indicateurs liés à la capacité d’exécution des tests
Pas de KPI ici, ce sont des indicateurs fortement influencés par les développeurs et le contexte (si tous les testeurs sont malades, pas de test)
- Quantité d’exécution cumulée : répartie sur chacun des niveaux de tests. On compte le cumul du nombre de fois qu’un test a été exécuté dans sa vie. Cela permet de mesurer la vélocité : le nombre moyen de tests qu’il est possible d’exécuter sur une campagne donnée.
- Nombre de retests : moyenne des aller-retour entre les équipes de test et les développeurs. C’est en quelque sorte le nombre de fois qu’un développeur s’y est repris pour résoudre une anomalie. Derrière, ça veut dire que le testeur va consommer du temps pour retester, requalifier l’anomalie en expliquant pourquoi l’anomalie n’est toujours pas résolue, joindre des impressions d’écran, des logs etc. et quand même retester plus tard. Il faut aussi comprendre pourquoi une anomalie a été difficile à résoudre. La description de l’anomalie n’était peut-être pas claire ou insuffisante (on a trouvé le défaut dans un contexte mais il se retrouve aussi dans d’autres).
- Quantité de régressions : on montre ici le niveau de maturité des tests de bas niveau et la suffisance en termes d’effort de test avant les niveaux supérieurs, mais ce qui nous importe le plus c’est de mesurer l’effort de test sur des articles qui ont été validés avant. On montre l’impact des modifications sur l’activité de test (test, analyse, retest, gestion de l’anomalie…).
Indicateurs liés au patrimoine de tests
Pas de KPI, ce sont des indicateurs sur les tests, pas de quoi soulever la coupe !
- Taux d’automatisation des tests : répartition du nombre de tests automatisés dans le patrimoine. Tout comme le patrimoine, Brice cherche à suivre l’avancement de l’automatisation, ce qui donne une information sur la capacité à tester. Il représente toutefois une charge de maintenance à ne pas oublier (comme un test manuel) ; la qualité de la conception des tests automatisés impactera fortement cet effort de maintenance.
- Tests sans anomalie : sur une campagne ou même sur un laps de temps, combien de tests n’ont trouvé aucune anomalie ? Ils peuvent questionner sur leur capacité à trouver de nouveaux défauts. Ces tests feront l’objet d’une revue à court terme, et seront peut-être obsolètes. On les mesure sous la forme d’un entier positif.
- Volumétrie des tests : cet indicateur mesure quantitativement le patrimoine de test. Il peut être intéressant si aucun test n’est encore formalisé dans un outil. Il peut se mesurer sous la forme d’un entier positif pour chaque type de test (voir diversification des tests).
- Diversification des tests : un petit indicateur qui exprime le nombre de types de tests implémentés dans le patrimoine de test : performance, fonctionnel, accessibilité, validation W3C etc. On l’exprime sous la forme d’un entier positif.
Indicateurs liés aux coûts des tests :
Pas de KPI, mais ces indicateurs sont comme le compte-tours du moteur
- Charge de test : effort du processus de test (manuel et automatisation). Ça représente le coût total (humain) des tests. En d’autres mots, le temps total passé par les équipes sur des activités de test. On l’exprime en jours-hommes (que l’on peut ensuite multiplier par un TJM) et en ETP.
- Charge d’automatisation : effort de test sur la partie automatisation, à savoir l’implémentation des scripts de test, le développement des briques (techniques et fonctionnelles), des étapes et des outils liés à l’automatisation. Cela permet de mesurer le coût d’automatisation des tests. Brice l’a découpée en 5 valeurs (respectivement pour 5 types d’activités dans l’automatisation) exprimées en jours-hommes.
- Coût interne d’une défaillance : c’est la charge de correction d’une anomalie. Cela dépasse le périmètre de tests mais permet de prendre un peu de hauteur en mesurant tout ce qu’une anomalie détectée par l’équipe des testeurs implique dans le service y compris en conception et développement.
- Coût de détection : c’est une extension de la charge de test à laquelle on ajoute les coûts de l’infra, les licences des outils, leur administration, leur maintenance etc.
Bibliographie
Pour clôturer cette série (déjà !), rien que pour vous, voici quelques ressources qui vous aideront à repenser la qualité de vos tests.
- Miserere nobis patrimonium – Ayions pitié de notre patrimoine, un article du wiki Fan de test qui donne encore plus envie de s’y mettre.
- Perfect Software, and other illusions about testing, Gerald M. Weinberg, 2008. Le chapitre 8 (« What makes a good test ? ») détruit les idées reçues sur la qualité des tests.
- Dear Evil Tester, Alan Richardson, 2016. En particulier la partie « What is the most evil metric ? »
- The way of the web tester de Jonathan Rasmusson, 2016. Cet ouvrage contient un grand nombre de bonnes pratiques de développement de tests fonctionnels automatisés (pour applications web). Peut-être pourra-t-il vous servir pour mettre en place en interne vos propres standards !
- Test logiciel en pratique de John Watkins, 2001. Le chapitre 12 est dédié à l’amélioration du processus de test.