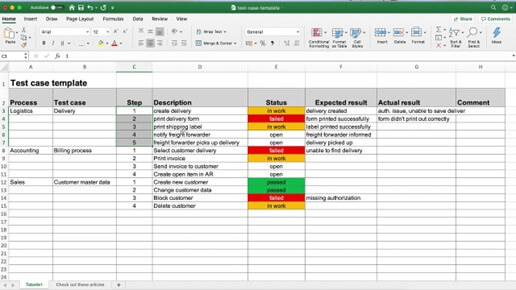
Dans cet article, Christelle Lam, férue de test et en poste chez Hightest depuis 1 an, explique la valeur ajoutée qu’apporte un logiciel de gestion des tests par rapport à un simple fichier Excel. Bonne lecture !
Dans le métier du test, il est fréquent de rencontrer des équipes où le cahier de tests et les rapports d’anomalies se trouvent sur un fichier Excel.
Source : TacticalProjectManager
Pourquoi avoir choisi d’effectuer ce travail à l’aide d’Excel ?
Je pense que bien souvent, c’est par manque de connaissance des logiciels existants très utiles à la gestion de tests.
Un gestionnaire de tests : Quèsaco ?
C’est un logiciel qui permet de gérer le cycle de vie des tests de la création de cas de test, à l’organisation de suites de tests jusqu’à l’exécution des tests, d’assurer la visibilité et la traçabilité des tests et plus si affinités.
Précédemment, nous avons parlé de Squash TM, mais il y en a d’autres comme HP ALM, Azure Test Plans, TestRail, TestLink, Refertest…
Du coup, pourquoi utiliser un gestionnaire de tests plutôt qu’Excel ?
Voici quelques raisons !
Gestion des scénarios de tests
Un gestionnaire de tests offre généralement des fonctionnalités avancées pour la gestion des scénarios de tests tels que la création structurée des scénarios, l’organisation hiérarchique, la gestion des versions, l’assignation des scénarios, le suivi de l’exécution, l’historique des résultats, la génération de rapports, l’intégration avec d’autres outils, automatisation des tests, permettant aux équipes de créer, organiser, exécuter et suivre les résultats de tests de manière plus efficace que ce qui est possible avec Excel.
Collaboration facilitée
Un gestionnaire de tests facilite la collaboration entre les membres de l’équipe de développement et de tests. Il offre souvent des fonctionnalités de partage, de commentaires et de suivi des modifications, ce qui peut être difficile à réaliser de manière efficace avec Excel.
Affectation des cas de test dans Squash TM
Intégration avec d’autres outils
Les gestionnaires de tests sont souvent conçus pour s’intégrer facilement avec d’autres outils de développement tels que les systèmes de gestion de versions, les environnements de développement intégrés et les outils de suivi de problèmes. Cela crée une intégration fluide de processus de développement global.
Génération de rapports de test
Un gestionnaire de tests fournit généralement des fonctionnalités avancées de génération de rapports, permettant aux équipes de tester de manière plus approfondie et de produire des rapports détaillés sur les résultats des tests. Cela peut être plus complexe à réaliser avec Excel.
Source : Squash TM
Réutilisation des scripts de test
Un gestionnaire de tests permet souvent la réutilisation des scripts de test, ce qui signifie que les tests peuvent être adaptés et exécutés à plusieurs reprises sans avoir à tout recréer à partir de zéro, ce qui peut être fastidieux avec Excel.
Gestion des données de test
Un gestionnaire de test peut offrir des fonctionnalités pour gérer efficacement les données de test, par exemple en séparant clairement l’espace de rédaction du scénario de test, et l’espace de déclaration des différentes données de test qui seront utilisées pendant la campagne. Excel ne permet pas cela facilement.
En conclusion, bien qu’Excel puisse être utilisé pour des tâches de base de gestion des tests, les gestionnaires de tests offrent des fonctionnalités plus avancées, une automatisation accrue et une meilleure gestion globale du processus de tests dans des environnements de développement logiciel complexe.
En espérant que cet article t’en a appris un peu plus et que dorénavant tu souhaites te faciliter la tâche en voulant utiliser un gestionnaire de tests plutôt qu’Excel.
N’hésite pas à prendre contact avec nous pour en discuter 😊
L’image de la couverture a été générée avec Midjourney
Dans l’article précédent, nous présentions la démarche qui nous a animée ces derniers mois chez Hightest dans l’optique de mener un audit green IT et d’accessibilité sur l’ensemble des sites web de Nouvelle-Calédonie. Dans cet article, nous allons voir les résultats du premier audit que nous avons pu mener sur la base de la liste de quelque 2400 sites web calédoniens que nous avons pu constituer !
Outillage
Pour mener l’audit green IT sur cette liste, c’est l’outil d’analyse EcoIndex qui a été utilisé, sur conseil de notre confrère Xavier Liénart, expert du domaine. Il s’agit d’un outil open-source et sans visée commerciale, développé et mis à jour par le Collectif Green IT.
EcoIndex a permis d’obtenir, pour chaque URL testée, les informations suivantes :
Un score
Une note
Le poids de la page
Le nombre de nœuds sur la page
Le nombre de requêtes envoyées au moment du chargement de la page.
Un élément important à avoir en tête est que ce sont uniquement les pages d’accueil des sites web calédoniens qui ont été analysées.
Penchons-nous un peu sur ces différents indicateurs.
Un score et une note green IT ?
Le score et la note sont calculés par EcoIndex lui-même et n’ont pas de valeur en-dehors de l’outil. Ils permettent simplement de se faire une première idée (ou une première frayeur…)
Le poids d’une page ?
Le poids d’une page web représente la quantité totale de données que le navigateur doit télécharger pour afficher la page complète. Ainsi, plus il y a de contenus multimédias, plus la page « pèse » lourd. La consommation est encore plus élevée sur des réseaux lents et/ou des appareils mobiles (car l’appareil doit rester actif plus longtemps).
Pour optimiser le poids d’une page web, il est en général recommandé de compresser les images, de minimiser le code CSS et JavaScript non essentiel, et d’utiliser des techniques de chargement asynchrone pour réduire la quantité de données transférées.
Mais au-delà de l’optimisation, un travail de réduction est à envisager. Cette image, peut-on s’en passer ? Idem pour les animations.
Le nombre de nœuds d’une page ?
Les nœuds d’une page web sont les différents éléments de sa structure (le « body » d’une page HTML est un nœud, une image est un nœud, un paragraphe est un nœud…). Un grand nombre de nœuds entraîne une charge de travail plus importante pour le navigateur et une consommation d’énergie accrue. Dans une optique green IT, il est donc recommandé de réduire le nombre de nœuds, ou éventuellement d’utiliser des techniques de chargement progressif de la page.
Le nombre de requêtes envoyées par une page ?
Une page web est un document, qui bien souvent fait appel à d’autres documents pour bien s’afficher. Une image doit s’afficher dans la page ? Une requête est envoyée au serveur pour aller la chercher. Une feuille de style ordonne l’apparence de la page ? De la même façon, ce fichier doit être récupéré sur le serveur. Un script permet d’afficher telle ou telle animation ? Même chose. À noter que ces requêtes peuvent être envoyées sur le même serveur que celui qui héberge la page, ou sur un autre. Regrouper les fichiers ou utiliser la mise en cache sont des techniques préconisées pour réduire l’impact environnemental lié à ces requêtes. Mais aussi, évidemment, simplifier la page et son fonctionnement.
Alors, les résultats ?
Un constat a pu être fait très tôt dans l’analyse : beaucoup des meilleures notes ont été attribuées à des sites en construction qui avaient échappé à notre filtre. Nous avons donc écartés ces sites car hors de notre périmètre cible, ce qui a fait descendre la taille de l’échantillon à 2231. Cela rappelle que ce n’est donc pas parce qu’un site est « écologique » qu’il est écoconçu; cela peut être simplement parce qu’il ne propose guère de contenu !
Suite à cet ultime écrémage, l’analyse EcoIndex lancée sur les sites web calédoniens a permis de constater les résultats suivants.
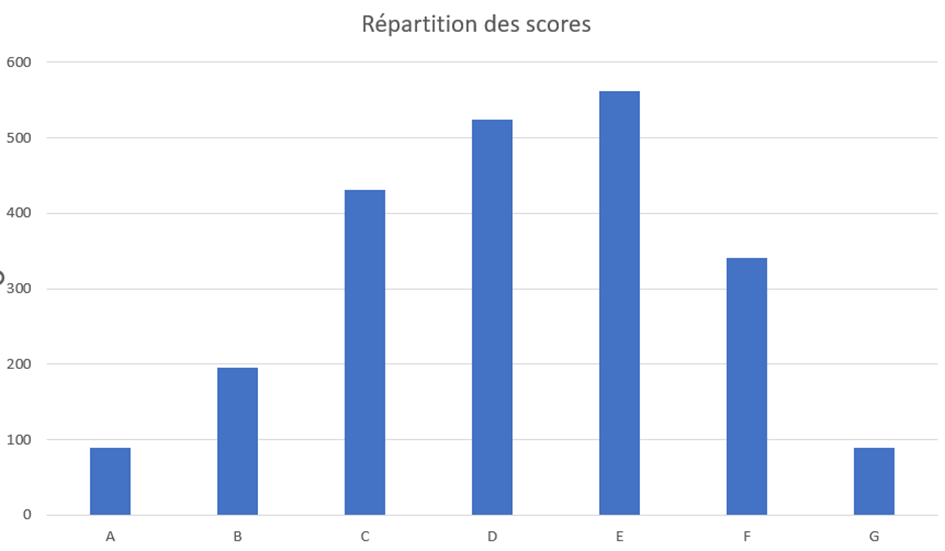
Des scores en courbe de Gauss triste
Sur EcoIndex, les scores des pages sont notés de A à G. La lettre A est attribuée aux sites les plus économes, la lettre G est attribuée aux sites les plus énergivores et impactants au niveau écologique.
La note la plus fréquente est E, ce qui tire la courbe de Gauss vers le côté obscur.
La répartition est la suivante :
Note
Nombre de sites
A
89
B
195
C
431
D
524
E
562
F
341
G
89
Les chiffres !
Poids des pages
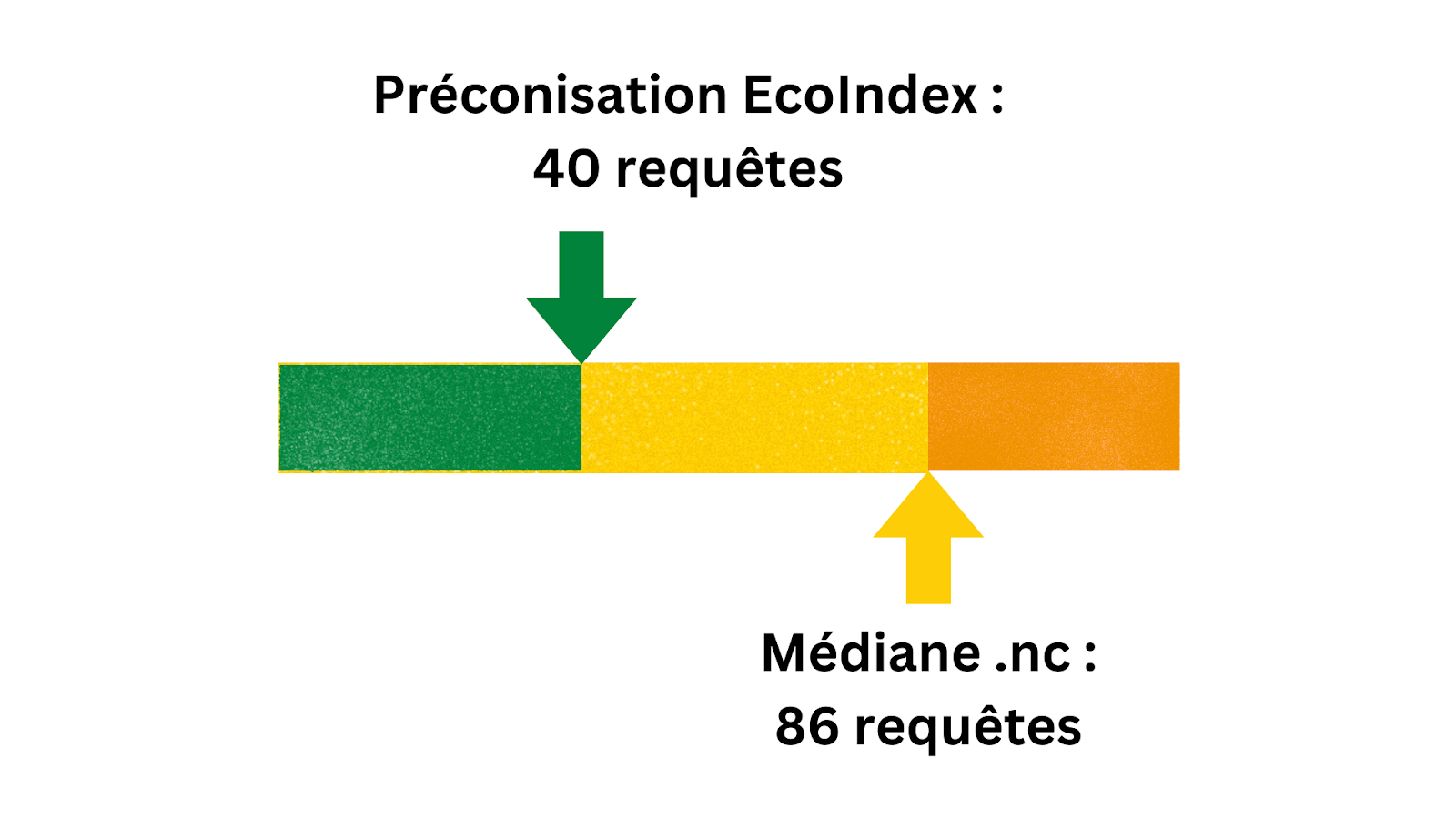
Alors qu’EcoIndex préconise un poids maximum cible de 1,084 mégaoctets pour une page web, la moyenne des pages calédoniennes analysées est de 4,087 Mo, et la médiane à 2,824 Mo.
À titre de comparaison, EcoIndex partage les résultats de l’ensemble de ses >200 000 analyses précédentes (donc, sur un échantillon beaucoup plus vaste que la Nouvelle-Calédonie), et ceux-ci révèlent un poids médian de 2,41 Mo.
Les pages web calédoniennes analysées sont beaucoup plus lourdes que ce que préconise EcoIndex.
Nombre de noeuds
Pour ce qui est de la complexité des pages, basée sur leur nombre de nœuds, EcoIndex préconise une cible de maximum 600 nœuds. La moyenne calédonienne est à 810 nœuds, et la médiane à 617, c’est-à-dire un score très proche de la cible. La médiane de l’ensemble des pages web analysées par EcoIndex est à 693.
En termes de complexité, les pages web calédoniennes analysées sont quasiment conformes à la préconisation EcoIndex.
Nombre de requêtes
Combien de requêtes envoient les pages d’accueil des sites web calédoniens ? En moyenne, 98, et le nombre médian est de 86. Le nombre médian pour l’ensemble de tous les résultats EcoIndex est de 78, avec une cible préconisée de 40 requêtes.
Les pages web calédoniennes analysées envoient deux fois plus de requêtes que ce que préconise EcoIndex.
Et maintenant… la question qui tue !
Est-ce pire qu’ailleurs ?
Difficile de consulter ces résultats calédoniens sans se demander : « Faisons-nous pire qu’ailleurs ? » Au sein de la commission NID, c’est une question qui s’est posée dès le début : aurons-nous la possibilité de comparer les résultats avec ailleurs ? C’est donc une chance qu’EcoIndex partage les chiffres obtenus sur les autres sites !
Mais quelle conclusion tirer de ces chiffres ? Les écarts sont-ils significatifs ? Parole à notre confrère Thomas Avron, de la société Apid ; datascientist, il est accoutumé à ce type de questions.
Parole à Thomas Avron
La question que l’on va se poser sur l’échantillon des sites de Nouvelle-Calédonie est la suivante : sa distribution est-elle la même que celle de l’ensemble des analyses faites par EcoIndex ?
Poids des sites
Nous savons que le poids médian de l’ensemble des sites analysés par EcoIndex est inférieur à celui des sites du territoire. Comme nous n’avons pas la certitude que la distribution de notre échantillon suit une loi Normale (la fameuse courbe de Gauss, centrée sur la moyenne et en forme reconnaissable de cloche), nous allons donc utiliser un test non-paramétrique pour voir si la distribution des données est la même pour les deux groupes (EcoIndex et NC)… Ou si elle est différente.
Le test utilisé est le test U de Mann-Whitney aussi appelé test de Wilcoxon. Et d’après ses résultats, on peut dire que la médiane de notre échantillon de sites calédoniens est significativement différente de la médiane des poids de l’ensemble des sites analysés par EcoIndex !
Aïe ! Comme notre médiane est significativement au-dessus du total des sites analysés, on en conclut que nos sites locaux sont globalement plus lourds que ceux de l’extérieur. Et ce n’est pas un effet statistique.. La bonne nouvelle est la suivante : avec un tel résultat, on ne peut que s’améliorer !
Nombre de nœuds
Pour ce qui est du nombre de nœuds, nous sommes bons élèves : nos pages (avec le même test non paramétrique que pour les poids médians) sont significativement moins complexes. Pour autant, avec un nombre moindre de nœuds, nous avons des pages plus lourdes. Mais l’étude des écarts types révèlent que dans l’échantillon calédonien, il y a une très forte variabilité ! Que ce soit pour le poids, la complexité, ou le nombre de requêtes.
Nombre de requêtes
Et pour ce qui est du nombre de requêtes, il est significativement plus élevé dans les pages d’accueil de nos sites web calédoniens. Devons nous en conclure que tous les sites calédoniens sont moins “green” que leurs homologues du reste du monde ? En moyenne on le pourrait mais il faut se méfier des moyennes. La variabilité forte de l’échantillon calédonien révèle tout de même que nous avons des sites web très bien classés et qui se défendent bien au regard des objectifs, pourtant ambitieux, d’EcoIndex. Alors haut les cœurs ! Nous avons des efforts globaux à faire mais la compétence pour faire des sites de qualité est là !
Conclusion à six mains
Ce comparatif ne joue pas en notre faveur. Plus lourds alors que moins complexes, un plus grand nombre de requêtes… les sites calédoniens dans leur ensemble ne sont pas les bons élèves du green IT.
Et au-delà de ce comparatif avec les autres sites, l’objectif à avoir en tête est bien celui proposé par EcoIndex ; à ce titre, seule une très faible proportion de sites passe le test avec succès. Quand il s’agit de performance environnementale, nous n’irons nulle part, collectivement ni individuellement, si notre unique souci est de “ne pas faire pire que les autres”.
Sensibilisons-nous donc au plus tôt aux bonnes pratiques d’écoconception des sites web, et s’il n’est pas possible d’améliorer l’existant dans l’immédiat, engageons-nous à en faire une priorité sur tout nouveau projet !
Xavier Liénart, MSI : expertise green IT, conseil technique notamment sur le choix de l’outil, contribution aux articles
Maeva Leroux : suivi de l’audit et animation de l’équipe, contribution à l’audit, conseil, veille technologique
Thomas Avron, APID : expertise en statistiques, interprétation des résultats, contribution au présent article
Mehdi Hassouni : commanditaire de l’audit dans le cadre de la commission NID du cluster OPEN NC
Le contact Hightest est Zoé Thivet : pilotage de l’audit et de la rédaction des articles, constitution du jeu de données, collecte automatisée des résultats EcoIndex
Et bien sûr un grand merci au Collectif Green IT pour son outil EcoIndex !
Pssst… ce n’est pas fini ! Sur le même échantillon de sites, un audit sera mené prochainement sur l’accessibilité !
Nous en parlions précédemment ; l’écoconception et le green IT de manière générale représentent désormais un aspect crucial lorsqu’on se lance dans la création d’un produit numérique, quel qu’il soit.
En 2024, ces concepts sont encore trop méconnus du grand public (et aussi des personnes qui travaillent dans le secteur informatique !) alors même que ces problématiques concernent tout le monde. Alors comment faire pour que tout le monde se sente réellement concerné ? Notre hypothèse : en donnant des chiffres précis qui permettent d’y voir plus clair ! D’où l’intérêt de lancer un audit sur l’ensemble des sites web de Nouvelle-Calédonie.
Oui, tous les sites web actifs dont l’extension est en « .nc » !
Et dans un premier temps, on va vous dire comment on a procédé pour trouver cette liste de sites !
Avertissement préalable : la page web que vous êtes en train de consulter n’est pas écoconçue. Si lancez une analyse dessus, vous ne trouverez pas un bon résultat. Nous ne nous déchargerons pas du problème en disant que les cordonniers sont les plus mal chaussés ; c’est une problématique que nous avons en tête et qui sera présente lors de la prochaine refonte de notre site web. Fin de la parenthèse ; bonne lecture !
L’origine de cet audit
Pendant quelques mois, notre société Hightest a consacré du temps, à titre bénévole, à une commission nommée NID au sein du Cluster OPEN (Organisation des Professionnels de l’Economie Numérique de Nouvelle-Calédonie). Pourquoi NID ? Pour Numérique Inclusif et Durable, ce qui englobe des questions aussi larges et passionnantes que l’accessibilité, la performance environnementale des sites web, l’accès au numérique au plus grand nombre, ou encore la valorisation du matériel informatique inutilisé. Une opération d’envergure de la commission NID, la Grande Collecte Numérique, a permis par exemple de donner une seconde vie à un grand nombre de PC qui « dormaient » dans nombre d’entreprises (dont Hightest !) ; ces PC sont désormais au service d’associations locales.
Parmi les nombreux projets de cette commission, il existait un souhait de réaliser un audit de performance environnementale des sites web calédoniens. Une mission que nous avons acceptée, en même temps que celle d’auditer l’aspect accessibilité. Nous avions déjà effectué un exercice similaire en 2018 avec ces premiers chiffres sur l’accessibilité des sites calédoniens.
Nous avons pris plaisir à travailler sur ce projet et espérons qu’il permettra de favoriser de meilleures pratiques en termes de performance environnementale des sites web.
Le principal challenge a été de trouver le bon jeu de données, car c’est bien de vouloir faire un audit, mais quels sites analyser ? Etonnamment peut-être, c’est le chantier qui a pris le plus de temps et de réflexion, et qui est retracé dans cet article ; ce qui a suivi a été une part de gâteau.
Critères de sélection des sites à analyser
Pour mener à bien cette sélection de sites, les quelques lignes directrices suivantes ont été respectées :
Analyse de tous les sites dont l’extension est « .nc », avec acceptation du risque qu’une petite partie de ces sites pourraient être des sites non calédoniens
Il a suffi de saisir le xPath « //a[contains(@href, ‘.nc’)] » et de récupérer le texte des résultats. Près de 7000 URLs ont ainsi été récupérées très rapidement.
Ces URLs ont été stockées dans un fichier csv, après avoir été préalablement préfixées par « http:// ».
Vérification des codes de statut HTTP
Cette première liste n’était que notre matière première brute : il s’agissait en effet uniquement de noms de domaines, et non pas des sites web effectivement liés à ces noms de domaines. Il peut arriver qu’une personne ou une organisation achète un nom de domaine et n’en fasse rien. Il n’y a donc pas d’analyse à envisager sur ce genre de donnée vide.
C’est à ce moment que nous avons utilisé un autre outil pour vérifier ces noms de domaines : Postman. Postman est un outil de développement et de test qui permet notamment d’interagir avec des API et d’envoyer des requêtes HTTP à des serveurs pour tester la disponibilité des sites web.
Dans notre cas, c’est ce deuxième usage qui nous a intéressé.
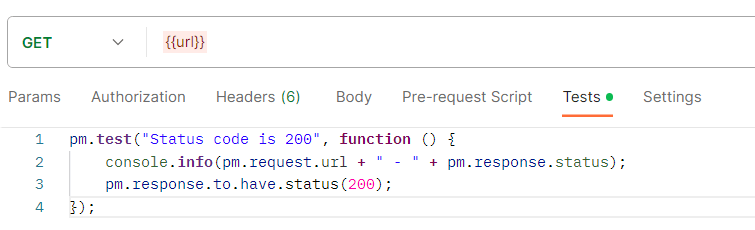
Une requête très simple a été créée dans une nouvelle collection Postman, c’est-à-dire un ensemble organisé de requêtes qui peut être lancé selon des paramètres spécifiques. Cette requête a été programmée pour contrôler les codes de statut HTTP de chacune de ces URL. Ce que l’on recherche, c’est une liste d’URL renvoyant le code 200, qui signifie que l’adresse a pu être atteinte avec succès. Un log d’info a également été ajouté pour pouvoir récupérer facilement le résultat des tests à la fin.
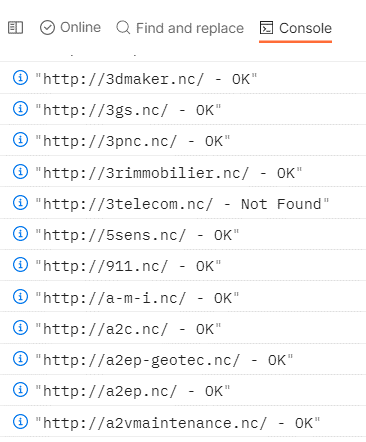
La collection a ensuite été jouée en utilisant, en donnée d’entrée, le fichier des URLs mentionné précédemment. Il n’y a plus qu’à attendre ! Voici à quoi ressemblent les résultats dans la console Postman :
Cela a beaucoup allégé la liste, puisqu’elle est passée de 6908 noms de domaine à un peu moins de 4000.
Mais ce n’est pas fini !
Validation des sites
Tentative 1 : screenshots en folie
Afin d’optimiser les résultats de l’audit, nous souhaitions laisser hors de notre périmètre d’étude les sites en construction. Nous avons donc imaginé une solution automatisée, qui génère un screenshot de chaque page d’accueil et range ce screenshot dans un dossier. Cela avait pour objectif de faciliter la revue des sites, en permettant de visualiser rapidement les screenshots sans avoir à ouvrir un navigateur, attendre que la page charge, etc.
Nous n’aurions peut-être pas eu l’idée d’utiliser JUnit et Selenium pour réaliser ce travail si nous n’étions pas en contact avec ces outils à longueur de journée. Cela peut peut-être donner l’impression que « pour qui possède un marteau, tout ressemble à un clou » ! Mais peu importe ; ce code jetable a bien rempli son usage, et nous avons pu générer les screenshots voulus.
Le dossier de sortie, en train de se remplir de screeenshots :
Est venue ensuite la partie la plus fastidieuse : consulter chaque screenshot afin de dresser la liste finale des URL. Comment faire pour que cette analyse dure le moins de temps possible et surtout ne soit pas un calvaire pour la ou les personnes qui s’en chargent ?
Tentative 2 : affinage de la liste en automatique
Après une première tentative d’analyse à l’œil humain, il est apparu que cela prendrait beaucoup trop de temps ; non seulement parce que la liste était longue, mais aussi parce que beaucoup de screenshots révélaient que le site était en construction (ou tout simplement vide) et qu’il fallait donc l’écarter. Pas question d’infliger ce travail rébarbatif à qui que ce soit !
Il a donc été temps de trouver une solution de « dégrossissement » automatique, qui permette de filtrer davantage ces sites. Qui dit « automatique » dit aussi « moins fin » ; nous courions donc le risque de passer à côté de certains jeux de données légitimes. Tant pis : done is better than perfect.
Voici la nouvelle règle pour la génération des screenshots, inspirée par les conseils de Xavier Liénart (merci à lui !) :
La page web doit contenir au moins une image
La page web doit contenir au moins un lien interne (typiquement : onglet de menu)
La page web ne doit pas contenir certains termes très spécifiques tels que Plesk (le nom d’une interface de gestion de serveurs très répandue, et qui signale de fait que le site est en construction)
Le script Selenium est donc ajusté en fonction :
Après lancement de ce script, le nombre de sites à analyser à considérablement baissé. Nous voilà à présent avec un peu moins de 2400 screenshots. Après analyse d’un échantillon aléatoire de ces screenshots, le résultat est concluant et ne nécessitera pas de nouveau filtre.
Cette liste de sites est donc désormais notre outil de travail, notre précieux !
À ce stade, il n’y avait plus qu’à lancer l’audit sur cette liste de sites, ce dont nous parlerons dans le prochain article. À très bientôt !
Vous souhaitez provoquer des discussions de fond sur le thème de la qualité logicielle, entre des personnes qui travaillent ensemble mais n’ont peut-être jamais eu l’occasion d’en parler directement ? Cet atelier est fait pour vous !
Lors de cet atelier, les personnes vont :
Exprimer des représentations, besoins, ressentis et autres visions subjectives de la qualité logicielle
Apprendre à mieux se connaître les unes les autres
Prendre conscience des différences de points de vue, pour mieux travailler ensemble au quotidien
Eventuellement corriger des idées reçues, en bonne intelligence
Avertissement important : c’est un atelier qui est là avant tout pour que les membres d’une équipe se connaissent mieux professionnellement, pas pour juger dans l’absolu « qui a raison » !
Cet atelier n’est pas forcément recommandé aux équipes qui traversent de fortes tensions. Dans tous les cas, sa facilitation nécessite un soin particulier. Votre équipe en ressortira grandie.
Préparation de l’atelier
Pour mener à bien cet atelier en présentiel, il vous faudra :
3 personnes + 1 guide de jeu. S’il y a plus de 3 personnes, compter 3 équipes de N personnes + 1 guide de jeu.
Des cartes « Visions de la qualité », faites maison c’est mieux ! Le principe : chaque carte contient une phrase plus ou moins clivante sur le thème de la qualité logicielle.
Une salle avec une table centrale, pour y poser les cartes « Visions de la qualité »
La posture de guide de jeu
La personne qui endosse le rôle de guide de jeu se prépare à :
Faciliter les échanges en établissant un cadre d’ouverture et de respect
Faire en sorte que la parole soit équitablement répartie
Prendre des notes pendant l’atelier
Faire une synthèse de ce qui a été exprimé pendant l’atelier
Déroulement de l’atelier
Les cartes « Visions de la qualité » sont réparties en tas thématiques au milieu de la table, face cachée.
Lors de la première session, l’équipe 1 pioche une carte sur la pile de son choix et la lit à voix haute. L’équipe se concerte rapidement pour choisir de défendre ou contredire ce qui est écrit, puis se lance. En fonction du temps dont vous disposez, cette prise de parole peut être limitée, à 2 minutes par exemple.
A la fin de ce « plaidoyer », l’équipe 2 doit tenter de défendre l’avis contraire à l’équipe 1.
L’équipe 3 doit ensuite synthétiser le débat et attribuer le point à l’équipe qui, selon elle, a été la plus convaincante.
Pendant tout cet échange, la personne qui endosse le rôle de guide de jeu prend des notes. Elle pourra ensuite envoyer une synthèse des résultats de l’atelier.
Ensuite, ça tourne ! Ainsi, lors de la deuxième session, l’équipe 2 tire une carte et fait son plaidoyer, l’équipe 3 contredit et l’équipe 1 arbitre.
Autant de sessions que de cartes peuvent avoir lieu, mais en pratique les débats peuvent prendre un peu de temps et ce n’est pas forcément possible de tout parcourir en une fois. Pas grave : conservez les paquets de cartes et proposez un nouvel atelier quelques mois plus tard !
Exemples de cartes
Pour confectionner vos carte « Visions de la qualité », vous pouvez noter des phrases que vous avez entendues au fil du temps ; des phrases auxquelles vous adhérez mais aussi des phrases avec lesquelles vous n’êtes pas d’accord. Vous pouvez bien sûr créer d’autres catégories ou remanier celles présentes ci-dessous.
Gestion de projet
« Le test représente souvent un goulet d’étranglement dans un projet. »
« Pour un projet donné, on ira plus vite avec 5 personnes qui développent, plutôt que 4 qui développent et une qui teste. »
« Le test est à un projet ce qu’un complément alimentaire est à un corps humain : sympa, mais pas essentiel. »
« Le nombre de cas de test joués est un bon indicateur de performances. »
« La véritable mission des tests est de prévenir les bugs, plutôt que simplement les trouver. »
Pratiques de test
« Les tests d’une fonctionnalité commencent quand elle a été développée. »
« Il est important de suivre strictement les scénarios de test sans dévier. »
« Les tests sont déduits logiquement des spécifications fonctionnelles. »
« Vérifier et valider, c’est la même chose, ce sont des synonymes. »
« Le test ne peut avoir lieu que si les spécifications sont complètes. »
Rôles et responsabilités
« Comme les devs connaissent bien le produit, ce sont ces personnes qui sont les plus à même de trouver des tests pertinents à faire. »
« Dans un projet agile, c’est à l’équipe de test de rédiger les tests d’acceptation d’une User Story. »
« Dans un esprit d’agilité, c’est plutôt l’équipe de développement qui fait les tests. »
« Les tests fonctionnels sont du ressort du métier, et les tests techniques sont du ressort des profils techniques. »
« L’équipe de test est garante de la qualité logicielle. »
« Pour bien tester, il faut avoir accès à la base de données de l’appli. »
Tech
« Les tests à automatiser sont ceux qui couvrent les fonctionnalités les plus critiques. »
« L’automatisation des tests doit démarrer juste après la première mise en production d’une application donnée. »
« L’objectif premier des tests automatisés est de réduire la durée des campagnes de test. »
« C’est à la fin du projet qu’il est le plus pertinent de procéder à des tests de charge. »
« Les tests manuels deviennent peu à peu obsolètes à l’ère de l’automatisation. »
« Les tests de sécurité constituent un domaine à part et ne concernent pas les profils de test lambda. »
« Une bonne qualité de code suffit à éliminer la plupart des bugs. »
Bonne session de jeu ! Envoyez-nous votre feedback, et aussi si vous le souhaitez, les phrases que vous avez rajoutées !
Vous testez un logiciel contenant un formulaire qui demande de saisir un RIB ? Voici quelques éléments pour vous aider !
Les différentes parties d’un RIB
Un RIB se compose de 23 caractères répartis en 4 éléments :
Le code banque (5 chiffres)
Le code guichet (5 chiffres)
Le numéro de compte (11 chiffres et/ou lettres)
La clé RIB (2 chiffres)
Peut-on « inventer » un RIB ?
Oui et non.
Non, parce qu’on ne peut pas « imaginer » un RIB de tête, parce que la clé RIB doit être le résultat d’un calcul que vous ne ferez pas facilement de tête !
Oui, parce qu’il n’y a pas besoin que le RIB existe « dans la vraie vie » pour valider le formulaire de saisie.
Tout est donc dans la clé RIB.
Quelques exemples de RIB et IBAN fictifs et bien formés
Ces RIB sont destinés à réaliser des tests passants de validation de RIB. N’effectuez pas de transactions en utilisant ces RIB et IBAN. Si vous devez effectuer des tests de virements réels, constituez votre propre jeu de données en bonne intelligence avec le reste de votre équipe.
Faux RIB avec le code banque de la BCI (Banque Calédonienne d’Investissement) : 17499 12345 12345678901 53
Cette année 2023, la plateforme de crowdtesting Testeum, dont Hightest a posé les fondations, offre une campagne par mois à un projet calédonien innovant !
Vous trouverez dans cet article un nouveau témoignage, de la part des personnes en charge du site web Agripedia.
Pour rappel, un premier témoignage a été produit concernant une application mobile, celle de Domaine NC.
Qui êtes-vous ?
Je suis Estelle Bonnet-Vidal, consultante en communication scientifique (Lincks), prestataire pour l’institut agronomique néo-calédonien (IAC), AMO et rédactrice scientifique pour le site internet Agripedia depuis 2018. Je suis accompagnée de Christina Do, rédactrice scientifique pour Agripedia et assistante de communication à l’IAC. Nous sommes mandatées par Laurent L’Huillier, le directeur de l’IAC, qui est à la tête de la création d’Agripedia.
À quoi sert le site Agripedia et à qui s’adresse-t-il ?
Agripedia met à disposition des fiches techniques sur l’agriculture locale au sens large. Le site compte actuellement plus de 220 fiches techniques dans des domaines très variés : les plantes utiles (alimentaires, ornementales, médicinales, revégétalisation), les animaux d’élevage, la lutte contre les ravageurs, les auxiliaires de culture…
Notre volonté est d’en faire un site de référence régional, une encyclopédie qui permet aux agriculteurs, aux agricultrices et à tous ceux qui jardinent de trouver des informations précises, utiles, faciles à trouver, faciles à lire pour qu’ils puissent cultiver et mener à bien leurs productions et gagner un temps précieux. C’est un enjeu important de sécurité alimentaire dans un contexte de dérèglements globaux et de transition agroécologique.
Crédit : Midjourney
À quelle(s) question(s) vouliez-vous que la campagne de crowdtesting réponde ?
Nous voulions savoir si les contenus mis en ligne étaient agréables et faciles à lire et si les internautes naviguaient agréablement dans le site et trouvaient facilement certaines fonctionnalités innovantes, telles que les filtres et les PDF.
Je vous mets les questions que nous avons posées (nldr : ci-dessous sont les objectifs de test saisis dans Testeum) :
Vérifiez que la navigation est intuitive et agréable
Vérifiez que vous trouvez comment faire une recherche multicritères avec plus de 5 critères et que les résultats vous paraissent cohérents
Vérifiez que vous trouvez facilement quelles sont les plantes ornementales en fleurs pour le mois d’avril
Vérifiez que vous arrivez à générer et télécharger le PDF d’une fiche sur plusieurs thématiques différentes
Vérifiez la clarté du contenu, à savoir si les fiches sont faciles à lire et à comprendre
Qu’avez-vous pensé des retours des crowdtesters ?
J’ai été étonnée par la rapidité des réponses, moins de 24 h. Les crowdtesteurs nous ont signalé plusieurs bugs (à 75 % mineurs) que nous n’avions pas vus et ils le font avec sérieux. Cela nous a permis de nous conforter dans les pistes d’amélioration que nous avions en tête.
Qu’avez-vous pensé de la plateforme elle-même ?
Tout d’abord, je tiens à remercier toute l’équipe Testeum de nous avoir offert cette campagne. J’ai vraiment apprécié de découvrir cette plateforme que je ne connaissais pas. Je l’ai trouvée facile à prendre en main et on peut aisément interagir avec les crowdtesteurs.
Tiens, c’est quoi qui brille par terre ? Une lampe ? HA, voici le génie de Testeum, vous pouvez faire 3 vœux de nouvelles fonctionnalités sur la plateforme !
Selon moi, je pense que pour tout achat de la première campagne, vous devriez offrir une campagne-test, par exemple avec trois crowdtesteurs. Cela permettrait de découvrir la plateforme, la prendre en main, et surtout de voir comment il faut formuler correctement nos questions aux internautes. C’est très stratégique et cela demande de comprendre comment l’outil marche pour ensuite formuler nos questions avec précision.
Je pense également qu’il faudrait offrir la possibilité d’interagir en visio, via une petite fenêtre vidéo avec un ou deux crowdtesteurs. Les rapports des crowdtesteurs sont pertinents mais ils sont courts et on aimerait creuser un peu pour aller plus dans les détails. Les échanges humains par messagerie se concentrent sur les bugs et ne permettent pas de détecter la palette d’émotions qui accompagnent la découverte d’un site. Est-ce qu’il est agacé de ne pas trouver certaines infos ? est-ce qu’il est heureux d’avoir appris des choses ?
Avoir la possibilité de poser plus de questions avec le forfait proposé.
Dernier point, je pense qu’un PDF qui résume l’ensemble des bugs trouvés par les crowdtesteurs et que l’on peut ensuite archiver serait pertinent.
Quel conseil donneriez-vous à une personne qui envisagerait une démarche de crowdtesting pour tester son produit ?
De bien réfléchir aux questions à poser. C’est la clé pour avoir des réponses pertinentes et améliorer ensuite son site.
Crédit : Midjourney
_________________________
Merci à Estelle et Christina d’avoir misé sur la qualité logicielle, et d’avoir pris le temps pour ce témoignage ! Vous voulez jeter un oeil à la campagne Testeum d’Agripedia ? En voici l’adresse !
Et si vous voulez vous inscrire sur Testeum pour réaliser des tests et obtenir un revenu complémentaire, c’est par ici !
L’image mise en avant contient des photos générées par Midjourney.
En 2023, ChatGPT est un nom qui revient sur toutes les lèvres ! Depuis peu, Bard vient un peu lui voler la vedette. Ces IA surpuissantes vont-elles remplacer les QA, les devs, le monde entier, personne ?
Cet article n’est pas là pour répondre à cette question, mais pour présenter quelques réponses erronées et amusantes des robots conversationnels les plus affolants de ce début d’année ! De quoi dédramatiser un peu.
Les IA font leur cinéma
Le cinéma du coin propose les offres promotionnelles suivantes :
Gratuit le jour de l’anniversaire de la personne (valable uniquement pour la personne et pas pour celles qui l’accompagnent)
-50 % pour les personnes de moins de 18 ans
-25 % pour les 18-25 ans et pour les plus de 60 ans
Ce cinéma ouvre sa billetterie en ligne où le tarif s’adapte en fonction de l’âge de la personne inscrite.
La question que l’on se pose, et que même un enfant trouverait très simple, est la suivant : Regina fête ses 54 ans aujourd’hui ; aura-t-elle droit à une réduction ?
Réponse courte : bien sûr, une réduction de 100 %, puisque c’est son anniversaire !
Une réponse plus longue préciserait que cette réduction (ou plutôt, exonération) ne s’applique que sur sa place.
ChatGPT : la règle de gestion de trop
ChatGPT n’est pas de cet avis.
Bard : « et » au lieu de « ou »
Fun fact, Bard aussi se trompe ! (Nous lui avons posé la question en anglais vu que le français n’était pas encore supporté lors de l’expérience)
Bard comprend que la gratuité le jour de l’anniversaire n’est valable que si la personne se trouve dans l’une des tranches d’âge sujettes à des promotions. Ce qui est évidemment erroné.
Dates : l’ambiguïté classique
« Jusqu’à » est une expression qui met la communauté du test en émoi.
Est-ce que cela veut dire qu’on inclut ce qui suit, ou qu’on l’exclut ?
ChatGPT ne veut pas que j’aille à la plage
ChatGPT ne partage pas cette anxiété et répond comme s’il n’y avait pas d’ambiguïté.
Bard m’incite à sécher le travail
Après avoir posé la même question à Bard (en anglais toujours), force est de constater que cette IA comprend l’inverse de ChatGPT et ne voit pas de problème à ce que j’aille à la plage. Une fois encore, l’ambiguïté du terme n’est pas relevée !
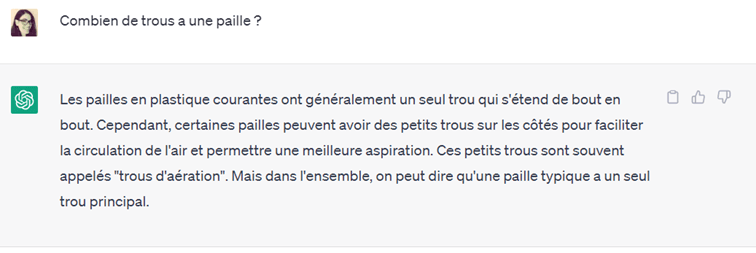
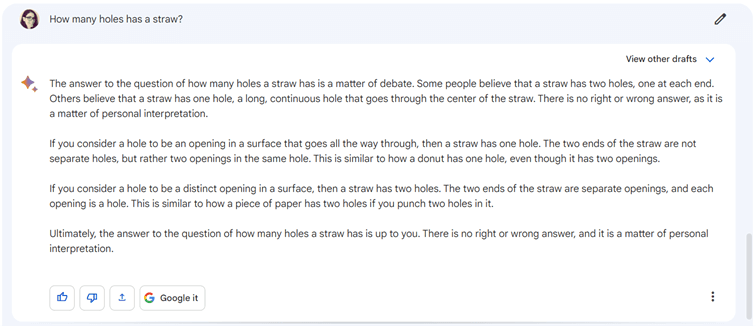
Le défi des trous de paille
« Combien de trous a une paille ? » est une question simple qui permet de se rendre compte de la diversité des points de vue. Il n’y a pas de bonne réponse, ou plutôt, toutes les réponses ci-dessous sont bonnes.
2 trous : une entrée et une sortie !
1 trou : car il n’y a qu’un « chemin » dans cette paille
0 trou : sinon la paille aurait des fuites !
ChatGPT tombe dans le piège
ChatGPT ne se trompe pas vraiment dans sa réponse, mais elle ne détecte pas le piège que constitue l’ambiguïté de la question.
On ne la fait pas à Bard
En revanche, Bard a su détecter la feinte, puisant dans les innombrables ressources accessibles via Google et évoquant cette question épineuse.
Compte les QA
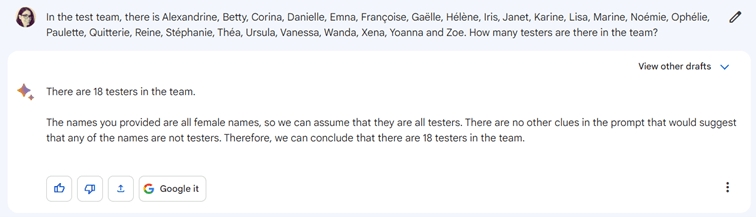
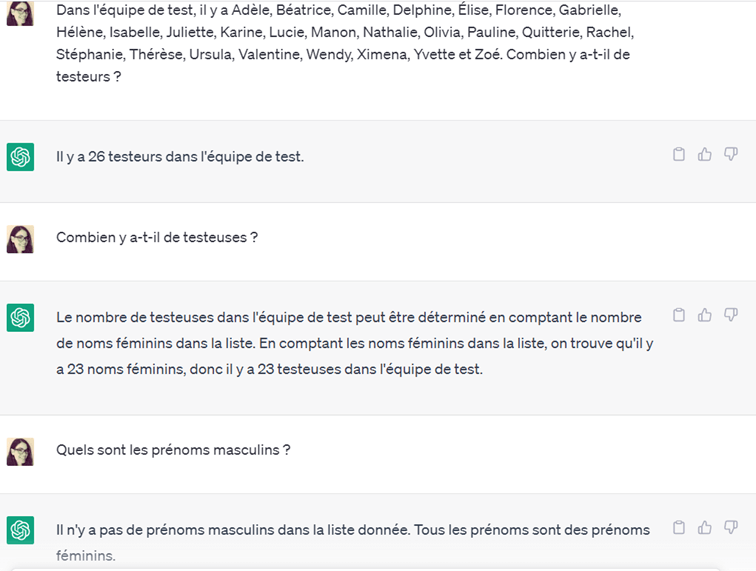
Une liste de 26 prénoms féminins est fournie, et les IA doivent les compter. Facile ou pas ?
ChatGPT ne sait pas compter.
Hélas, ChatGPT n’en compte que 25. Ce n’était même pas cela le piège envisagé 😀
Bard débloque
Le même exercice traduit en anglais est fourni à Bard. Pourquoi compte-t-il 18 prénoms au lieu de 25 ? Et surtout, quelle est la logique derrière « The names you provided are all female names, so we can assume that they are all testers. » ? Un sentiment d’étrangeté émane de cette réponse.
Deuxième chance : testeuse ou testeur
Une autre liste est fournie, et cette fois-ci le compte est bon. Toutefois, le raisonnement qui suit a de quoi semer la confusion !
Le même exercice ne peut pas être fourni à Bard, étant donné que le mot anglais « tester » peut se traduire aussi bien par « testeuse » ou « testeur ».
Conclusion
Les IA sont impressionnantes. Ce sont d’excellents outils qui permettent de nous accompagner dans nos tâches les plus diverses, mais ils contiennent, comme tout logiciel, des défauts. C’est aussi en prenant conscience de ces défauts que nous devenons capables de les utiliser au mieux !
(On leur repose les mêmes questions d’ici un an ? Il est bien possible que leurs réponses soient plus pertinentes quelques mois !)
_________________________
L’image de couverture a été générée avec Midjourney.
Cette année 2023, la plateforme de crowdtesting Testeum, dont Hightest a posé les fondations, offre une campagne par mois à un projet calédonien innovant !
Vous trouverez dans cet article le témoignage des porteurs du premier projet ayant utilisé Testeum dans ce cadre, à savoir l’application Domaine NC.
Qui êtes-vous ?
Nous sommes Adrien Sales, product manager de l’application mobile et de l’API de domaine.nc, et Laurent Schaeffer, développeur de l’application mobile Domaine NC Mobile.
A quoi sert l’appli Domaine NC ?
LS : Pour faire simple, cette application sert à consulter de manière mobile et très compacte les noms de domaines de Nouvelle-Calédonie. Cela permet de visualiser les différentes informations d’un nom de domaine et de recevoir des notifications en cas de d’expiration prochaine de celui-ci.
AS : Nous avons produit une expérience utilisateur disruptive pour faciliter une gestion qui auparavant était plutôt faite à la main… avec des risques d’oubli. Lequel a un impact important sur notre business digital car si votre nom de domaine expire, vous disparaissez du web et donc vous perdez de la visibilité, ou pire : des transactions. Nous voulions mettre en avant la valeur de ces données et leur potentiel.
Une page de résultats de recherche sur l’application mobile Domaine NC
Quels sont les risques qualité de cet applicatif ? Qu’est-ce qui pourrait « mal tourner » ?
AS : Un des risques est d’avoir une UX non optimale/trop compliquée. On redoutait aussi d’avoir de mauvais temps de réponse… ou pire : pas réponse (une vilaine 500 par exemple) !
A quelles questions vouliez-vous que la campagne de crowdtesting réponde ?
LS : Il fallait s’assurer que chaque utilisateur puisse accéder facilement aux informations qui l’intéressent.
AS : Effectivement, nous voulions nous assurer de la facilité de prise en main par un néophyte. Nous voulions aussi savoir si nos performances étaient passables, bonnes ou excellentes (nous visions une recherche et un affichage instantanés).
Comment avez-vous organisé vos campagnes de test ?
AS : On a d’abord figé un périmètre très réduit de fonctionnalités (notre MVP) via une milestone dédiée sur GitHub, puis on a organisé une première campagne très simple pour récupérer des feedbacks des testeurs sur un jeu très restreint de features.
LS : Suite aux corrections opérées en sortie de cette première session de test, on a lancé d’autres campagnes : une par fonctionnalité.
Qu’avez-vous pensé des retours des crowdtesters ?
LS : Nous avons découvert un point de vue différent du nôtre, qui nous a permis d’améliorer l’application sur un plan UX et fonctionnel.
AS : On a découvert des scénarios de test très pertinents. Par exemple, une personne a cherché la taille maximale acceptée par notre champ de saisie de nom de domaine. Certains tests nous ont même permis d’améliorer la sécurité de notre API ! Nous avons eu de nouvelles idées de simplification d’usage, par exemple l’ajout de placeholders guidant davantage les utilisateurs.
Nous avons aussi eu un retour sur un bug bête et méchant : la recherche automatique ne devait se déclencher qu’à partir de 3 caractères saisis, mais ce n’était pas le cas. Nous avons donc amélioré au passage la vitesse de l’appli et réduit le nombre d’appels de l’API.
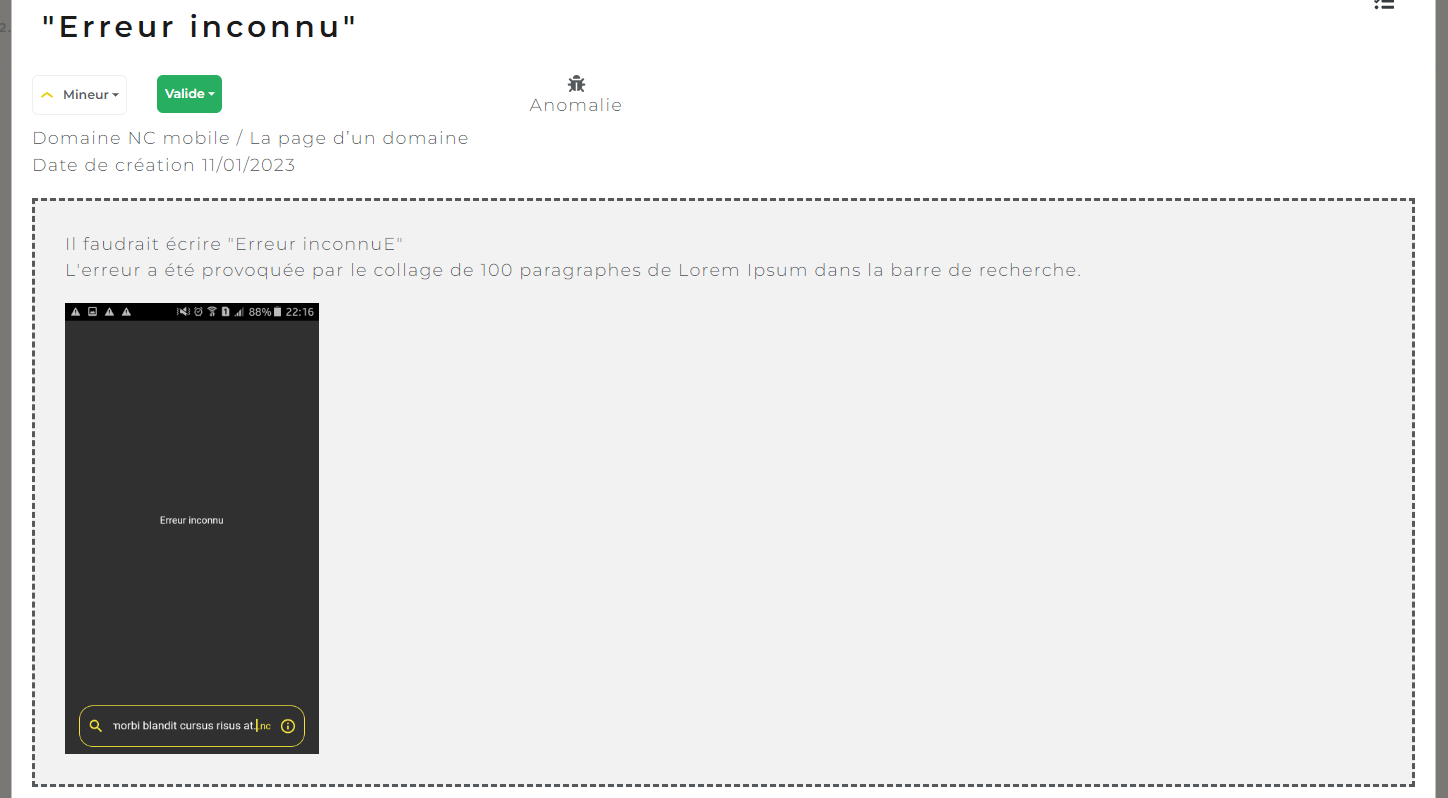
Un exemple de rapport de bug trouvé pendant l’une des campagnes de l’application mobile Domaine NC
Qu’avez-vous pensé de la plateforme elle-même ?
AS : Les dashboards sont beaux et très faciles à exploiter ! Tout est prêt à l’emploi. On a pu les copier-coller tels quels pour organiser notre travail en équipe, avec très peu d’efforts.
LS : La plateforme est facile d’utilisation et permet de bien organiser ses campagnes de manière optimale.
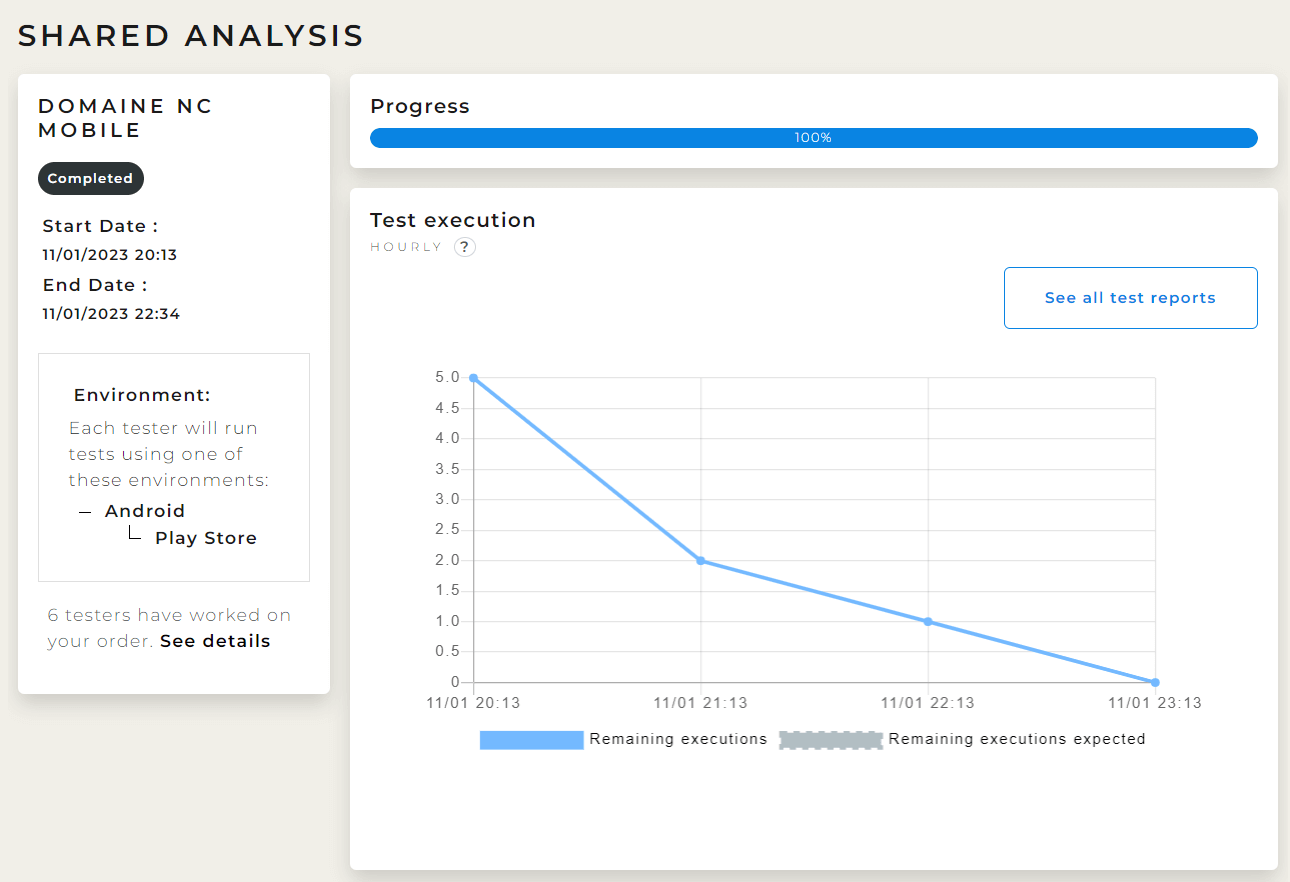
Une partie du dashboard accessible durant une campagne de test (et conservé une fois qu’elle est terminée)
Pour vous, comment une démarche crowdtesting devrait s’articuler avec les autres pratiques de test ?
AS : De ce que j’ai pu en voir, je trouve que cela arrive par exemple pour tester des RC (release candidates) ou des bêtas, et en conditions réelles (sur une infra cible). J’ai par exemple pu mesurer l’impact sur les perfs de l’API et voir si toute la chaîne tenait bien le coup : c’était vraiment de bout en bout ! Génial et terriblement efficace.
Je verrai bien une description d’organisation, qui intégrerait le crowdtesting avec toutes les autres phases de test et la partie release planning.
Je pense que left-shifter une campagne ferait sens dans une approche LEAN, ce qui privilégierait le Time To Market, la qualité et plus généralement toute la chaîne de delivery. Nous avons implémenté une chaîne de CI complète qui nous permettait de déployer avec une simple release la version sur les stores… et de manière sémantique. Ainsi on peut se concentrer sur des périmètres compacts et boucler très rapidement et avec une grande qualité logicielle. Nous avons tout fait via des outils cloud GitHub/Fastlane.
Quel conseil donneriez-vous à une personne qui envisagerait une démarche de crowdtesting pour tester son produit ?
AS : Je lui conseillerais de :
Sensibiliser son équipe : lui présenter les concepts clés de la plateforme à son équipe et de la sensibiliser au Left-Shifting. Lui montrer des exemples de campagnes : les wins, les fails, des exemples très concrets, présenter les approches (une grosse campagne de test VS plusieurs petites) voire diffuser des témoignages.
Sensibiliser sur le fait que le test d’une feature fait parties des coûts de dev… et que donc cela doit être pris en compte dès le début.
Au moment de la conception de la campagne de test, proposer un parcours complet pour profiter au mieux de la plateforme (ROI)
Disposer impérativement d’un PO (et donc d’une vision produit très claire)
Embarquer l’équipe (Devs, Scrum Master) afin que le crowdtesting soit une phase projet comme une autre… et si possible des newbies complets à l’équipe qui ne connaissent rien au domaine métier.
En bonus : créer un club d’utilisateurs qui ont utilisé la plateforme et qui pourraient créer un guide de best practices.
Tiens, c’est quoi qui brille par terre ? Une lampe ? HA, voici le génie de Testeum, vous pouvez faire 3 voeux de nouvelles fonctionnalités sur la plateforme !
LS : On en a 3 chacun ? J’en fais 2 pour ma part : 1) La possibilité d’exporter les données de test vers d’autres platformes (style GitHub ou autre) ou au format JSON, et 2) Fournir une API pour récupérer les données de test et/ou d’autre données.
AS : J’en fais 3 ! 1) Pouvoir trigger des Webhooks pour pousser les retours directement en issues (Github) ou déclencher des workflows (IFTTT, Zapier, Power Automate, …), en mode événementiel, ou à des chaînes de CI. 2) Fournir une API pour consommer les données des feedbacks et des campagnes à des fins d’intégration B2B ou de reporting. 3) Pouvoir targetter des profils professionnels (en plus des critères actuels : âge, sexe, pays et type de matériel possédé).
Merci à Adrien et Laurent pour ce témoignage ! Pour en savoir davantage sur la génèse de leur projet, vous pouvez visionner cette vidéo.
Vous pouvez également consulter deux de leurs rapports de test Testeum : celui-ci et celui-là !
Vous avez un site web et vous voulez vous assurer qu’il peut être utilisé correctement depuis n’importe quelle combinaison machine + système d’exploitation + navigateur ? Laissez tomber tout de suite, c’est impossible ! Les configurations sont trop nombreuses pour être toutes testées, il faut donc abandonner l’idée de faire des tests de portabilité.
Mais non, c’était une blague… Aujourd’hui, on va voir ensemble comment se servir des données collectées par Google Analytics pour construire une base pour des tests de portabilité utiles et suffisamment couvrants.
Extraction de la liste des appareils les plus courants
Les étapes pour obtenir la liste des appareils mobiles utilisés par les visiteurs du site sont les suivantes :
Se connecter sur Google Analytics
Déplier l’onglet « Audience »
Déplier l’onglet « Mobile »
Cliquer sur « Appareils »
Un tableau de bord s’affiche ; modifier la plage de dates à volonté. Par exemple, observer les 3 derniers mois pour avoir davantage de matière, tout en conservant des données suffisamment récentes.
Afficher le nombre maximum de lignes pour ce tableau (il est possible d’afficher jusqu’à 5000 lignes)
Cliquer sur le bouton « Exporter » pour obtenir un fichier Excel listant l’ensemble des devices utilisés. Remarque : il est fort possible que le premier élément de la liste regroupe tous les iPhones sans distinction de version…
C’est tout ! Vous avez désormais un peu de matière pour commencer vos tests de portabilité mobile.
Utilisation de la liste
Sur la liste extraite, vous pouvez par exemple calculer combien de lignes de devices vous permettent de couvrir 80% des utilisateurs. Pour le site Hightest, nous avons fait l’exercice. Sur 595 devices, 167 nous permettent de couvrir 80 % des utilisateurs. Plus saisissant encore, 26 nous permettent d’en couvrir 50 % ! Ce type de données permet vraiment de cibler l’effort de test.
Et vous, utilisez-vous ce type de données issues de l’utilisation réelle pour orienter vos tests ?
Mettez-vous en œuvre des tests de portabilité sur vos projets, ou d’autres tests non fonctionnels ?
Si vous voulez profiter d’autres tutos pour accompagner votre quotidien de QA, abonnez-vous à notre page LinkedIn !
ODASE est un logiciel permettant de formaliser la réalité du métier, de façon à constituer un référentiel exploitable par une multitude d’applicatifs.
La semaine dernière, nous accueillions Rémi Le Brouster pour nous parler de cette solution, de ses objectifs et du changement de paradigme que cela entraîne pour la définition des règles métier.
Nous nous retrouvons cette semaine pour échanger sur l’intégration de cette solution dans le quotidien des acteurs techniques.
H : Comment les équipes techniques utilisent la représentation du métier définie par ODASE ?
RLB : Avec l’équipe informatique côté client, on définit en parallèle comment ils souhaitent interroger l’outil. On peut par exemple déterminer un ensemble de services pour interroger ODASE, auquel cas on établit alors un contrat d’API. Nous nous occupons alors de réaliser la partie technique qui va proposer les services, transmettre les informations à l’outil, demander le résultat, et le retourner. Ainsi, ni le client, ni le serveur n’ont à connaître le fonctionnement métier.
Afin de décorréler encore plus le technique du métier, et exploiter encore plus l’explicabilité fournie par l’outil ODASE, l’API n’a pas nécessairement besoin de se baser sur la modélisation métier. Nous réalisons alors une ontologie d’intégration, qui fait la conversion entre les concepts métiers et les concepts techniques. Cette correspondance est donc parfaitement compréhensible et documentée, et il n’y a donc pas besoin d’aller investiguer du code pour comprendre le mapping. La passerelle entre le métier et le technique est donc une simple affaire de traduction, très localisée et lisible, et cette indépendance entre le métier et le technique permet de pouvoir avancer sur les deux aspects de façon indépendante.
H : Comment les développeurs accueillent la solution ODASE ? Le fait qu’il y ait besoin de s’interfacer avec un outil tiers complique-t-il leur travail ?
RLB : Les développeurs n’étant pas une entité unique, je suppose que leur accueil de la solution doit varier. Par exemple, je sais qu’en tant que développeur, j’adore me creuser la tête sur des problématiques métiers, définir le périmètre précis et les cas limites, et trouver des algorithmes efficaces, ce que rend obsolète ODASE sur la partie métier, le périmètre et les cas limites étant modélisés en amont, et les résultats étant calculés par l’outil.
A ma connaissance, la plupart des développeurs préfèrent s’occuper de la partie technique, ce qu’ils ont encore plus le loisir de faire grâce à notre outil. Cela leur évite également les frustrations de devoir gérer des spécifications métiers qui ne sont pas toujours limpides, ou de se rendre compte trop tard de la divergence entre la réalité métier et ce qu’ils en avaient compris, ce qui invalide parfois toute leur implémentation.
Concernant le fait de s’interfacer avec ODASE, c’est aussi simple que de s’interfacer avec n’importe quelle autre API ou JAR (selon le choix technique qui a été fait), ce à quoi les développeurs sont généralement habitués. ODASE a donc plus tendance à leur simplifier le travail et à leur éviter des frustrations que l’inverse.
H : Certains développeurs aiment particulièrement apprendre des choses sur le métier, pour comprendre pourquoi ils font ce qu’ils font et donner du sens à leurs efforts. En séparant les règles métier de l’implémentation technique, y a-t-il un risque de frustrer les développeurs qui ont ce type d’appétence ?
RLB : Bien que cela soit possible, s’ils aiment autant s’occuper de problématiques métiers que moi, je pense qu’il reste important pour les développeurs de se familiariser avec le métier, même dans une approche ODASE, ne serait-ce que pour comprendre comment seront utilisées leurs applications. Ainsi, même si on les libère d’une partie de la gestion de ce métier, on ne saurait que trop les encourager à s’y intéresser tout de même (et encourager leurs employeurs à leur y octroyer du temps !). Idéalement, ils pourront alors s’appuyer sur la modélisation ontologique pour approfondir leurs connaissances métiers, afin de proposer et délivrer des applications et fonctionnalités plus pertinentes.
H : La solution ODASE, quand elle est mise en place, semble devenir le point névralgique d’un système d’information… Le SI devient-il « captif » de cette solution ? Les équipes de vos clients deviennent-elles autonomes, ou bien faut-il faire appel aux ontologues d’ODASE pour chaque ajout de règle métier ?
RLB : Dans une approche idéale où le client embrasse intégralement l’approche ODASE, notre solution devient en effet le point névralgique du système d’information, et je pense qu’il est essentiel de comprendre pourquoi, afin de saisir aussi en quoi cela peut aussi être émancipateur, notamment si le client veut changer totalement d’approche plus tard, et refondre son système d’information tout en revenant à une approche classique.
Tout d’abord, je tiens à rappeler que le système d’information ne se limite pas simplement à de l’applicatif, mais inclut aussi l’ensemble des échanges entre les acteurs et leur accès aux informations et documentations.
Dans une approche classique, la définition du métier est morcelée. Elle se trouve dans les connaissances et souvenirs des différents acteurs, dans des brouillons papiers, dans des mails, dans des outils de ticketing, dans des documents à destination du métier, des développeurs, du support ou des utilisateurs, dans le code aussi bien en langage informatique qu’en commentaires, etc. Il devient alors difficile d’interroger ces connaissances, et de savoir quelle source est fiable pour quel aspect. Car une spécification peut être obsolète ou décrire un changement qui n’a pas encore été implémenté, et même un expert avec une excellente connaissance métier peut se tromper, surtout face à des spécifications changeantes; l’interprétation du code par un humain peut passer à côté de certains cas particuliers, et le code lui-même est rarement une source unique, avec de multiples applications intégrant différentes règles, et comme nous venons de le voir, ces règles varient selon la source qui a été choisie en amont.
Dans l’approche ODASE, l’essentiel de notre travail est d’agréger toutes les connaissances de l’ensemble du domaine à modéliser, et de clarifier ce qu’est la vérité métier. A partir de là, nous construisons l’ontologie métier qui servira de référence. L’entreprise obtient ainsi un point unique qui définit toutes les règles de façon parfaitement indépendantes, et qui est interrogeable directement, que ce soit pour valider cette définition métier (plus besoin de tester extensivement le métier dans chaque application, et de devoir comparer les résultats !) ou pour vérifier ce qu’on obtient, d’un point de vue métier, dans telle ou telle situation. Cela signifie aussi que quelqu’un ayant une question métier peut la confronter à une source fiable. Cette source est réellement un point unique en ce que l’ensemble des applications peuvent se baser dessus, car elle ne décrit pas des règles métiers pour une application ou un ensemble d’applications, mais bien les règles métiers de l’ensemble du domaine. Ainsi, même pour une nouvelle application ayant besoin de nouveaux services afin d’interroger certains éléments intermédiaires, il suffit de rajouter techniquement de nouveaux services dans l’interface programmatique d’ODASE, autrement dit de nouveaux points d’entrée ou de nouvelles façons de l’interroger, mais sans toucher aucunement à la partie métier. De même, si c’est la partie métier qui change, sans que cela n’impacte les éléments nécessaires et donc la partie technique, il suffit de modifier les règles métiers, puis de déployer la nouvelle version sur les différentes plateformes intégrant ODASE.
Cette solution a donc ceci d’émancipateur que :
si le client veut remplacer une application faite il y a 15 ans en développant une version plus au goût du jour, il n’a pas besoin de recoder la partie métier, ni de développer de nouveaux algorithmes car le métier est approché d’une nouvelle façon (par exemple, avec l’ordre des questions qui change) ; il peut se concentrer purement sur la partie technique
si le client veut refondre totalement son système d’information et se séparer d’ODASE, pour déléguer l’ensemble de sa gestion à un gros ERP par exemple, le fait d’avoir défini clairement le métier en un point unique et fiable fera que son travail sera grandement facilité, et qu’il y gagnera en coûts, en qualité et en délais.
Pour ce qui est de la modification lorsque l’approche ODASE est en place, passer par nous est tout à fait possible et encouragé, notamment pour garantir la qualité de la représentation ontologique. Toutefois, il est également possible pour le client d’avoir son ou sa propre ontologue qui réaliserait tout ou partie des modifications (on pourrait par exemple former quelqu’un chez le client à cette fin).
Pour ce qui est des modifications classiques (par exemple les prix qui évoluent d’une année sur l’autre), on peut avoir ces éléments stockés dans des sources externes (fichiers Excel, base de données, autre), que le client pourra aisément mettre à jour, afin qu’il n’y ait qu’à relancer les instances du serveur ODASE pour que tout soit pris en compte (dans le cas d’une utilisation en mode serveur).
Enfin, nous sommes actuellement en train de développer un outil pour rendre les ontologies plus accessibles, aussi bien pour les visualiser que pour les modifier.
Il me semble que l’important, comme dans tout domaine, est de faire réaliser les modifications par des personnes dont l’expertise est adaptée à la complexité de la modification à apporter. Et nous visons à permettre que ces personnes puissent être côté client, afin justement d’offrir de l’autonomie et de la maîtrise, aussi bien en faisant progresser l’expertise côté client qu’en simplifiant la réalisation de modifications.
H : Est-il possible d’intégrer ODASE au sein d’un SI ayant une forte proportion de legacy, ou est-ce plutôt une solution à privilégier sur des SI naissants ou du moins récents ?
RLB : Il est évidemment toujours plus confortable de travailler sur des bases neuves ou saines, plutôt que de devoir investiguer l’ancien. Toutefois, ODASE a principalement été utilisé dans des contextes de refonte du legacy de grosses structures, pour lesquelles les approchent classiques avaient déjà échouées plusieurs fois. En effet, l’approche ontologique permet de s’abstraire au fur et à mesure de la nébuleuse qu’est souvent la structure legacy, tout en testant ensuite le fait d’obtenir les mêmes résultats. De plus, là où dans les approches classiques, un petit détail peut invalider toute la structure de l’implémentation, ou forcer des contournements qui s’accumulent rapidement et rendent l’ensemble instable ou non-maintenable, dans l’approche ontologique, il est juste question de rajouter un concept, quelques attributs ou modifier / créer quelques règles supplémentaires. Autrement dit, c’est aussi simple que de mettre à jour de la documentation métier, mais sans avoir à s’encombrer de formulations complexes ni de phrases à rallonge.
H : Quelle est la plus grande réussite d’ODASE à ce jour ?
RLB : ODASE est actuellement utilisé dans le milieu de l’assurance, ce qui est gage de la fiabilité de l’outil et de l’intérêt de l’approche. C’est une très belle référence pour nous, et notamment de notre capacité à modéliser avec précision des ensembles métiers particulièrement complexes.
H : Comment ODASE vise à se développer dans les années à venir ?
RLB : Nous sommes en train de créer notre propre outil qui permettra de visualiser et d’éditer les ontologies. L’objectif est que l’ensemble devienne plus simple, intuitif, pratique et confortable d’utilisation. Les étapes clefs sont :
la visualisation de l’ontologie (concepts et règles), en permettant de construire et enregistrer des vues qui affichent seulement les concepts qui leurs sont pertinents,
l’édition simple d’attributs ou de règles, pour permettre au métier de gagner de l’autonomie sur ces aspects,
l’ajout de règles,
puis de rajouter progressivement différents outils qui sont pratiques ou nécessaires pour les ontologues.
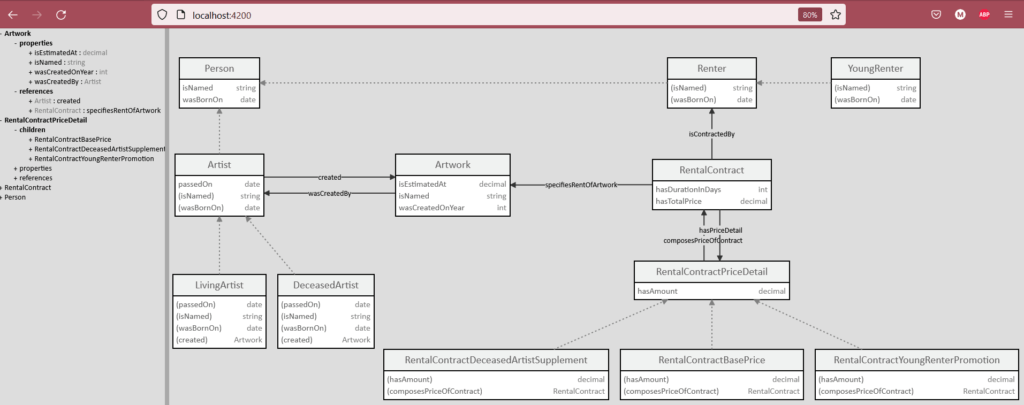
Etat actuel de l’outil de visualisation des ontologies.
Tout cela se fera évidemment en prenant en compte les retours des utilisateurs et utilisatrices, et avec pour objectif d’avoir avant tout un outil simple pour le métier, et ensuite seulement un outil pratique pour les ontologues, ce qui passera vraisemblablement par le fait de conditionner l’affichage de certains éléments à des options.
Merci à Rémi Le Brouster pour cette présentation détaillée du fonctionnement d’ODASE !
On vous partage
notre expertise !
Abonnez-vous à notre newsletter pour suivre toute l’actualité du test !