Il était une fois une entreprise qui avait un système d’information. Dans ce système prospéraient différents applicatifs, plus ou moins récents et plus ou moins bien maintenus. Même s’ils formaient un ensemble hétéroclite et souvent assez bancal, tous ces applicatifs avaient bon nombre de points communs. Premièrement, ils parlaient souvent des mêmes choses (de « clients », de « contrats », de « factures », de « produits »…) Deuxièmement, ils étaient mal documentés, vraiment très mal documentés. Troisièmement, ils faisaient l’objet d’une lutte sans relâche : les équipes techniques refusaient de porter la connaissance fonctionnelle de ces outils, et les équipes fonctionnelles refusaient d’admettre que les équipes techniques ne connaissaient pas leurs règles de gestion.
Les problèmes de cette entreprise étaient aussi épineux que désespérément ordinaires.
Aujourd’hui, notre invité Rémi Le Brouster est avec nous pour parler d’une solution, nommée ODASE, visant à résoudre les problèmes de cette entreprise.
Hightest : Bonjour Rémi ! Tu es directeur technique adjoint de la solution ODASE, et tu étais précédemment développeur. Au cours de ta carrière, as-tu déjà été impliqué au sein d’une entreprise comme celle dont on parlait à l’instant ?
Rémi Le Brouster : Bonjour Hightest ! Ca m’est en effet arrivé, et c’est aussi pour cela que je me suis beaucoup investi pour rejoindre ODASE. J’ai été dans une entreprise très orientée métier, avec une problématique de migration d’un ancien logiciel vers un nouveau, où il fallait donc recouvrer et réimplémenter les règles de gestion. L’ancienne application datant, les spécialistes des différentes parties du métier n’étaient plus tous là, et ceux qui les avaient remplacés étaient parfois contraints de nous répondre de refaire pareil, faute de documentation métier suffisante, ce qui impliquait de fouiller dans le code…
Et évidemment, en voulant réimplémenter les comportements métiers, qu’ils soient historiquement bien réalisés ou fautifs, les développeurs introduisaient aussi de nouveau bugs, ce qui est le lot de presque tout développement.
Je pense également que ce genre de problématiques arrive dans beaucoup d’entreprises, mais avec le chef de service informatique / responsable R&D qui fait le tampon entre le métier et les développeurs, ce qui invisibilise le problème pour ces derniers.
H : Quel est l’objectif d’ODASE ?
RLB : L’objectif d’ODASE est de séparer intégralement le métier de la technique. Le métier doit être garant de la partie métier, tout comme les développeurs doivent se concentrer sur le code et ses problématiques techniques. Pour cela, il faut un outil capable de faire la passerelle entre les deux, se basant donc sur la documentation métier, et qui soit interrogeable via des applications, en leur retournant les résultats calculés souhaités. Cela permet aussi que cette documentation métier soit nécessairement à jour et en phase avec les applications.
Habituellement, dans les systèmes d’information :
• Les spécifications métier peuvent être éparpillées, redondantes, incomplètes, incorrectes, ambiguës.
• Le nombre de lignes de code peut être très important.
• Les changements dus au métier affectent toute l’implémentation.
• Ces changements métiers sont rarement bien documentés, bien qu’ils devraient l’être.
• Le debugging porte tant sur la technique que sur le métier puisque les experts métier n’ont pu intervenir en amont de l’implémentation.
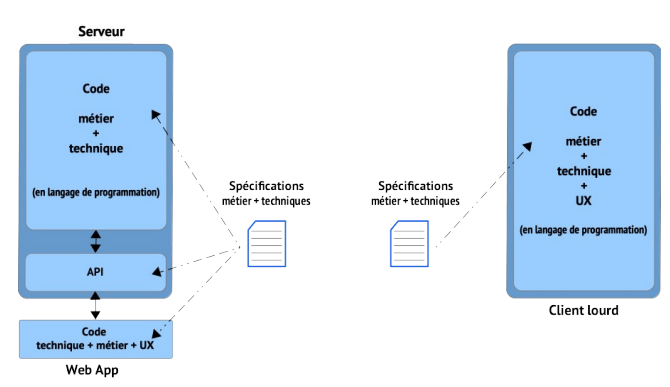
Mettons qu’un SI ait un client lourd et une appli web, voici à quoi cela ressemble classiquement :
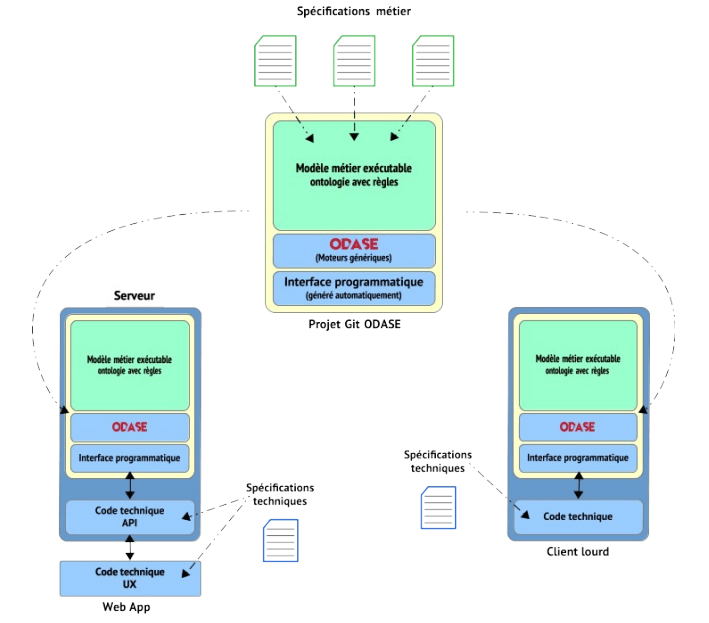
Avec ODASE, un certain nombre de choses changent.
• Le métier et la technique sont clairement séparés.
• Le métier est défini en un point unique (l’ontologie et les règles associées).
• L’ontologie est validée en amont avec les experts métier grâce aux explications.
• Il ne peut pas y avoir de contradictions entre le métier et l’implémentation technique.
• Le nombre de lignes de code est très réduit (il ne couvre que la technique).
• Les changements métier ne portent que sur l’ontologie.
• L’ontologie est une documentation de la vérité métier, toujours à jour.
• Les tests de type informatique ne portent que sur la technique.
On se retrouve donc avec une configuration comme suit :
H : Comment fonctionne ODASE ?
L’ontologie se découpe principalement en une représentation des concepts, de leurs attributs et de leurs liens entre eux, et en une spécifications des règles métiers qui définissent l’interaction entre ces différents éléments. Ces règles métiers sont des propositions logiques, ce qui signifient qu’elles sont tout le temps vraies, et qu’il n’y a aucune notion d’ordre entre elles.
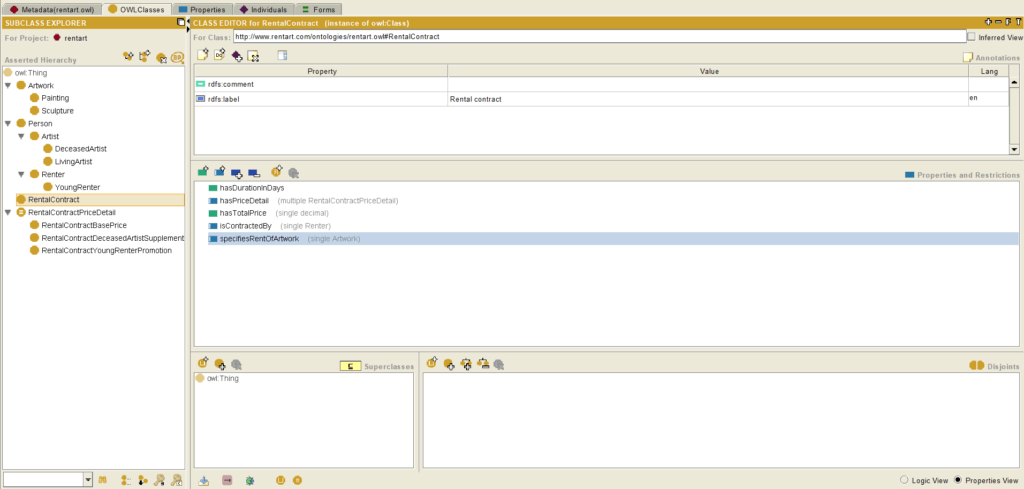
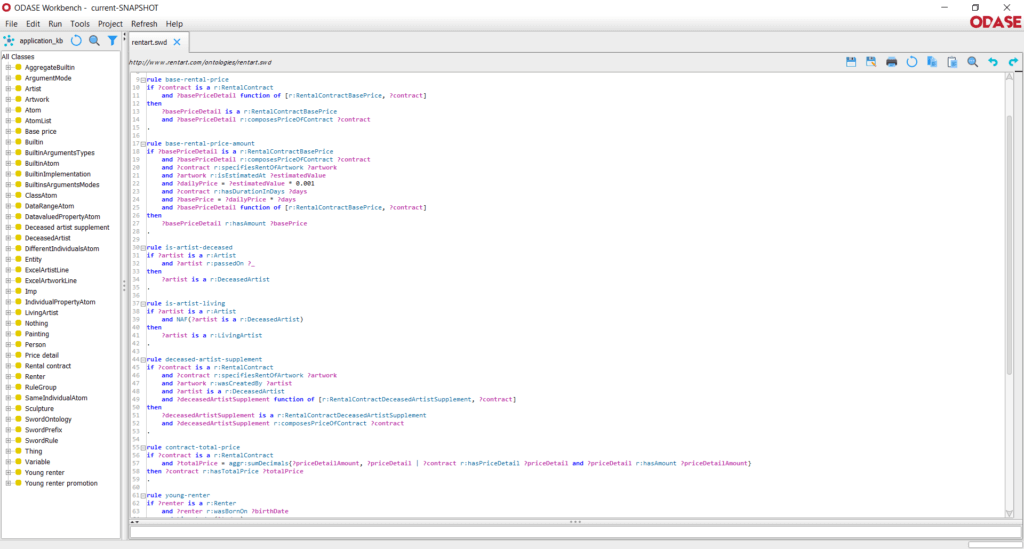
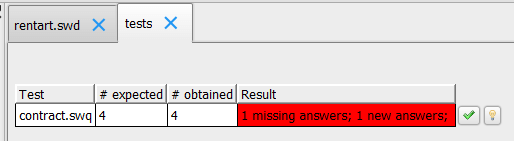
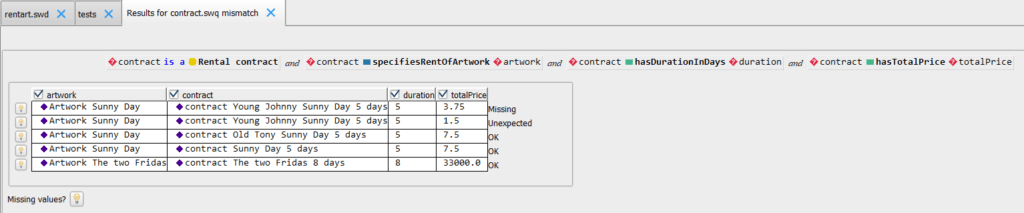
H : Pour parler en langage de testeur, ODASE permet de réaliser une analyse statique automatisée du référentiel métier… C’est top !
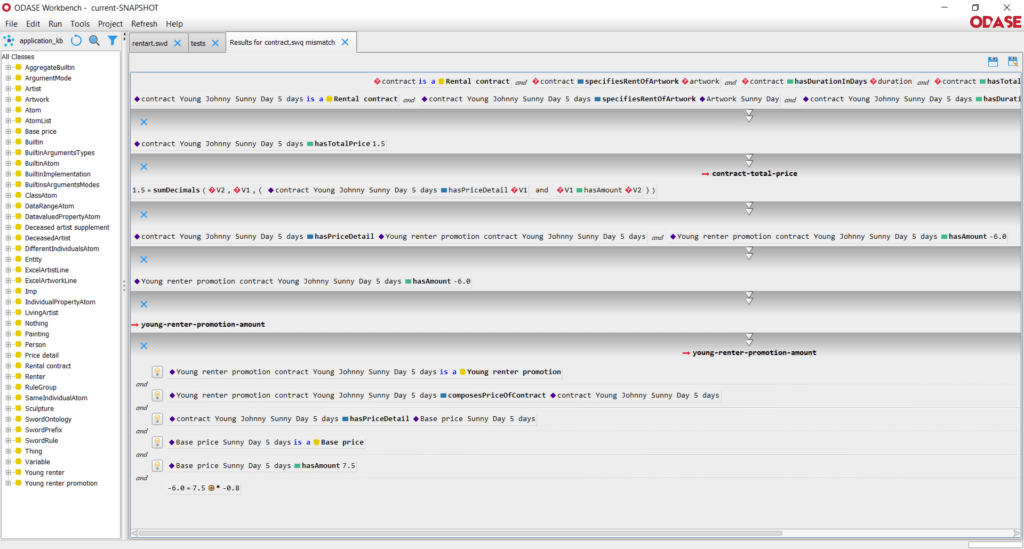
On obtient ainsi une représentation du métier spécifique, compréhensible et validée par le métier, que l’on peut faire évoluer facilement.
H : Mettons qu’ODASE soit installé dans une entreprise où travaillent des testeurs. Quels sont les changements à prévoir dans le quotidien de ces testeurs ? Quelle interaction avec ODASE prévoyez-vous ?
RLB : Tout dépend du contexte. Par exemple, si les testeurs ont une bonne connaissance métier, il peut être pertinent pour l’ontologue d’échanger avec eux, pour essayer d’en extraire de la connaissance métier, en complément des autres sources disponibles.
Les testeurs peuvent également valider, dans les applications techniques, que les résultats obtenus sont les bons. En effet, même si le métier est juste, si les applications qui interrogent ODASE ne fournissent pas les bonnes informations, c’est-à-dire s’ils envoient une mauvaise valeur ou omettent une variable nécessaire dans la construction du JSON de la requête envoyée (dans le cas d’une architecture client/serveur), le résultat sera erroné. Dans cette continuité, les testeurs peuvent également porter leur attention sur l’évolution de l’API, par exemple suite à l’évolution des informations nécessaires d’un point de vue métier, pour tester que ces évolutions ont bien été prises en compte techniquement dans les applications.
H : Quels types de profils deviennent ontologue ?
RLB : Il s’agit en général de docteur·e·s en informatique spécialisé·e·s dans la représentation des connaissances.
H : L’approche d’ODASE rappelle celle du BDD (behavior driven development). Comment se situe ODASE vis-à-vis des outils de BDD ?
RLB : Notre approche étant basée sur des propositions logiques toujours vraies, elle est fondamentalement orientée état. Ainsi, il n’y a pas du tout la notion de « When » des scénarios « Given … When … Then … ». Un état partiel est transmis à ODASE, et ODASE complète le reste. Le comportement, lui, est implémenté au niveau de l’applicatif, de façon technique.
De même, nous cherchons à représenter la réalité métier, de façon indépendante des fonctionnements attendus. Ainsi, ce ne sont pas des tests à passer, ni une volonté stratégique, commerciale ou produit quelconque qui vont régir l’ontologie. La réalisation de l’ontologie est avant tout une quête de la plus pure réalité métier. Les choix ontologiques sont uniquement faits en ce sens. Par contre, on peut s’adapter pour modéliser une partie de cette réalité métier avant une autre.
H : Merci Rémi pour ton temps et tes explications !
Retrouvez l’intégration d’ODASE dans le quotidien des équipes techniques dans la deuxième partie de cet article !
Découvrir ODASE, partie II : intégrer les ontologies dans le SI
PS : Si vous souhaitez en savoir plus, voici l’adresse d’ODASE : info@odase.io