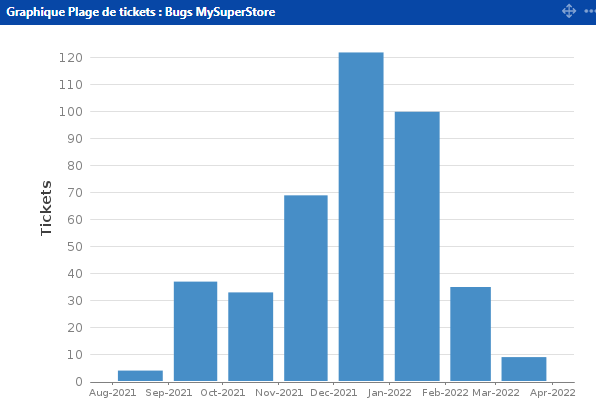
Des logs Selenium lisibles pour tous
Nous parlions de ce syndrome dans un précédent article ; le testeur chargé de l’automatisation des tests est parfois le seul à comprendre ses logs (on a appelé ça la logopathie). Cela réduit l’utilité des automates qui se retrouvent auréolés d’un mystère inutile.
Pour poursuivre dans cette série de bonnes pratiques d’automatisation des tests, nous vous proposons aujourd’hui plusieurs approches pour améliorer vos logs Selenium, sans le moindre framework hipster, juste avec du bon vieux Java. Nous utiliserons un système de logging des plus classiques, à savoir Log4J2, réglé sur la verbosité « INFO ». Libre à vous ensuite d’exploiter ces logs dans l’outil de reporting de votre choix (Allure par exemple). Allez, c’est parti !
Le script Selenium niveau débutant : rien que les logs d’erreur par défaut
Exemple de script Selenium
Voici un script très optimiste qui vérifie sur un célèbre site de vente calédonien que la première Peugeot 107 à vendre coûte 10 000 francs pacifiques ou moins.
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class TestLogs {
WebDriver driver;
@Before
public void setUp() {
System.setProperty("webdriver.chrome.driver", "webdrivers/chromedriver.exe");
driver = new ChromeDriver();
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
}
@Test
public void testLogs(){
driver.get("https://voitures.nc/");
WebElement element = driver.findElement(By.id("recherche"));
element.sendKeys(Keys.DELETE);
element.sendKeys("107");
driver.findElement(By.cssSelector("input[value='OK']")).click();
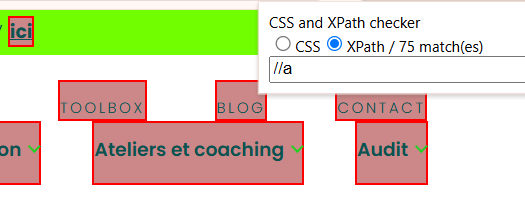
driver.findElement(By.xpath("//a[contains(., 'Offre')]")).click();
driver.findElement(By.xpath("(//table[contains(@href, 'detail_annonce')]//img)[1]")).click();
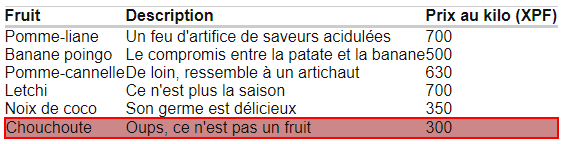
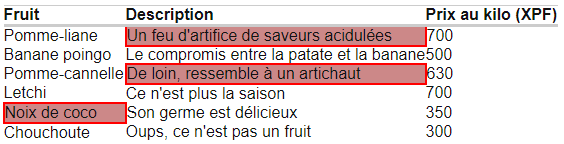
Assert.assertTrue("ERREUR : le prix affiché est supérieur à " + 10000, Integer.parseInt(driver.findElement(By.xpath("//div[contains(@id, 'detail')]")).getText(). split("Prix : ")[1].split(" F cfp")[0]. replaceAll("\s+", "")) < 10000);
}
@After
public void tearDown(){
driver.quit();
}
}

Problèmes du script Selenium
Comment on va maintenir ça ?
Ce qui saute déjà aux yeux avec ce script, c’est qu’il enfreint la règle de séparation du test et des objets pages. Si le Page Object Model ne vous éveille aucun souvenir, allez jeter un œil à cet article.
Ecrivez tous vos tests de cette façon et vous obtiendrez un magnifique plat de spaghettis impossible à maintenir !
Mais ce qui nous dérange le plus ici, c’est qu’en cas d’échec, on n’aura pas beaucoup d’informations…
Exemples de logs cryptiques
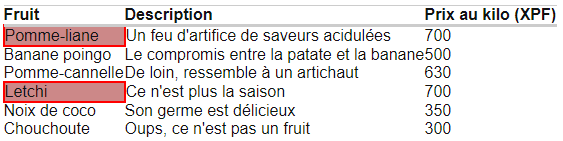
Si la première Peugeot 107 affichée coûte plus de 10 000 XPF, on se retrouvera avec ces logs :
java.lang.AssertionError: ERREUR : le prix affiché est supérieur à 10000
at org.junit.Assert.fail(Assert.java:88)
at org.junit.Assert.assertTrue(Assert.java:41)
at TestLogs.testLogs(TestLogs.java:33)
// [...] Et encore plein de lignes qu'on vous épargnera
Et rien avant ce problème d’AssertionError. Là, on a bien le test en tête, on comprend ce qui s’est passé. Cela dit, dans 6 mois, on ne saura plus ce qui était censé coûter 10 000 XPF maximum, sur quel site, etc…
Et si jamais le bouton de recherche n’est pas trouvé, les logs remontent cela, ce qui est moins parlant :
*** Element info: {Using=id, value=recherche}
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
// [...]
Heureusement que le champ de recherche a un id et que celui-ci est explicite, mais ce n’est pas toujours le cas… Par exemple, sur le site d’Amazon, le champ de recherche a pour id « twotabsearchtextbox », ce qui est un peu moins compréhensible.

Le script Selenium niveau supérieur : chaque étape est logguée
Dans le bloc ci-dessous, le test a bien changé, il répond maintenant au pattern du Page Object Model. Il est beaucoup plus court, et surtout il est plus lisible grâce à des noms de méthodes explicites. Son setup et son teardown sont remontés d’un cran et se trouvent dans une nouvelle classe, « AbstractTest », dont hérite le test ; de cette façon, ils pourront être utilisés dans tous les tests.
La page invoquée, VoituresNcPage, a également son propre objet, qui contient ses propres méthodes.
Et les méthodes de bas niveau utilisées dans l’objet VoituresNcPage sont elles-mêmes remontées dans une classe mère, AbstractPage.
De cette façon, on respecte les célébrissimes principes DRY (don’t repeat yourself) et KISS (keep it super simple).
Le nouveau test Selenium
import org.junit.Test;
import pages.VoituresNcPage;
import utils.AbstractTest;
public class TestLogs extends AbstractTest {
@Test
public void testLogs() {
accesURL("https://voitures.nc/");
VoituresNcPage voituresNCpage = new VoituresNcPage(this);
voituresNCpage.rechercherProduit("107");
voituresNCpage.accesAuxOffres();
voituresNCpage.classerParPrix();
voituresNCpage.deplierAnnonceNumero(1);
voituresNCpage.verifierPrixInferieurOuEgalA(10000);
}
}
Les méthodes de haut et de bas niveau
Toutes les méthodes de bas niveau donnent lieu à une ligne de log. Les méthodes de vérification donnent lieu à un log en cas d’échec. Un exemple avec la méthode qui permet de classer les produits par prix :
// Dans VoituresNcPage. On trouve les objets et les méthodes spécifiques à la page.
private final By BTN_CLASSER_PAR_PRIX = By.xpath("(//a[contains(@href, 'orderBy=prix')])[1]");
public void classerParPrix(){
clickElement(BTN_CLASSER_PAR_PRIX);
}
[...]
// Dans AbstractPage. On trouve des méthodes qui pourraient servir à toutes les pages web du monde. Des vérifications sont faites avant chaque interaction, pour vérifier que l'élément concerné est bien présent, et logger ce problème le cas échéant.
protected int timeOut = 5; // Cette valeur sert à configurer combien de temps un élément doit être "attendu" avant qu'on ne considère qu'il est absent de la page.
protected void clickElement(By by) {
logger.info("Clic sur l'élément '" + getPathFromBy(by) + "'"); // Un premier log de bas niveau
assertElementPresent(by);
driver.findElement(by).click();
}
protected String getPathFromBy(By by){
return by.toString().split(": ")[1]; // On a choisi de faire ce split pour gagner en concision, mais vous aurez peut-être envie de conserver le type de sélecteur.
}
public void assertElementPresent(By by) {
if(!isElementPresent(by)){
logger.error("ERREUR : '" + getPathFromBy(by) + "' n'a pas été trouvé(e) sur la page."); // Un deuxième log de bas niveau
}
assertTrue(isElementPresent(by));
}
public boolean isElementPresent(By by) {
boolean isElementPresent = false;
int time = 0;
while (!isElementPresent && time < timeOut) {
if (isElementPresentNow(by)) {
isElementPresent = true;
} else {
isElementPresent = false;
}
sleep(1);
time++;
}
return isElementPresent;
}
// Un petit "hack" qui permet d'ignorer temporairement le timeout.
public boolean isElementPresentNow(By by) {
driver.manage().timeouts().implicitlyWait(0, TimeUnit.MILLISECONDS);
boolean isElementPresent = (driver.findElements(by).size() != 0);
driver.manage().timeouts().implicitlyWait(timeOut, TimeUnit.MILLISECONDS);
return isElementPresent;
}
Les nouveaux logs
Désormais, les logs ressemblent maintenant à ça :
Accès à l'URL https://voitures.nc/
Renseignement du texte '107' dans l'élément 'recherche'
Clic sur l'élément 'input[value='OK']'
Clic sur l'élément '//a[contains(., 'Offre')]'
Clic sur l'élément '(//a[contains(@href, 'orderBy=prix')])[1]'
Clic sur l'élément '(//table[contains(@href, 'detail_annonce')]//img)[1]'
ERREUR : le prix affiché est supérieur à 10000
On comprend un peu mieux ce qui s’est passé. Un testeur n’ayant pas lui-même écrit ce test peut, en se concentrant un peu, retracer le scénario. Ca peut suffire, mais une fois encore, si on veut partager nos logs, on se retrouve dépendants de la clarté des sélecteurs.

Le script Selenium niveau big boss : des logs compréhensibles par tout le monde
Jusqu’à maintenant, rien de bien original. Mais nous voulons maintenant aller un peu plus loin, en permettant à toute personne de comprendre parfaitement les logs, sans avoir besoin du moindre bagage HTML et CSS. On pense par exemple aux intervenants fonctionnels qui auraient besoin de lancer les tests automatisés en autonomie et d’analyser leurs résultats. Chaque étape sera détaillée en langage naturel, joliment et proprement, aussi bien que si on les avait décrites nous-mêmes. A ce stade, les logs du test seront aussi clairs que possible, et surtout à peu de frais. Ca vend du rêve ? Bien sûr que non, car c’est gratos ! C’est parti !
Ce que nous n’allons pas faire
Une solution serait d’étoffer chaque méthode de la classe VoituresNcPage par un log spécifique.
public void classerParPrix(){
logger.info("Classement des produits par prix");
clickElement(BTN_CLASSER_PAR_PRIX);
}
Pourquoi pas, si vous avez le temps d’écrire ces logs et que vous vous engagez à les maintenir. Mais on va partir du principe que vous voulez gagner du temps et faire au plus simple.
Notre proposition : bye bye le By
Pour identifier et interagir avec les éléments de la page (boutons, liens, champs…), Selenium propose une classe dédiée : By. Elle permet de les sélectionner par xpath, nom de classe CSS, sélecteur CSS, id, texte de lien hypertexte (ou partie de ce texte), name, balise html…
private final By BTN_CLASSER_PAR_PRIX = By.xpath("(//a[contains(@href, 'orderBy=prix')])[1]");
Mais nous allons laisser tomber ce bon vieux By, ou plutôt l’améliorer pour la beauté de vos logs. Nous allons passer par une nouvelle classe, que nous allons appeler « Selecteur ».
// Dans AbstractPage
public class Selecteur {
public String nom; // C'est cette variable qui va contenir la description de chaque élément en langage naturel !
public By chemin;
public Selecteur(String nom, By chemin){
this.nom = nom;
this.chemin = chemin;
}
public String getNom(){
return nom;
}
public By getChemin(){
return chemin;
}
}
Remplacement des By par des Selecteurs
Dans les méthodes
Maintenant, on va modifier nos méthodes de bas niveau qui utilisent la classe By, en la remplaçant par la classe Selecteur. Par exemple :
// Dans AbstractPage
protected void clickElement(Selecteur selecteur) {
logger.info("Clic sur " + selecteur.getNom());
assertElementPresent(selecteur);
driver.findElement(selecteur.getChemin()).click();
}
protected String getPathFromBy(Selecteur selecteur){
return selecteur.getChemin().toString().split(": ")[1];
}
public void assertElementPresent(Selecteur selecteur) {
if(!isElementPresent(selecteur.getChemin())){
logger.error("ERREUR : " + selecteur.getNom() +
" n'a pas été trouvé(e) sur la page. " +
" (sélecteur : '" + getPathFromBy(selecteur) + "')");
}
assertTrue(isElementPresent(selecteur.getChemin()));
}
[...]
Dans les objets Page
A cette étape, il reste maintenant à transformer les sélecteurs « By » qui se trouvent dans vos objets pages. Et en premier paramètre, à vous de jouer : vous devez décrire, du mieux que vous pouvez, ce qu’est l’objet d’un point de vue fonctionnel ; à quoi il sert. Vous devez le faire concisément, mais surtout précisément, pour éviter toute ambiguïté.
private final Selecteur BTN_CLASSER_PAR_PRIX = new Selecteur("le bouton permettant de classer les articles par prix", By.xpath("(//a[contains(@href, 'orderBy=prix')])[1]"));
Résultats du refacto
Une fois que c’est fait, on reteste pour voir à quoi ressemblent maintenant les logs !
Accès à l'URL https://voitures.nc/
Renseignement du texte '107' dans le champ de recherche
Clic sur le bouton permettant de valider la recherche
Clic sur le lien vers les offres
Clic sur le bouton permettant de classer les articles par prix
Clic sur le bouton permettant de déplier l'annonce n°1
ERREUR : le prix affiché est supérieur à 10000
Là, on a toutes les informations et on comprend tout. Et que se passe-t-il si on regarde, comme au début de l’article, ce que montrent les logs si jamais le champ de recherche a disparu ?
Accès à l'URL https://voitures.nc/
Renseignement du texte '107' dans le champ de recherche
ERREUR : le champ de recherche n'a pas été trouvé(e) sur la page. (sélecteur : 'recherche')
Bien, on comprend aussi.
[BONUS] Le script Selenium niveau serial-bugkiller : le générateur de rapport de bug
Tels quels, vos logs expliqueront ce qu’on fait les automates de test. En changeant peu de choses à la proposition précédente, vos logs détailleront les étapes à suivre pour reproduire leur comportement. Et du coup, vous mettrez un peu moins de temps à rédiger vos rapports de bugs, car votre partie « Etapes pour reproduire » sera déjà écrite par votre automate, et n’importe qui pourra la comprendre, quel que soit son niveau de connaissance du projet.
Rendez-vous sur l'URL https://voitures.nc/
Renseigner le texte '107' dans le champ de recherche
Cliquer sur le bouton permettant de valider la recherche
Cliquer sur le lien vers les offres
Cliquer sur le bouton permettant de classer les articles par prix
Cliquer sur le bouton permettant de déplier l'annonce n°1
ERREUR : le prix affiché est supérieur à 10000
Vous n’aurez peut-être pas besoin de ce type de logs, ceux de l’étape précédente vous suffiront peut-être, mais cela vous donnera peut-être d’autres idées d’utilisations des logs.
Conclusion
Pour conclure, nous pourrions dire qu’il est illusoire de rechercher une Peugeot 107 à 10 000 XPF ou moins.
Mais aussi, que vos logs sont un atout dont vous pouvez tirer une grande valeur, et à peu de frais. Ce que nous avons exploré dans cet article n’est qu’un exemple parmi d’autres de valorisation des logs.
Et vous, comment utilisez-vous vos logs de tests automatisés ? Comment les avez-vous améliorés au fil du temps ?
Crédit image
L’image de couverture est une reprise de Miss Auras (Le Livre rouge), Sir John Lavery (1856-1941).


 Aaaaah on les veut toutes !!!!!!
Aaaaah on les veut toutes !!!!!!