Note préalable : cet article date de 2017. Depuis, Protractor a atteint la fin de sa vie. Merci à lui et surtout aux personnes qui ont contribué à cet outil !
Le problème du tas
Au commencement d’un projet de test, surtout si celui est censé n’être qu’un POC ou un tout petit projet, on a tendance à coder les jeux de données en dur dans le script et à télécharger les librairies au fil de l’eau. Trèèès bieeeen… tant que ça ne dure pas ! Car comme écrivait Beckett en 1957 :
Les grains s’ajoutent aux grains, un à un, et un jour, soudain, c’est un tas, un petit tas, l’impossible tas.
Un tas qu’il n’est pas facile à gérer quand on revient sur le projet quelques mois plus tard, ou qu’un collègue doit travailler dessus pendant qu’on est en vacances à Ouvéa.
Aujourd’hui donc, on vous donne des pistes pour gérer les jeux de données et les librairies de votre projet. Cet article est le deuxième de notre série sur les test Protractor :
- Installation et exemple de script
- Gestion des jeux de données et des dépendances du projet
- Structure d’un projet industrialisé
Quels problèmes souhaitons-nous éviter ?
Pour comprendre l’intérêt de ce qui va suivre, penchons-nous sur ce petit texte :
« Vous a-t-on déjà parlé de la Nouvelle Calédonie, un archipel du Pacifique dont la capitale est Nouméa, qui compte quelque 300 000 habitants et dont la devise est le franc pacifique ? Recherchez le taux de change actuel entre le franc pacifique et l’euro. La Nouvelle Calédonie, un archipel du Pacifique dont la capitale est Nouméa, qui compte quelque 300 000 habitants et dont la devise est le franc pacifique, possède un lagon exceptionnel, classé au patrimoine mondial de l’Unesco. Recherchez depuis quand c’est le cas. L’oiseau fétiche de la Nouvelle Calédonie, un archipel du Pacifique dont la capitale est Nouméa, qui compte quelque 300 000 habitants et dont la devise est le franc pacifique, est le cagou, un oiseau à huppe presque incapable de voler. Trouvez d’où lui vient son nom. Il est très agréable de vivre en Nouvelle Calédonie, un archipel du Pacifique dont la capitale est Nouméa, qui compte quelque 300 000 habitants et dont la devise est le franc pacifique, cependant il faut tenir compte du fait que ce coin de paradis se trouve à quelque 16 000 kilomètres de la métropole. Vérifiez que Nouméa et la ville française la plus éloignée de Paris. »
Du point de vue du lecteur, ce texte est totalement redondant et illisible. Vous auriez préféré ne lire chaque information qu’une seule fois, et votre cerveau aurait rattaché chacune de ces données à la variable « Nouvelle Calédonie », qu’il possédait peut-être déjà. Cela vous aurait permis de vous concentrer davantage sur les questions.
Si l’on se place du point de vue de l’auteur, au prochain recensement de la Nouvelle Calédonie, il faudra qu’il remplace chaque occurrence de « 300 000 » par, peut-être, « 320 000 » ou « 350 000 ». Au fil du temps, le texte s’allongeant les mises à jour deviendront de plus en plus fastidieuses.
Ce texte est comme un projet de test mal architecturé, qui en un seul bloc fournit une multitude d’informations souvent répétitives sur le SUT, et sollicite dans la foulée des vérifications.
La bonne pratique
Autant que possible, nous allons donc prendre soin de séparer les moments où :
- on configure les données du test,
- on donne des informations sur le SUT (identificateurs d’objets, descriptions de page),
- on effectue des vérifications (tel élément est présent, tel texte est visible).
Gestion des données de test avec jasmine-data-provider
En automatisation des tests, une bonne pratique consiste à séparer les données du test et les scripts d’exécution. Cela augmente la maintenabilité des tests et permet aussi à tout un chacun de mettre à jour le jeu de données, sans avoir à connaître l’architecture du projet sur le bout des doigts.
Qui plus est, cela permet d’alimenter un même script avec X jeux de données, et d’augmenter la couverture des tests à moindre coût .
Avec Protractor, le plugin jasmine-data-provider par exemple permet d’implémenter cette séparation données/scripts.
Pour l’utiliser dans l’exemple précédent, nous allons suivre trois étapes.
1) Importer jasmine-data-provider
A la racine de votre projet, téléchargez le package jasmine-data-provider :
npm install jasmine-data-provider --save-dev
Un dossier node_modules va se créer à la racine de votre projet et contenir le paquet voulu.
Il existe une autre manière de procéder, que nous verrons plus tard. En attendant, veillez juste à ne pas répertorier le dossier node_modules dans votre outil de versionning. Par exemple, si vous utilisez Git, ajoutez la ligne « node_modules/ » dans votre fichier .gitignore et votre projet restera léger comme une plume.
2) Modifier le fichier de configuration
Ici, il n’y a qu’une ligne à ajouter :
framework: 'jasmine2'
3) Créer un fichier de données
Ce fichier doit être au format .js. Appelons-le jeux-de-donnees-demo.js.
Ici, nous avons 2 séries de jeux de données. La première comprend 5 jeux de données avec chacun 1 paramètre : le prénom. Outre les caractères spéciaux courants dans la langue française, nous voulons savoir si d’autres caractères spéciaux (ici, arabes et chinois) apparaissent correctement, et si les scripts Javascript sont traités comme du simple texte.
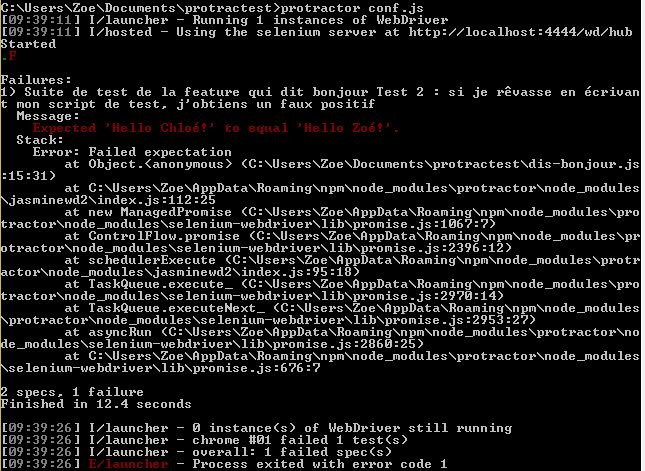
La deuxième série, destinée à générer un faux positif, a 2 paramètres : le prénom saisi et le prénom attendu.
'use strict';
module.exports = {
prenoms: {
'ASCII': { prenom: 'Robert' },
'Caractères spéciaux français': { prenom: 'Rôbértà' },
'Caractères spéciaux arabes': { prenom: 'صباح الخير' },
'Caractères spéciaux chinois': { prenom: '安' },
'Script': { prenom: "<script type='text/javascript'>alert('Faille 1');</script>"}
},
faux_positif: {
'Fail !': { prenomSaisi: 'Chloé', prenomVoulu: "Zoé" }
}
}
La mention « use strict » est facultative mais conseillée, car elle garantit que le code est bien formé.
4) Exploiter le fichier de données au sein du script de test Protractor
Nous allons un peu transformer le script de l’article précédent :
var donnees = require('./jeu-de-donnees-demo.js');
var using = require('jasmine-data-provider');
describe("Suite de test de la feature qui dit bonjour", function() {
beforeEach(function () {
browser.get(browser.baseUrl);
});
using(donnees.prenoms, function (data, description) {
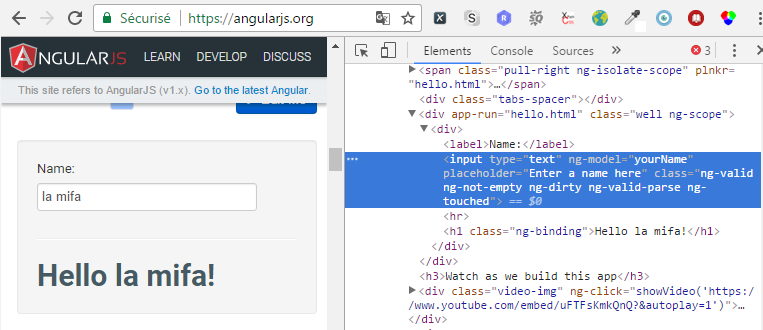
it("Chaîne de type " + description, function () {
element(by.model('yourName')).sendKeys(data.prenom);
var message= element(by.xpath("//div[contains(@class, 'well')]//h1"));
expect(message.getText()).toEqual('Hello ' + data.prenom + '!');
});
});
using(donnees.faux_positif, function(data, description) {
it("Si je rêvasse en écrivant mon script de test, j'obtiens un faux positif", function() {
element(by.model('yourName')).sendKeys(data.prenomSaisi);
var message= element(by.xpath("//div[contains(@class, 'well')]//h1"));
expect(message.getText()).toEqual(data.prenomVoulu);
});
});
});
Au début du script, on indique que l’on souhaite utiliser jasmine-data-provider, ainsi que le chemin de notre fichier de données.
Pour le premier cas de test, on déclare qu’on va utiliser la série de données intitulée « prenoms », ce qui nous donne accès aux données (« data ») ainsi qu’au nom de chaque jeu de données (« description »). Pour accéder au paramètre « prenom », il suffit d’indiquer « data.prenom ».
Nous avons également choisi de factoriser, entre les deux cas de test, la première étape, à savoir la consultation de l’URL de base du projet :
beforeEach(function () {
browser.get(browser.baseUrl);
});
Au lancement, la même méthode de test sera lancée autant de fois qu’il y a de jeux de données, avec les paramètres correspondants.
Gestion des données de test avec csv-parse
NB : cette section a été ajoutée en décembre 2020.
Si vous préférez exploiter des fichiers CSV, c’est possible aussi en utilisant le module csv-parse.
Commencez par installer ce module avec la ligne de commande suivante :
npm install csv-parse
Dans cet exemple, nous utiliseront un fichier de jeu de données nommé donnees.csv, et qui contiendra les informations suivantes :
login,password,prenom
admin,M0t2p@sseAdmin,Amira
user,M0t2p@sseUser,Boniface
Nous allons appeler ce jeu de données dans le script suivant, qui vérifie qu’à l’authentification sur un certain site web, on se retrouve sur une page où l’on voit la mention « Bonjour » suivie du prénom de l’utilisateur.
'use strict';
let fs = require('fs'); // fs pour file system. Il n'y a rien besoin d'installer pour utiliser cela.
const parse = require('csv-parse/lib/sync');
let a = fs.readFileSync('donnees.csv');
const testdata = parse(a, {
columns: true,
skip_empty_lines: true
})
describe('Suite de tests d'authentification', function () {
for (let i of testdata) {
it('Connexion et affichage de la page d'accueil', async function () {
browser.get(browser.baseUrl)
console.log("Saisie du login : " + i.login)
element(by.id('input-login-username')).sendKeys(i.login)
console.log("Saisie du mot de passe : " + i.password)
element(by.id('input-login-password')).sendKeys(i.password)
element(by.id('button-login-submit')).click()
console.log("Vérification de l'affichage des salutations")
var message= element(by.xpath("//div[contains(@class, 'h1')]"))
expect(message.getText()).toEqual('Bonjour ' + i.prenom)
});
}
});
Et voilà !
(Fin de l’EDIT)
Gestion des dépendances avec le package.json
Nous venons de voir comment rapidement ajouter la dernière version de jasmine-data-provider. Mais cette façon de procéder n’est pas la meilleure au sein d’un projet industrialisé, où certaines problématiques se posent :
- Comment alléger le projet de tests Protractor ?
- Comment faire en sorte que tous les membres de l’équipe utilisent la même version de jasmine-data-provider ?
C’est à ce moment qu’intervient le fichier package.json. Ce fichier, que l’on va placer à la racine du projet, contient une liste de tous les packages dont a besoin le projet. Si vous venez de l’univers Maven, cela devrait vous rappeler le pom.xml, ou le build.gradle si vous venez de la constellation Gradle.
Et la bonne nouvelle, c’est que npm propose une façon rapide de générer un fichier package.json ! Pour ce faire, placez-vous à la racine de votre projet, et tapez la commande :
npm init
Une série de questions sur votre projet vous est posée. Des réponses par défaut vous sont proposées. Pour un petit projet tel que nous venons d’en créer, l’opération dure moins d’une minute.
La valeur entrée pour le « main » dans l’utilitaire n’importe pas du tout ici. Vous pourrez la supprimer de votre package.json.
Pour le « test command », entrez la commande suivante :
node_modules/.bin/protractor src/conf-demo.js
A ce stade, le fichier généré ressemble à cela :
{
"name": "hightest-demo",
"version": "1.0.0",
"description": "Un petit projet de démo pour présenter les tests Protractor",
"dependencies": {
"jasmine-data-provider": "^2.2.0"
},
"devDependencies": {},
"scripts": {
"test": "protractor src/conf-demo.js"
},
"author": "",
"license": "ISC"
}
L’utilitaire a automatiquement détecté le package jasmine-data-provider, et l’a donc déclaré dans le package.json. Vous avez remarqué ce petit accent circonflexe juste avant le numéro de version ? Il fait partie de la syntaxe de versionning de npm (que nous vous invitons à découvrir ici) et permet ici de bénéficier des mises à jour non-majeures du paquet.
Cependant, nous vous conseillons autant que possible de fixer les versions de vos projets, afin d’être sûr d’avoir des configurations similaires d’une machine à l’autre.
Vérifions que tout marche bien : supprimons sauvagement le dossier node_modules créé précédemment, et lançons la commande « npm install » à la racine du projet. Et hop, le dossier réapparaît.
De bonnes fondations sont posées, mais il reste encore quelques éléments à prendre en compte pour que le projet soit industrialisable. A demain pour aller encore plus loin avec votre projet de test Protractor !
Découvrez nos autres séries d’articles !
Notre saga du test audiovisuel
Notre série dédiée aux tests de sécurité
Le kit de secours métaphorique du testeur agile