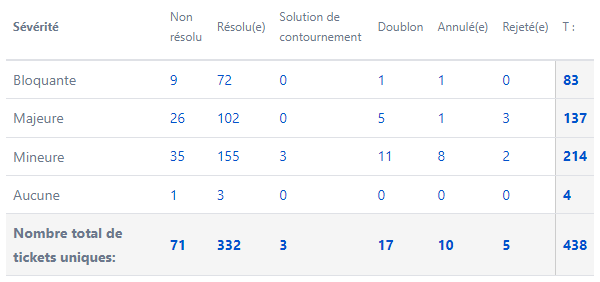
Priorisation : que faire quand ça semble trop tard ?
Pour ce troisième article sur les métaphores au service du test, nous allons nous pencher une fois de plus sur l’ennemi juré de la qualité : le temps, qui vient souvent avec ses cousins le rush, le stress et la précipitation. Et si une métaphore nous aidait à nous réconcilier avec ce facteur incontrôlable ?
Problématique
Le sprint est presque fini mais rien n’est vraiment prêt. Toute l’équipe est stressée et ne sait plus où donner de la tête. Freeze : c’est peut-être le moment de se calmer un peu et de faire le point sur ce qu’on peut rapidement finaliser. Vous avez besoin d’un déclencheur pour vous sortir la tête du guidon et aller à l’essentiel.
Métaphore
« Récolter les fruits d’un travail » est une métaphore assez commune. En cette fin de sprint ou d’itération, vous et votre équipe êtes en pleine cueillette. Mais vos paniers ne se remplissent pas très vite et vous vous inquiétez car le soleil est en train de se coucher. La lumière décline, les figues sont de moins en moins visibles dans les arbres et l’angoisse de ne rien cueillir habite chacun d’entre vous. Naturellement, à ce stade, ce sont les figues les plus basses que vous devez récolter, peu importe si elles sont petites. Le « low-hanging fruit« , c’est un bénéfice rapide que l’on peut faire en déployant un effort modéré.
Cette métaphore est souvent utilisée dans la littérature agile, et en particulier dans More Agile Testing. Dans l’objectif de livrer de la valeur à chaque sprint, il est parfois intéressant de se focaliser sur ce qui est rapidement faisable plutôt que sur ce qui serait idéal à long terme. On pourrait utiliser cette métaphore en réunion, par exemple pour organiser des postits énumérant des solutions à un problème. Attention tout de même à garder en tête la notion de valeur, afin de ne pas cueillir un fruit pourri…
Un exemple de schéma :
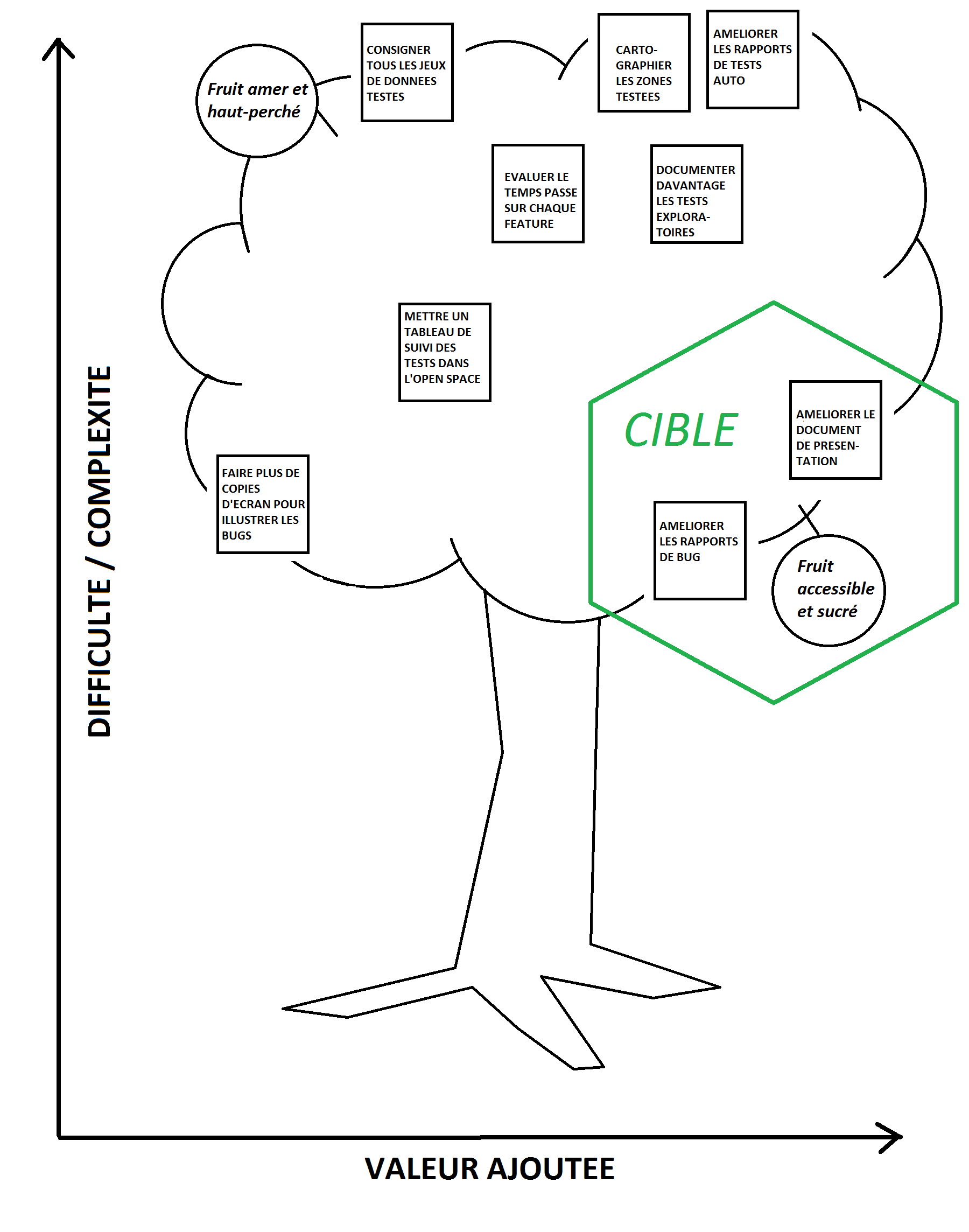
Dans ce graphique structuré autour d’un arbre, l’axe horizontal du représente la valeur ajoutée et l’axe vertical rla difficulté ou la complexité. Les post-its peuvent être classés dans cet arbre pour que l’on puisse visualiser les tâches pouvant rapidement apporter de la valeur. Ces tâches se trouveront donc dans la partie en bas à droite du schéma.
Si vous êtes pressé par le temps, relevez la tête et pensez fruit !
Priorisation bis : le puzzle logiciel au service de la sérénité
Mais fort heureusement, nous ne sommes pas toujours en guerre contre le temps. Côté test, une analyse d’un logiciel par les risques permet de limiter les situations de stress et de faire au mieux en temps limité. Et cela, c’est encore une métaphore qui va nous aider à le partager.
Problématique
En bon choriste de l’ISTQB, vous connaissez par coeur les paroles de « Les défauts sont regroupés » et de « Les tests exhaustifs sont impossibles« . Vos interlocuteurs n’ont peut-être pas envie de vous les entendre chanter encore une fois. Il vous faut rafraîchir cette même idée avec une métaphore.
Métaphore
Janet Gregory compare un logiciel à un puzzle dont on découvre l’image peu à peu, au fur et à mesure où l’on assemble ses pièces. Elle explique qu’il est possible d’obtenir des informations sur le puzzle sans l’assembler en entier, et tant mieux, car cela prendrait un temps fou. Pour tester dans les temps, il faut se concentrer sur les parties du puzzle qui nous intéressent le plus.
Imaginons que notre tableau représente une réplique, peinte par un contemporain, de la fresque de La Création d’Adam, peint par Michel Ange sur le plafond de la Chapelle Sixtine au début du XVIè siècle. Il est spécifié que la réplique doit être la plus fidèle possible à l’original, nous voulons donc tester si cela a été respecté, en maximisant nos chances de trouver d’éventuels défauts. Alors, voici ce que nous allons prendre en compte :
- La partie du tableau où les doigts d’Adam et de Dieu sont sur le point de se toucher est absolument critique. C’est la plus connue, la plus emblématique de l’oeuvre, celle qui justifie son titre ; c’est l’équivalent du cœur de métier. Il faut qu’elle soit testée.
- Les visages sont des parties d’un tableau qui peuvent être très intéressantes, mais le moindre détail peut ruiner une expression. On va donc assembler ces parties avec une priorité élevée.
- On sait que le ciel est quasiment un aplat, il contient peu de détails. Inutile d’assembler beaucoup de pièces pour pouvoir affirmer, avec un niveau de confiance élevé, s’il est fidèle au ciel original.
- Le paysage où se tient Adam n’est pas aussi uniforme. Il n’est pas utile d’assembler toutes ses pièces si jamais on manque de temps, mais il n’est pas à négliger pour autant.
Les trois puzzles ci-dessous correspondent à des couvertures de test différentes, mais en cas de manque de temps, on comprend que c’est la première qu’il faudra choisir.

Sur la première image, les trous au niveau du ciel et du paysage n’empêchent pas d’étudier les parties critiques du tableau. Sur la seconde image, les trous se situent sur des visages et autres parties très signifiantes de l’oeuvre, ce qui pose problème. Sur la troisième image, la couverture est parfaite car on se trouve face à l’oeuvre entière, sans aucun trou.
Pour approfondir cette métaphore avec son inventrice, rendez-vous sur le blog de Janet Gregory !
Conclusion
Ici, la métaphore nous permet de dynamiser notre exigence de qualité plutôt que de laisser l’exigence de rapidité inhiber nos forces. Même en cas d’urgence, il est profitable de faire une courte pause pour orienter au mieux nos dernières heures disponibles.
Nous espérons que cette petite série d’articles vous aura plu. Nous développerons peut-être à l’avenir d’autres métaphores ; nous espérons avoir bien illustré le fait qu’il s’agit de puissants outils de pensée.
N’hésitez pas à poster vos propres métaphores dans les commentaires !
Découvrez nos autres séries d’articles !
Notre saga du test audiovisuel