
Note préalable : cet article date de 2017. Depuis, Protractor a atteint la fin de sa vie. Merci à lui et surtout aux personnes qui ont contribué à cet outil !
Diviser pour mieux tester
Bienvenue dans la 3ème et dernière partie de notre série d’articles sur la découverte des tests Protractor ! Dans l’article précédent, nous avons vu pourquoi et comment séparer les jeux de données et les scripts de test. Aujourd’hui, nous poursuivons sur notre lancée en isolant la description des pages et en structurant les dossier du projet.
- Installation et exemple de script
- Gestion des jeux de données et des dépendances du projet
- Structure d’un projet industrialisé
Gestion du référentiel d’objets avec le Page Object Model
Qu’est-ce que le Page Object Model ?
Le Page Object Model est un design pattern (ou patron de conception) qui consiste à regrouper en une même classe les identificateurs des composants web avec lesquels on souhaite intéragir, ainsi que les méthodes associées à ces composants. Le Page Object Model joue le même rôle dans les projets Selenium que l’Object Repository dans les projets UFT ou Katalon par exemple.
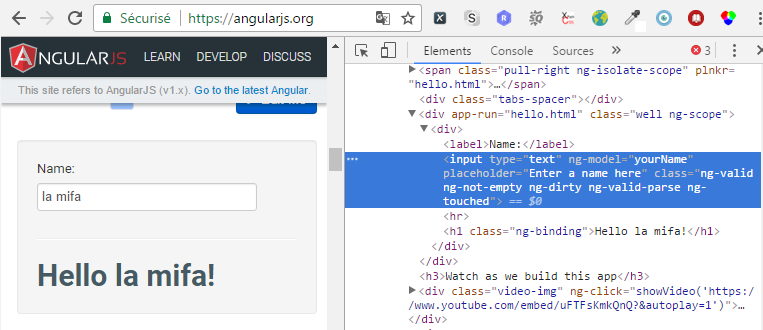
Dans les articles précédent, nous interagissons avec la page d’accueil du site d’Angular. Si nous nous servons d’un objet page pour la décrire, cela donne :
var SiteAngularPageAccueil = function() {
this.champ_nom = element(by.model('yourName'));
this.message_salutations = element(by.xpath("//div[contains(@class, 'well')]//h1"));
this.entrerPrenom = function(prenom) {
this.champ_nom.sendKeys(prenom);
};
};
module.exports = SiteAngularPageAccueil;
La méthode entrerPrenom est vraiment simpliste ; en pratique, on pourrait s’en passer. Nous avons choisi de la créer simplement pour fournir un exemple d’utilisation de méthode d’objet.
Enregistrons ce code dans un fichier site-angular-page-accueil.js, que nous plaçons dans un dossier « pages ».
Utilisation de l’objet page dans le script
Mettons à présent à jour le cas de test en appelant l’objet page et en interagissant avec elle :
var donnees = require('./jeu-de-donnees-demo.js');
var using = require('jasmine-data-provider');
var SiteAngularPageAccueil = require('../pages/site-angular-page-accueil.js');
describe("Suite de test de la feature qui dit bonjour", function() {
var pageAccueil = new SiteAngularPageAccueil();
beforeEach(function () {
browser.get(browser.baseUrl);
});
using(donnees.prenoms, function (data, description) {
it("Chaîne de type " + description, function () {
testMessageSalutations(data.prenom);
});
});
using(donnees.faux_positif, function (data, description) {
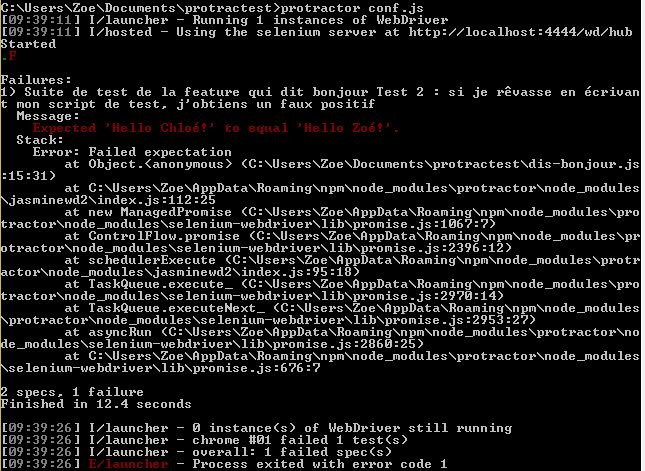
it("Si je rêvasse en écrivant mon script de test, j'obtiens un faux positif", function () {
testMessageSalutations(data.prenomSaisi, data.prenomVoulu);
});
});
function testMessageSalutations(prenomSaisi, prenomVoulu){
pageAccueil.entrerPrenom(prenomSaisi);
var prenomAVerifier = (prenomVoulu ? prenomVoulu : prenomSaisi);
expect(pageAccueil.message_salutations.getText()).toEqual('Hello ' + prenomAVerifier + '!');
}
});
Nous avons également créé une fonction testMessageSalutations pour éviter au maximum la duplication entre les deux cas de test.
Le script est maintenant concis et exempt de toute redite ! A ce stade, notre script de test a atteint un niveau de maintenabilité satisfaisant. Il peut jouer une multitude de cas de test différents, et n’est plus soumis aux changements de l’interface du site web.
Exemple de structure de projet Protractor
Pour augmenter la lisibilité de votre projet, nous vous suggérons de ranger dans des répertoires séparés vos fichiers de configuration, vos pages, vos suites de tests et vos jeux de données.
Le nombre de suites de test augmentant, n’hésitez pas à créer des sous-dossiers. Dans vos fichiers de configuration, il sera d’autant plus simple de sélectionner tel ou tel ensemble de suites de tests. Par exemple :
exports.config = {
seleniumAddress: 'http://localhost:4444/wd/hub',
specs: ['../specs/front-office/*.js'],
baseUrl: 'https://www.monsupersiteweb.nc',
framework: 'jasmine2'
};
Ici, toutes les suites de test se trouvant dans /spec/front-office seront jouées.
Vous avez maintenant tout ce qu’il vous faut pour démarrer votre projet de tests Protractor sur de bonnes bases. A vous de jouer maintenant ! Et vous souhaitez rester encore un peu avec nous, voici un petit bonus…
Bonus : le reporting Jasmine
Vous aurez beau écrire le plus beau code du monde, il y a peu de chances que celui-ci suffise à émouvoir aux larmes votre chef de projet, client ou patron. Un reporting clair et documenté est indispensable pour communiquer sur l’exécution des tests. C’est pourquoi nous ne voulions pas vous quitter avant d’évoquer la librairie Jasmine2 Screenshot Reporter.
Ajout de la librairie
Dans votre package.json, déclarez la dépendance voulue :
"dependencies": {
// [...]
"protractor-jasmine2-screenshot-reporter": "0.3.5"
}
Mise à jour du fichier de configuration
Il est maintenant nécessaire d’appeler la librairie dans le fichier de configuration :
var HtmlScreenshotReporter = require('protractor-jasmine2-screenshot-reporter');
var reporter = new HtmlScreenshotReporter({
dest: '../reports',
filename: 'reporting-' + getDate(true) + '.html',
reportOnlyFailedSpecs: false,
captureOnlyFailedSpecs: true,
showQuickLinks: true,
reportTitle: "Rapport de tests automatisés du " + getDate() + "",
reportFailedUrl: true,
pathBuilder: function(currentSpec, suites, browserCapabilities) {
return currentSpec.fullName + "--" + browserCapabilities.get('browserName');
}
});
exports.config = {
seleniumAddress: 'http://localhost:4444/wd/hub',
specs: ['../specs/dis-bonjour.js'],
baseUrl: 'https://angularjs.org',
framework: 'jasmine2',
beforeLaunch: function() {
return new Promise(function(resolve){
reporter.beforeLaunch(resolve);
});
},
onPrepare: function() {
jasmine.getEnv().addReporter(reporter);
},
afterLaunch: function(exitCode) {
return new Promise(function(resolve){
reporter.afterLaunch(resolve.bind(this, exitCode));
});
}
};
function getDate(dansNomFichier) {
var today = new Date();
var dd = today.getDate();
var mm = today.getMonth() + 1;
var yy = today.getFullYear();
var hh = today.getHours();
var min = today.getMinutes();
if(dd<10) dd='0' + dd;
if(mm<10) mm='0' + mm;
if(hh<10) hh='0' + hh;
if(min<10) min='0' + min;
if(dansNomFichier){
today = yy + '-' + mm + '-' + dd + '--' + hh + 'h' + min;
} else {
today = yy + '/' + mm + '/' + dd + ', ' + hh + ':' + min;
}
return today;
}
Explication du fichier de configuration
dest: '../reports'
Avec cette configuration de la variable dest, si votre fichier de configuration se trouve bien dans un sous-dossier dédié (/src/confs par exemple), un sous-dossier « reports » sera créé dans le dossier « src ». A l’intérieur de ce dossier seront créés les reportings au format html, ainsi que les screenshots.
A chaque lancement, son contenu sera supprimé. Si vous souhaitez conserver les résultats des tests d’un lancement à l’autre, mettez à true la variable preserveDirectory lors de l’instanciation de votre HtmlScreenshotReporter :
preserveDirectory: true,
Dans ce cas, un sous-dossier avec un nom aléatoire sera créé à l’intérieur du dossier « reports ».
filename: 'reporting-' + getDate(true) + '.html',
La variable filename, sans surprise, définit le titre du fichier de reporting ; ici, nous avons choisi de lui ajouter la date et l’heure (voir la fonction « getDate » en bas du fichier).
reportOnlyFailedSpecs: false, captureOnlyFailedSpecs: true,
Les variables reportOnlyFailedSpecs et captureOnlyFailedSpecs permettent de consigner tous les cas de tests dans le reporting, mais de ne prendre un screenshot qu’en cas d’échec.
showQuickLinks: true,
La variable showQuickLinks est à false par défaut. Ici, elle permet de générer au début du fichier des liens vers chacun des cas de test en échec. Pratique quand on se retrouve avec une très grande campagne de test.
reportTitle: "Rapport de tests automatisés du " + getDate() + "",
La variable reportTitle configure le titre qui s’affiche en haut du rapport html.
reportFailedUrl: true,
La variable reportFailedUrl permet d’afficher dans le reporting l’URL sur laquelle l’échec a eu lieu.
pathBuilder: function(currentSpec, suites, browserCapabilities) {
return currentSpec.fullName + "--" + browserCapabilities.get('browserName');
}
La fonction pathBuilder permet de définir le nom des fichiers de screenshot. Ici, le nom est composé du titre du cas de test et du nom du navigateur.
Notre série sur Protractor est maintenant terminée. En espérant qu’elle vous aura apporté des éléments, nous sommes curieux d’avoir vos retours sur ce framework.
Pour en savoir plus sur les différents outils de tests automatisés ainsi que leurs usages et leurs bonnes pratiques, rendez-vous ici !

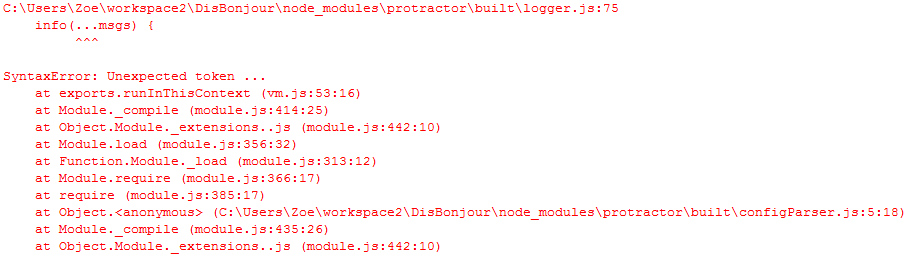












 « Et voici la couleur, au jour fixé et à l’heure dite… »
« Et voici la couleur, au jour fixé et à l’heure dite… »

