Dans l’article précédent, nous présentions la démarche qui nous a animée ces derniers mois chez Hightest dans l’optique de mener un audit green IT et d’accessibilité sur l’ensemble des sites web de Nouvelle-Calédonie. Dans cet article, nous allons voir les résultats du premier audit que nous avons pu mener sur la base de la liste de quelque 2400 sites web calédoniens que nous avons pu constituer !
Outillage
Pour mener l’audit green IT sur cette liste, c’est l’outil d’analyse EcoIndex qui a été utilisé, sur conseil de notre confrère Xavier Liénart, expert du domaine. Il s’agit d’un outil open-source et sans visée commerciale, développé et mis à jour par le Collectif Green IT.
EcoIndex a permis d’obtenir, pour chaque URL testée, les informations suivantes :
- Un score
- Une note
- Le poids de la page
- Le nombre de nœuds sur la page
- Le nombre de requêtes envoyées au moment du chargement de la page.
Un élément important à avoir en tête est que ce sont uniquement les pages d’accueil des sites web calédoniens qui ont été analysées.
Penchons-nous un peu sur ces différents indicateurs.
Un score et une note green IT ?
Le score et la note sont calculés par EcoIndex lui-même et n’ont pas de valeur en-dehors de l’outil. Ils permettent simplement de se faire une première idée (ou une première frayeur…)
Le poids d’une page ?
Le poids d’une page web représente la quantité totale de données que le navigateur doit télécharger pour afficher la page complète. Ainsi, plus il y a de contenus multimédias, plus la page « pèse » lourd. La consommation est encore plus élevée sur des réseaux lents et/ou des appareils mobiles (car l’appareil doit rester actif plus longtemps).
Pour optimiser le poids d’une page web, il est en général recommandé de compresser les images, de minimiser le code CSS et JavaScript non essentiel, et d’utiliser des techniques de chargement asynchrone pour réduire la quantité de données transférées.
Mais au-delà de l’optimisation, un travail de réduction est à envisager. Cette image, peut-on s’en passer ? Idem pour les animations.
Le nombre de nœuds d’une page ?
Les nœuds d’une page web sont les différents éléments de sa structure (le « body » d’une page HTML est un nœud, une image est un nœud, un paragraphe est un nœud…). Un grand nombre de nœuds entraîne une charge de travail plus importante pour le navigateur et une consommation d’énergie accrue. Dans une optique green IT, il est donc recommandé de réduire le nombre de nœuds, ou éventuellement d’utiliser des techniques de chargement progressif de la page.
Le nombre de requêtes envoyées par une page ?
Une page web est un document, qui bien souvent fait appel à d’autres documents pour bien s’afficher. Une image doit s’afficher dans la page ? Une requête est envoyée au serveur pour aller la chercher. Une feuille de style ordonne l’apparence de la page ? De la même façon, ce fichier doit être récupéré sur le serveur. Un script permet d’afficher telle ou telle animation ? Même chose. À noter que ces requêtes peuvent être envoyées sur le même serveur que celui qui héberge la page, ou sur un autre. Regrouper les fichiers ou utiliser la mise en cache sont des techniques préconisées pour réduire l’impact environnemental lié à ces requêtes. Mais aussi, évidemment, simplifier la page et son fonctionnement.
Alors, les résultats ?
Un constat a pu être fait très tôt dans l’analyse : beaucoup des meilleures notes ont été attribuées à des sites en construction qui avaient échappé à notre filtre. Nous avons donc écartés ces sites car hors de notre périmètre cible, ce qui a fait descendre la taille de l’échantillon à 2231. Cela rappelle que ce n’est donc pas parce qu’un site est « écologique » qu’il est écoconçu ; cela peut être simplement parce qu’il ne propose guère de contenu !
Suite à cet ultime écrémage, l’analyse EcoIndex lancée sur les sites web calédoniens a permis de constater les résultats suivants.
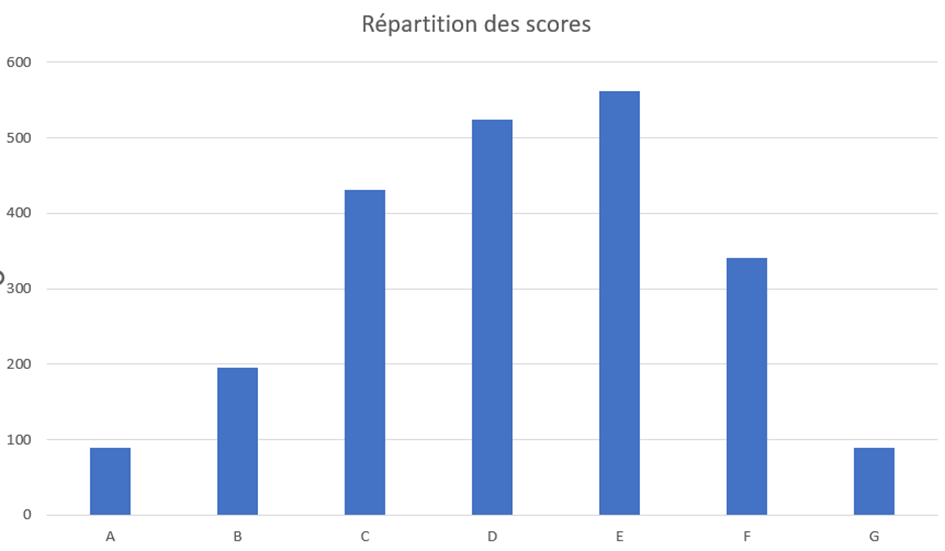
Des scores en courbe de Gauss triste
Sur EcoIndex, les scores des pages sont notés de A à G. La lettre A est attribuée aux sites les plus économes, la lettre G est attribuée aux sites les plus énergivores et impactants au niveau écologique.
La note la plus fréquente est E, ce qui tire la courbe de Gauss vers le côté obscur.
La répartition est la suivante :
| Note | Nombre de sites |
| A | 89 |
| B | 195 |
| C | 431 |
| D | 524 |
| E | 562 |
| F | 341 |
| G | 89 |
Les chiffres !
Poids des pages
Alors qu’EcoIndex préconise un poids maximum cible de 1,084 mégaoctets pour une page web, la moyenne des pages calédoniennes analysées est de 4,087 Mo, et la médiane à 2,824 Mo.
À titre de comparaison, EcoIndex partage les résultats de l’ensemble de ses >200 000 analyses précédentes (donc, sur un échantillon beaucoup plus vaste que la Nouvelle-Calédonie), et ceux-ci révèlent un poids médian de 2,41 Mo.

Nombre de noeuds
Pour ce qui est de la complexité des pages, basée sur leur nombre de nœuds, EcoIndex préconise une cible de maximum 600 nœuds. La moyenne calédonienne est à 810 nœuds, et la médiane à 617, c’est-à-dire un score très proche de la cible. La médiane de l’ensemble des pages web analysées par EcoIndex est à 693.

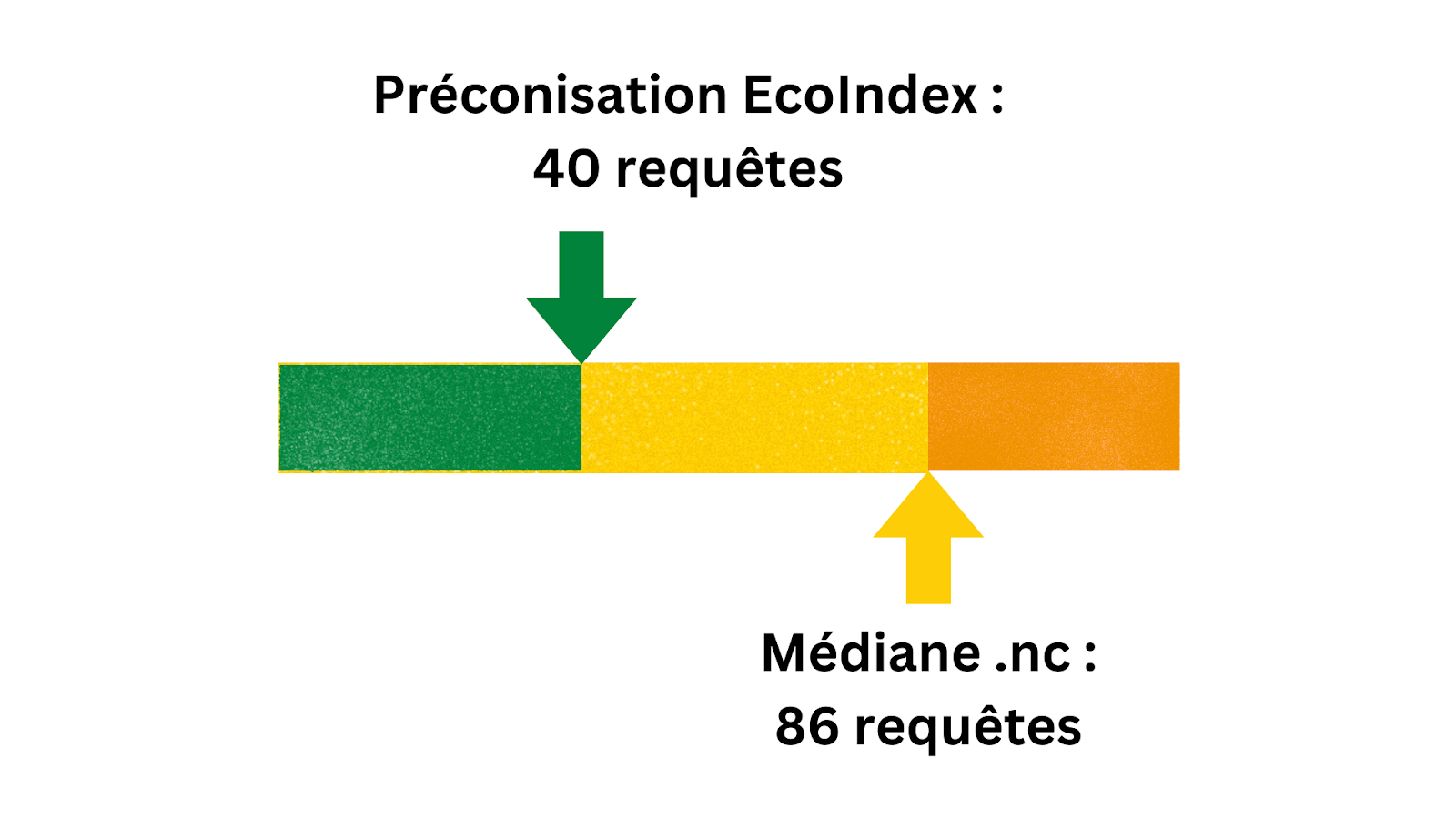
Nombre de requêtes
Combien de requêtes envoient les pages d’accueil des sites web calédoniens ? En moyenne, 98, et le nombre médian est de 86. Le nombre médian pour l’ensemble de tous les résultats EcoIndex est de 78, avec une cible préconisée de 40 requêtes.
Et maintenant… la question qui tue !
Est-ce pire qu’ailleurs ?
Difficile de consulter ces résultats calédoniens sans se demander : « Faisons-nous pire qu’ailleurs ? » Au sein de la commission NID, c’est une question qui s’est posée dès le début : aurons-nous la possibilité de comparer les résultats avec ailleurs ? C’est donc une chance qu’EcoIndex partage les chiffres obtenus sur les autres sites !
Mais quelle conclusion tirer de ces chiffres ? Les écarts sont-ils significatifs ? Parole à notre confrère Thomas Avron, de la société Apid ; datascientist, il est accoutumé à ce type de questions.
Parole à Thomas Avron
La question que l’on va se poser sur l’échantillon des sites de Nouvelle-Calédonie est la suivante : sa distribution est-elle la même que celle de l’ensemble des analyses faites par EcoIndex ?
Poids des sites
Nous savons que le poids médian de l’ensemble des sites analysés par EcoIndex est inférieur à celui des sites du territoire. Comme nous n’avons pas la certitude que la distribution de notre échantillon suit une loi Normale (la fameuse courbe de Gauss, centrée sur la moyenne et en forme reconnaissable de cloche), nous allons donc utiliser un test non-paramétrique pour voir si la distribution des données est la même pour les deux groupes (EcoIndex et NC)… Ou si elle est différente.
Le test utilisé est le test U de Mann-Whitney aussi appelé test de Wilcoxon. Et d’après ses résultats, on peut dire que la médiane de notre échantillon de sites calédoniens est significativement différente de la médiane des poids de l’ensemble des sites analysés par EcoIndex !
Aïe ! Comme notre médiane est significativement au-dessus du total des sites analysés, on en conclut que nos sites locaux sont globalement plus lourds que ceux de l’extérieur. Et ce n’est pas un effet statistique.. La bonne nouvelle est la suivante : avec un tel résultat, on ne peut que s’améliorer !
Nombre de nœuds
Pour ce qui est du nombre de nœuds, nous sommes bons élèves : nos pages (avec le même test non paramétrique que pour les poids médians) sont significativement moins complexes. Pour autant, avec un nombre moindre de nœuds, nous avons des pages plus lourdes. Mais l’étude des écarts types révèlent que dans l’échantillon calédonien, il y a une très forte variabilité ! Que ce soit pour le poids, la complexité, ou le nombre de requêtes.
Nombre de requêtes
Et pour ce qui est du nombre de requêtes, il est significativement plus élevé dans les pages d’accueil de nos sites web calédoniens. Devons nous en conclure que tous les sites calédoniens sont moins “green” que leurs homologues du reste du monde ? En moyenne on le pourrait mais il faut se méfier des moyennes. La variabilité forte de l’échantillon calédonien révèle tout de même que nous avons des sites web très bien classés et qui se défendent bien au regard des objectifs, pourtant ambitieux, d’EcoIndex. Alors haut les cœurs ! Nous avons des efforts globaux à faire mais la compétence pour faire des sites de qualité est là !
Conclusion à six mains
Ce comparatif ne joue pas en notre faveur. Plus lourds alors que moins complexes, un plus grand nombre de requêtes… les sites calédoniens dans leur ensemble ne sont pas les bons élèves du green IT.
Et au-delà de ce comparatif avec les autres sites, l’objectif à avoir en tête est bien celui proposé par EcoIndex ; à ce titre, seule une très faible proportion de sites passe le test avec succès. Quand il s’agit de performance environnementale, nous n’irons nulle part, collectivement ni individuellement, si notre unique souci est de “ne pas faire pire que les autres”.
Sensibilisons-nous donc au plus tôt aux bonnes pratiques d’écoconception des sites web, et s’il n’est pas possible d’améliorer l’existant dans l’immédiat, engageons-nous à en faire une priorité sur tout nouveau projet !
_____________________________________________________________________
Ont contribué à cet audit :
Xavier Liénart, MSI : expertise green IT, conseil technique notamment sur le choix de l’outil, contribution aux articles
Maeva Leroux : suivi de l’audit et animation de l’équipe, contribution à l’audit, conseil, veille technologique
Thomas Avron, APID : expertise en statistiques, interprétation des résultats, contribution au présent article
Mehdi Hassouni : commanditaire de l’audit dans le cadre de la commission NID du cluster OPEN NC
Le contact Hightest est Zoé Thivet : pilotage de l’audit et de la rédaction des articles, constitution du jeu de données, collecte automatisée des résultats EcoIndex
Et bien sûr un grand merci au Collectif Green IT pour son outil EcoIndex !
Pssst… ce n’est pas fini ! Sur le même échantillon de sites, un audit sera mené prochainement sur l’accessibilité !