1. Pourquoi utiliser SonarQube ?
SonarQube est un outil d’analyse statique qui a pour but de mesurer la qualité du code d’un applicatif. Pour un projet donné, il fournit des métriques portant sur la qualité du code et permet d’identifier précisément les points à corriger (code mort, bugs potentiels, non-respect des standards, manque ou surcharge de commentaires…) Très utilisé dans les DSI, il gagne donc à être connu au moins dans ses grandes lignes !
2. Quels défauts SonarQube permet-il d’identifier ?
SonarQube classe les défauts logiciels selon 3 catégories :
- Les bugs : anomalies évidentes du code. Ils impactent la fiabilité (reliability) de l’application.
- Les vulnérabilités : faiblesses du code pouvant nuire au système. Elles impactent la sécurité de l’application.
- Les « code smells » : anti-patrons (ou anti-patterns). Ils impactent la maintenabilité de l’application.
3. Qu’est-ce qu’un code smell ?
En peu de mots, du code qui sent le roussi ! Wikipedia donne quelques exemples de code smells. En général, SonarQube détecte davantage de code smells que de bugs ou de vulnérabilités. Il est donc important de déterminer si l’on souhaite tous les corriger, ou si certains peuvent être acceptés (mais nous en reparlerons tout à l’heure !)
4. SonarQube et les tests unitaires, c’est pareil ?
Attention ! Même si les deux se focalisent sur le code, et non sur les interfaces des applications à tester, il ne faut pas confondre les analyses SonarQube et les tests unitaires. Ce n’est pas du tout la même chose. Premièrement, les tests unitaires exécutent des composants de l’application à tester ; ils ne font donc pas partie des outils d’analyse statique. Deuxièmement, les tests unitaires permettent de vérifier des fonctionnements de l’application, alors que les analyses SonarQube s’attachent à la qualité du code, sans savoir ce que ce code est censé faire.
Pour faire un parallèle, les logiciels sont comme des textes dont les tests unitaires vérifient le sens et la cohérence, et dont SonarQube vérifie l’orthographe et la lisibilité. Dans son roman Sodome et Gomorrhe, Marcel Proust a écrit une phrase de 856 mots ; si ce roman était un logiciel, SonarQube aurait sans doute remonté une erreur (mais les tests unitaires seraient passés !)
L’analyse SonarQube ne remplace donc en aucun cas les tests unitaires, mais permet d’identifier rapidement certains défauts du code.
5. Comment lancer une analyse SonarQube sur un projet ?
Prérequis
Installer SonarQube (voir la documentation officielle).
Démarrer votre instance avec la commande :
service sonar start
Configurer l’analyse SonarQube
- A la racine du projet, créer un fichier intitulé « sonar-project.properties ».
- Compléter ce fichier avec le texte suivant :
sonar.projectKey=nom.du.projet
sonar.projectName=Nom du projet
# La version de votre projet, pas celle de SonarQube
sonar.projectVersion=1.0
# Définit l’emplacement des sources que SonarQube va analyser.
sonar.sources=.
# A décommenter si besoin
#sonar.sourceEncoding=UTF-8
- Toujours à la racine du projet, lancer la commande « sonar-scanner ».
6. Quelles sont les fonctionnalités de SonarQube ?
Rentrons maintenant dans le vif du sujet en faisant le tour des principales fonctionnalités de SonarQube !
Analyse des résultats SonarQube
En supposant que SonarQube soit en local, les résultats de l’analyse seront consultables sur http://localhost:9000/sonar/. Chaque projet dispose d’un espace d’analyse dédié.
Ecran d’accueil de SonarQube
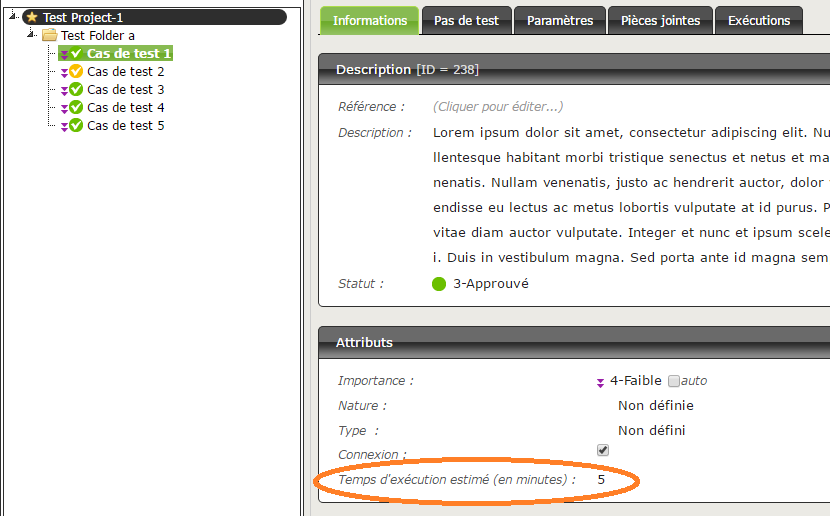
Sur l’écran d’accueil d’un projet analysé par SonarQube se trouve un récapitulatif des grandes familles de défauts :
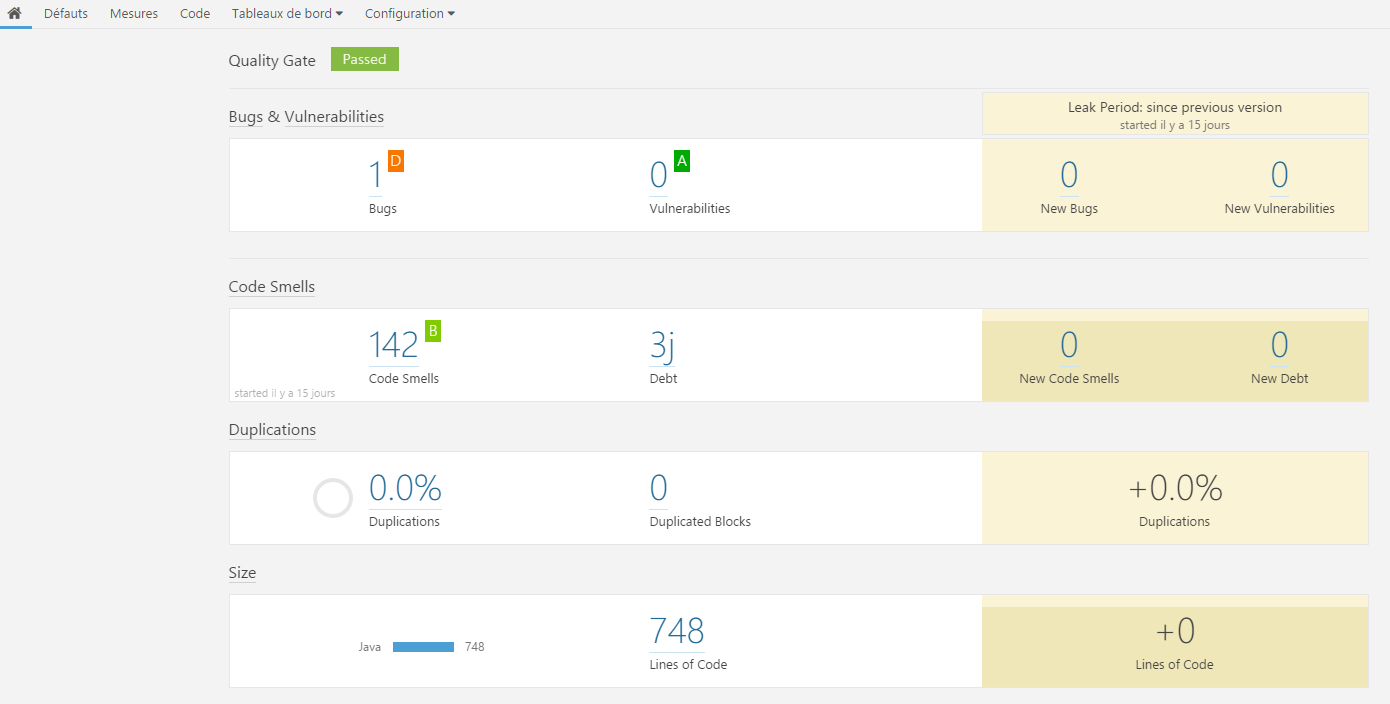
La mention « Passed » signifie que le projet satisfait les exigences minimum définies dans l’espace « Barrières qualité ». Les paramètres par défaut peuvent être adaptés.
Onglet « Défauts »
Dans cet onglet, chaque bug, vulnérabilité ou code smell est répertorié et détaillé dans une liste.
L’intérêt immédiat, orienté projet : tel un outil de bugtracking ou de gestion de tickets, cette liste permet de prioriser les points à traiter, d’évaluer leur temps de correction et de les affecter à un développeur. Le statut de chaque défaut est affiché. Les options du projets, tels que l’utilisateur affecté par défaut, peuvent être configurés (onglet « Configuration » -> « Configuration du projet »).
En se positionnant en vue « Effort », on peut également voir le temps total que prendrait la correction de tous les défauts du code, ce qui peut faciliter la planification du travail d’un développeur lors d’un sprint par exemple.
Le second intérêt, orienté humain : comme chaque défaut comporte une explication détaillée et des pistes d’amélioration, le développeur est susceptible de monter en compétence et d’améliorer à long terme la qualité de son code. C’est donc un véritable outil d’amélioration continue !
Onglet « Mesures »
On y trouve des infos supplémentaires, plus générales, telles que la complexité du projet et le pourcentage de commentaires (20% étant habituellement reconnu comme un bon pourcentage). Contrairement à l’écran précédent, celui-ci n’est pas très bavard : à l’utilisateur de trancher si le taux de complexité est acceptable, par exemple. Pour en savoir plus sur les méthodes de calcul de la complexité, rendez-vous ici.
Onglet « Code »
Cet onglet est particulièrement pratique. Il permet en effet de visualiser, fichier par fichier, les problèmes identifiés par SonarQube. Le code est intégralement affiché, avec des icônes au niveau des lignes posant problème.
Onglet « Tableau de bord »
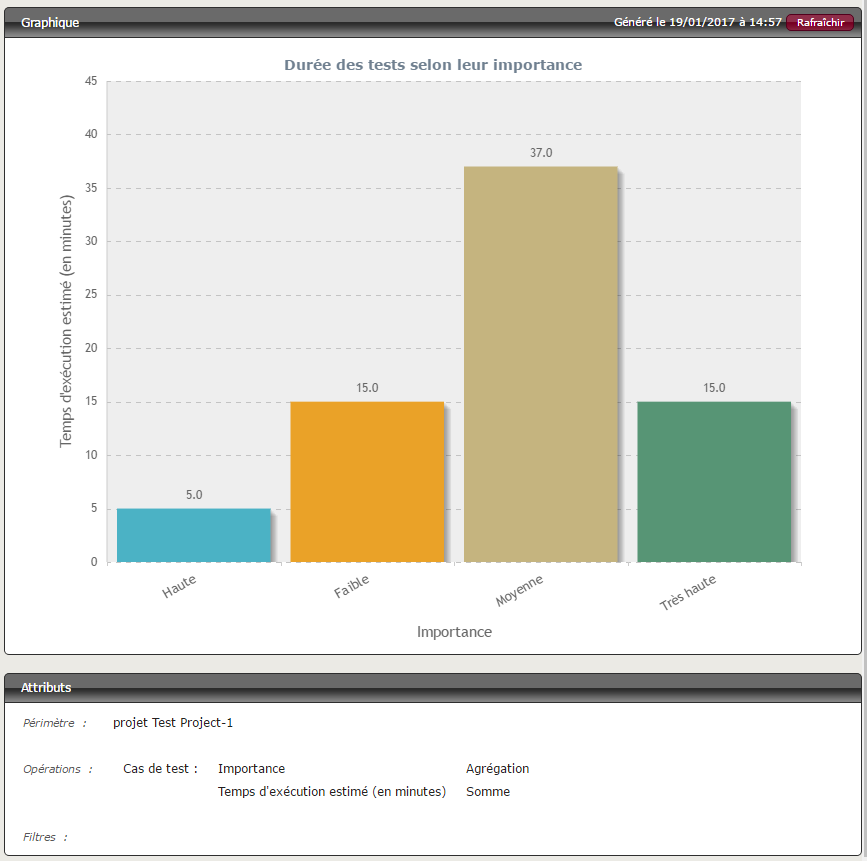
Sur cette page sont rassemblées un grand nombre de métriques utiles pour communiquer sur la qualité du code. Les dashboards sont configurables selon un grand nombre de paramètres.
Penchons-nous maintenant sur le cœur de SonarQube, à savoir la définition des règles de qualité du code.
Gestion des règles SonarQube
Liste des règles
La liste exhaustive des règles associées aux défauts est disponible à cette adresse : http://localhost:9000/sonar/coding_rules.
Dans cet espace, il est possible de modifier la sévérité que SonarQube attribue à chaque défaut. La détection de certains défauts peut aussi être désactivée. Lors des analyses suivantes, ils seront donc ignorés.
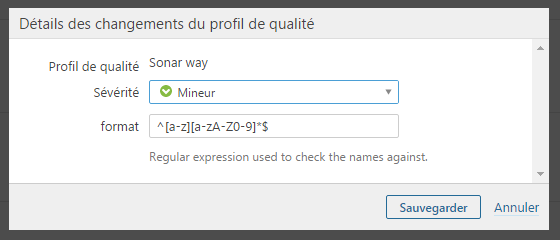
Adapter les règles SonarQube existantes
Le contenu de certaines règles peut être configuré. Par exemple, la règle de nommage des variables locales en Java est vérifiée grâce à une expression régulière qui peut être changée :
Créer de nouvelles règles SonarQube
SonarQube a prévu une documentation pour créer de nouvelles règles.
7. Comment lancer une analyse SonarQube depuis Jenkins ?
Pour intégrer pleinement SonarQube à votre démarche d’intégration continue, nous vous suggérons de déclencher des lancements automatiques de l’analyse du code depuis Jenkins.
Comment faire ? C’est simple :
- Installez le plugin SonarQube
- Générez un token dans l’interface SonarQube. Pour ce faire, une fois connecté, cliquez sur votre profil, puis sur « My account » et « Generate tokens ».
- Cliquez sur « Administrer Jenkins » puis sur « Configurer le système ». Dans la partie « SonarQube servers », entrez le token précédemment généré.
- Créez un job et configurez-le. Créez une étape de build « Lancer une analyse avec SonarQube Scanner ». Si vous ne remplissez pas les champs, ce sont les informations présentes dans le fichier sonar-project.properties qui prévaudront.
SonarQube et Jenkins Pipeline
Comme nous sommes de plus en plus nombreux à mettre en place ce type de jobs, voici un exemple de pipeline très simple réalisant une analyse SonarQube :
node {
// Lors de cette phase de setup, nous récupérons dans le workspace de Jenkins les sources à analyser.
stage(‘Setup’) {
checkout([$class: ‘GitSCM’, branches: [[name: ‘*/master’]], doGenerateSubmoduleConfigurations: false, extensions: [], submoduleCfg: [], userRemoteConfigs: [[credentialsId: ‘***clé générée par le plugin Credentials de Jenkins***’, url: ‘http://votresuperdepot.git’]]])
}
stage(‘Analyse SonarQube’) {
// Le nom du « tool » et de l’argument de « withSonarQubeEnv » correspond au nom de l’instance SonarQube telle que défini dans Jenkins, dans « Configurer le système » > « SonarQube servers » > « Installations de SonarQube » > « Nom »
def scannerHome = tool ‘Sonar’;
withSonarQubeEnv(‘Sonar’) {
sh « ${scannerHome}/bin/sonar-scanner »
}
}
}
8. Qu’est-ce qu’il ne faut pas attendre de SonarQube ?
Une exactitude indiscutable
Il est nécessaire de qualifier chaque défaut que SonarQube identifie ; nul logiciel de test automatisé n’est à l’abri d’un faux positif. Pour reprendre la métaphore du roman, qui oserait « refactorer » les romans de Proust sous prétexte qu’il a écrit un certain nombre de trèèèèès longues phrases ?
Il ne faut pas oublier que les problèmes remontés par SonarQube sont issus de scans qui repèrent des motifs présents dans le code. Parfois, ce sont donc ces motifs qu’il faut interroger et remettre en question. Et c’est bien pour ça que SonarQube propose de pouvoir gérer les règles comme bon nous semble !
Un substitut aux revues de code
Les analyses quantitatives de SonarQube peuvent être trompeuses. En effet, ce n’est pas parce que 20% des lignes d’une application sont des commentaires que ceux-ci sont véritablement utiles et apportent de la valeur. De même, ce n’est pas parce que SonarQube n’a pas identifié de duplications que le programme ne comporte pas de redondances.
Même si SonarQube est très utile pour identifier des défauts spécifiques et donner une vision d’ensemble de la qualité du code, ses analyses gagnent à être complétées par une revue de code réalisée par un humain.
D’ailleurs, si le sujet des revues de code vous intéresse, nous vous conseillons vivement de découvrir l’outil Promyze, plateforme de gestion collaborative de la qualité de code.
Conclusion
SonarQube permet donc d’identifier très rapidement les anomalies de code d’une application. Mais c’est une solution qui doit aller de pair avec une stratégie globale de qualité de code. Il faut connaître son applicatif afin de pouvoir analyser les reportings, trancher sur ce qu’il faut ou non corriger et fixer des seuils en-deçà desquels la qualité sera jugée insuffisante.