Dans cet article, nous allons partager quelques connaissances sur… justement, la gestion des connaissances ! En mettant le focus, non pas sur sa forme organisationnelle, mais sur les savoirs que l’on accumule au cours d’une carrière dans le test logiciel, et qui sont propres à chaque individu.
Bonne lecture !
Qu’est-ce que le PKM… et est-ce que ça vous concerne ?
Vous en avez déjà fait sans le savoir
PKM est l’acronyme de Personal Knowledge Management, en bon français la gestion des connaissances personnelles. Le PKM invite à développer, pour soi-même, des méthodes et des outils pour consigner, organiser puis retrouver ce qu’on apprend, de façon à ce que ces connaissances restent utiles sur le long terme.
Du PKM, tout le monde en a déjà fait, ne serait-ce que pendant ses études. Structure ses connaissances sous forme de fiches, de mindmaps, de listes de vocabulaire… autant d’habitudes prises à l’époque parce que les examens nous y contraignaient. Parfois même, on a peut-être expérimenté des méthodes différentes pour voir lesquelles seraient les plus efficaces pour ancrer les connaissances (avez-vous déjà testé de créer un palais mental ?).
Une compétence à réactiver
En revanche, une fois en poste, ces habitudes et cette discipline ont tendance à s’effriter, à devenir moins systématiques. On prend des notes pendant les réunions, on ajoute des marque-page dans son navigateur, mais il n’y a pas toujours de structure d’ensemble. On en ressent tout simplement moins le besoin, car les enjeux ne sont plus les mêmes. Le quotidien professionnel et les priorités opérationnelles prennent le dessus ; on se retrouve à apprendre « en passant », sans vraiment capitaliser sur ce qu’on découvre.
En outre, les documentations que l’on crée dans le cadre de sa carrière sont la plupart du temps à destination de notre organisation. Elles ne sont pas taillées sur mesure pour notre propre usage.
C’est grave, docteur ?
Pas forcément, mais on court alors le risque de perdre une somme importante de connaissances au fil du temps, et a fortiori en changeant d’organisation.
Pourquoi le PKM est particulièrement pertinent dans le test logiciel
Au fil d’une carrière dans le test logiciel, énormément d’informations sont mobilisées, et de natures bien différentes.
On peut en citer quelques unes :
Les connaissances socle du monde du test
Les processus métier spécifiques
Les jargons spécialisés, les acronymes
Les outils
Les syntaxes de différents langages et frameworks
Et tant d’autres !
Risque 1 : l’oubli
Si on ne fait pas d’effort, on oublie au fur et à mesure ce qu’on a appris, et on peut finir par douter : avons-nous construit une véritable expertise, ou simplement accumulé une ancienneté ? Le syndrome de l’imposteur, que connaissent bien souvent les juniors (surtout suite à une reconversion) peut repointer le bout de son nez au bout de quelques années. Double effet Kiss Cool !
Risque 2 : la dispersion
À la longue, également, on peut se retrouver avec une impression d’être un bocal rempli d’informations disparates, se dire que tous ces éléments n’ont guère à voir les uns avec les autres, ou encore qu’ils sont trop spécifiques à un contexte, en ayant du mal à prendre de la hauteur sur la valeur de ces connaissances.
Le PKM est là pour répondre à ces problématiques. Ces dernières années, des outils numériques spécialisés se sont développés et démocratisés, qui permettent de mettre en œuvre cette pratique de manière à la fois simple et approfondie.
Un outil de PKM : Obsidian
Obsidian est un outil de PKM (gratuit) qui rappelle les wikis dans son fonctionnement. On peut y prendre des notes et lier ces notes entre elles. Un terme qui revient souvent : ces notes gagnent à être « atomiques » : une note = un concept. Ainsi, plutôt que d’avoir un long document qu’on n’aura jamais le courage de relire en entier, on dispose de nombreuses petites notes rapides à manipuler. On les relie ensuite entre elles pour former comme une toile de connaissances.
Les notes Obsidian sont au format markdown, et sont stockées directement en local.
Une fonctionnalité d’Obsidian ne manquera pas de vous plaire : la vue graphique. Elle vous permet de visualiser, en un coup d’œil, toutes les connaissances que vous avez consignées. Vous pouvez ainsi, en survolant les points, regarder les relations entre vos savoirs.
Un exemple ?
Voici une note Obsidian résumant un article scientifique. Elle comporte plusieurs liens qui permettent de retrouver facilement certaines notions, et permettent aussi en un clic de retrouver tous les autres articles scientifiques sur la qualité logicielle qui ont été enregistrés dans cette instance Obsidian.
Nos conseils pour démarrer
… Démarrer ! Nul besoin de mettre en place une stratégie en amont, le mieux c’est de commencer à prendre des notes et de les organiser au fur et à mesure.
Éviter les gros copier-coller. C’est exactement ce qui pourrait vous décourager de vous y mettre, surtout si vous disposez de peu de temps.
Prendre le réflexe d’ouvrir Obsidian dès que vous vous dites « Ça, je n’ai pas envie de l’oublier ».
De temps en temps, ouvrir Obsidian et reparcourir vos notes, en créant des liens entre elles si vous en trouvez !
Se sentir libre de mélanger des notes « professionnelles » avec des notes plus personnelles (sur vos hobbies par exemple). Vous n’avez qu’un seul cerveau ; vos connaissances sont toutes interconnectées. Dans le graphe ci-dessus, il y a aussi bien des recettes de cuisine afghane que des outils de cybersécurité, des notions de finances publiques, de psychologie et d’histoire !
Petit à petit, vous verrez que vous retenez davantage de choses, et que vos connaissances se pérennisent.
Nous espérons que cet article vous aura donné envie d’explorer le PKM ! Qui sait, peut-être mettrez-vous le lien de cet article sur une de vos notes Obsidian (ou autre outil de votre choix)…
Smartesting est une entreprise française que vous connaissez peut-être déjà pour ses outils Yest ou Gravity ; en 2025, son petit dernier s’appelle Lynqa.
“Des tests manuels automatiques”, telle en est la promesse oxymorique. Nous avons eu l’occasion d’essayer cet outil et souhaitons partager avec vous un exemple de scénario simple parmi ceux que nous avons testés.
Comment marche Lynqa, à quoi ça ressemble et qu’est-ce que ça implique de nouveau dans le monde du test, on va décortiquer tout ça dans cet article !
Lynqa, c’est quoi ?
Le principe de Lynqa : exécuter des tests à partir de cas de tests existant. Ni plus ni moins : un patrimoine de test avec des cas de test tout ce qu’il y a de plus classique avec actions et résultats attendu.
Pour illustrer le fonctionnement de Lynqa, voici un cas de test très simple :
Action : “Sur la page Fruits à gogo, entrer une quantité de 30 kilos de papaye, valider.”
Résultat attendu : “Le tarif s’affiche et correspond à 10 500 francs pacifiques.”
Lynqa devra se débrouiller avec ces informations, comme le ferait un être humain. Pas question donc de lui préciser de sélecteurs, comme un automate le nécessiterait. On oublie les input, les button, on ne cherche plus d’id unique, on ignore les classes CSS. Pas question non plus d’écrire précisément “kg” au lieu de “kilos” pour correspondre à la graphie du site. “Valider” doit être correctement interprété, à savoir comme un clic sur le bouton “Calculer”. Et enfin, on ne s’inquiète pas du format de la devise ; Lynqa devra comprendre que “francs pacifiques” c’est la même chose que “CFP”, “F CFP” ou encore “XPF” !
Comment ça marche ?
Sous le capot de Lynqa travaillent plusieurs agents IA. Chacun de ses agents a sa propre responsabilité : interpréter l’intention du test, découper les actions, “regarder” l’apparence de l’interface à tester, comparer ce qui est constaté par rapport à l’attendu…
Vous noterez qu’aucun agent n’étudie la structure du DOM ; tout est fait pour se calquer sur l’utilisation cible d’une personne réelle. Ce qui compte, c’est ce qui s’affiche à l’écran.
Lors d’une démo, nous avons pu voir Lynqa travailler avec une cartographie interactive, un type de test souvent casse-tête à automatiser from scratch avec les frameworks habituels. Cela nous a donné envie d’en savoir plus et de faire nos propres essais.
Lynqa nous a confié un accès bêta afin qu’on puisse essayer nous-mêmes cette prometteuse solution, alors allons-y !
Découvrir Lynqa avec un exemple simple
Remarque : les screenshots qui suivent sont datés d’octobre 2025. Au moment où vous lirez cet article, l’interface aura peut-être changé.
Lynqa se présente aujourd’hui comme un plugin Jira qui s’interface avec Xray. Pour commencer, il faut disposer d’un test.
Pour notre essai, les étapes du test sont les suivantes :
Quand on rattache ce test à une “Test Execution”, on peut voir en bas à droite le bouton “Exécuter avec Lynqa”…
Ce bouton ouvre une popin toute simple où il convient de saisir l’URL du site à tester.
À noter : pour le moment, seuls les sites web dont l’accès est public sont testables avec Lynqa, mais la roadmap du produit prévoit à terme de réaliser des tests sur tout type d’application, qu’elle soit web ou non, publique ou non.
Ça y est, l’exécution est lancée !
Les résultats des exécutions sont visibles dans un onglet Lynqa dédié.
On découvre alors le détail de ce que l’automate a réalisé, et on se rend compte que le postulat de départ était correct ! Lynqa a bien réussi à interpréter le langage naturel, à trouver les éléments sur la page, et à effectuer la vérification comme attendu.
D’ailleurs, pour s’en assurer, il est possible d’afficher des captures d’écran pour chaque étape.
Top, le premier test est réussi !
Maintenant voyons ce qui nous est proposé dans le cas d’un test en échec. Pour ce test-là, on va demander de calculer le prix d’un fruit qui n’existe pas dans la liste. La grenade n’est-elle pas le fruit idéal pour faire péter un test ? (Poudoum tssss 🥁)
Test en erreur : comment réagit Lynqa ?
Lançons ce test et observons le comportement de Lynqa face à cette valeur inattendue.
Le test est bien en échec, mais pas pour la bonne raison… Il faudrait que le test échoue dès le moment où il ne trouve pas la valeur “Grenade”, mais ce n’est pas le cas.
Essayons en découpant le test en deux étapes :
Désormais, le test échoue au bon endroit (et avec un message d’erreur clair !)
Conclusion
Ces exemples très simples illustrent le fait que Lynqa ne se comporte donc pas comme une personne (par définition !), mais pas non plus comme un test automatisé classique, dont les capacités d’adaptation sont faibles et qui aurait échoué immédiatement en cherchant le mot “Grenade”.
Malgré le “quasi-faux-négatif”, ce premier aperçu est tout de même impressionnant et prometteur. L’outil est simple à prendre en main et ouvre de nombreuses potentialités. Avec un tarif compétitif (basé sur l’utilisation réelle), Lynqa pourrait devenir une brique incontournable de l’exécution des tests et se faire une place entre l’exécution humaine et l’exécution scriptée en interne.
Quelles conséquences alors sur nos façons de travailler ?
Utiliser efficacement ce type d’outil demandera de nouvelles compétences et une approche spécifique. Si les faux positifs sont monnaie courante dans le monde des tests auto, il apparaît que pour les tests avec des outils comme Lynqa, il faudra surveiller les faux négatifs avec autant de vigilance et apprendre à implémenter des tests qui favorisent un haut degré de reproductibilité, et des variations mineures et maîtrisées. Cela impliquera de revoir la manière dont on rédige les tests. De même qu’on n’écrit pas exactement de la même façon des tests pour un public interne ou pour le crowdtesting, il sera nécessaire d’apprendre à s’adresser de manière efficace aux agents IA qui “voient” l’application d’une manière qui leur est spécifique. Toutefois, ces modifications seront peut-être à terme marginales, en fonction du perfectionnement des outils. Lynqa vise à ce qu’il y ait, à terme, le moins d’adaptations possibles nécessaires sur les tests déjà rédigés.
Plus globalement, repenser la manière dont on construit nos stratégies de test sera une étape indispensable. Le ROI sera tout naturellement au cœur de la réflexion, afin d’arbitrer ce qu’il est plus rentable d’automatiser et ce qu’il est plus pertinent de déléguer à un outil comme Lynqa, pour dégager toujours plus de temps pour réaliser manuellement des tests à haute valeur ajoutée.
Vous pouvez découvrir Lynqa à votre tour à cette adresse !
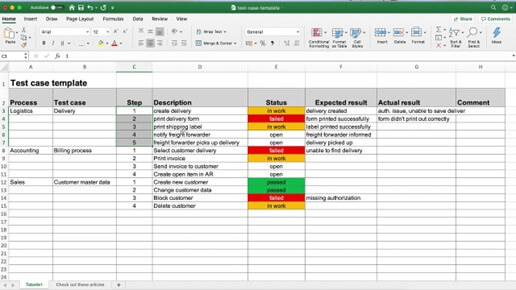
Dans cet article, Christelle Lam, férue de test et en poste chez Hightest depuis 1 an, explique la valeur ajoutée qu’apporte un logiciel de gestion des tests par rapport à un simple fichier Excel. Bonne lecture !
Dans le métier du test, il est fréquent de rencontrer des équipes où le cahier de tests et les rapports d’anomalies se trouvent sur un fichier Excel.
Source : TacticalProjectManager
Pourquoi avoir choisi d’effectuer ce travail à l’aide d’Excel ?
Je pense que bien souvent, c’est par manque de connaissance des logiciels existants très utiles à la gestion de tests.
Un gestionnaire de tests : Quèsaco ?
C’est un logiciel qui permet de gérer le cycle de vie des tests de la création de cas de test, à l’organisation de suites de tests jusqu’à l’exécution des tests, d’assurer la visibilité et la traçabilité des tests et plus si affinités.
Précédemment, nous avons parlé de Squash TM, mais il y en a d’autres comme HP ALM, Azure Test Plans, TestRail, TestLink, Refertest…
Du coup, pourquoi utiliser un gestionnaire de tests plutôt qu’Excel ?
Voici quelques raisons !
Gestion des scénarios de tests
Un gestionnaire de tests offre généralement des fonctionnalités avancées pour la gestion des scénarios de tests tels que la création structurée des scénarios, l’organisation hiérarchique, la gestion des versions, l’assignation des scénarios, le suivi de l’exécution, l’historique des résultats, la génération de rapports, l’intégration avec d’autres outils, automatisation des tests, permettant aux équipes de créer, organiser, exécuter et suivre les résultats de tests de manière plus efficace que ce qui est possible avec Excel.
Collaboration facilitée
Un gestionnaire de tests facilite la collaboration entre les membres de l’équipe de développement et de tests. Il offre souvent des fonctionnalités de partage, de commentaires et de suivi des modifications, ce qui peut être difficile à réaliser de manière efficace avec Excel.
Affectation des cas de test dans Squash TM
Intégration avec d’autres outils
Les gestionnaires de tests sont souvent conçus pour s’intégrer facilement avec d’autres outils de développement tels que les systèmes de gestion de versions, les environnements de développement intégrés et les outils de suivi de problèmes. Cela crée une intégration fluide de processus de développement global.
Génération de rapports de test
Un gestionnaire de tests fournit généralement des fonctionnalités avancées de génération de rapports, permettant aux équipes de tester de manière plus approfondie et de produire des rapports détaillés sur les résultats des tests. Cela peut être plus complexe à réaliser avec Excel.
Source : Squash TM
Réutilisation des scripts de test
Un gestionnaire de tests permet souvent la réutilisation des scripts de test, ce qui signifie que les tests peuvent être adaptés et exécutés à plusieurs reprises sans avoir à tout recréer à partir de zéro, ce qui peut être fastidieux avec Excel.
Gestion des données de test
Un gestionnaire de test peut offrir des fonctionnalités pour gérer efficacement les données de test, par exemple en séparant clairement l’espace de rédaction du scénario de test, et l’espace de déclaration des différentes données de test qui seront utilisées pendant la campagne. Excel ne permet pas cela facilement.
En conclusion, bien qu’Excel puisse être utilisé pour des tâches de base de gestion des tests, les gestionnaires de tests offrent des fonctionnalités plus avancées, une automatisation accrue et une meilleure gestion globale du processus de tests dans des environnements de développement logiciel complexe.
En espérant que cet article t’en a appris un peu plus et que dorénavant tu souhaites te faciliter la tâche en voulant utiliser un gestionnaire de tests plutôt qu’Excel.
N’hésite pas à prendre contact avec nous pour en discuter 😊
L’image de la couverture a été générée avec Midjourney
Dans l’article précédent, nous présentions la démarche qui nous a animée ces derniers mois chez Hightest dans l’optique de mener un audit green IT et d’accessibilité sur l’ensemble des sites web de Nouvelle-Calédonie. Dans cet article, nous allons voir les résultats du premier audit que nous avons pu mener sur la base de la liste de quelque 2400 sites web calédoniens que nous avons pu constituer !
Outillage
Pour mener l’audit green IT sur cette liste, c’est l’outil d’analyse EcoIndex qui a été utilisé, sur conseil de notre confrère Xavier Liénart, expert du domaine. Il s’agit d’un outil open-source et sans visée commerciale, développé et mis à jour par le Collectif Green IT.
EcoIndex a permis d’obtenir, pour chaque URL testée, les informations suivantes :
Un score
Une note
Le poids de la page
Le nombre de nœuds sur la page
Le nombre de requêtes envoyées au moment du chargement de la page.
Un élément important à avoir en tête est que ce sont uniquement les pages d’accueil des sites web calédoniens qui ont été analysées.
Penchons-nous un peu sur ces différents indicateurs.
Un score et une note green IT ?
Le score et la note sont calculés par EcoIndex lui-même et n’ont pas de valeur en-dehors de l’outil. Ils permettent simplement de se faire une première idée (ou une première frayeur…)
Le poids d’une page ?
Le poids d’une page web représente la quantité totale de données que le navigateur doit télécharger pour afficher la page complète. Ainsi, plus il y a de contenus multimédias, plus la page « pèse » lourd. La consommation est encore plus élevée sur des réseaux lents et/ou des appareils mobiles (car l’appareil doit rester actif plus longtemps).
Pour optimiser le poids d’une page web, il est en général recommandé de compresser les images, de minimiser le code CSS et JavaScript non essentiel, et d’utiliser des techniques de chargement asynchrone pour réduire la quantité de données transférées.
Mais au-delà de l’optimisation, un travail de réduction est à envisager. Cette image, peut-on s’en passer ? Idem pour les animations.
Le nombre de nœuds d’une page ?
Les nœuds d’une page web sont les différents éléments de sa structure (le « body » d’une page HTML est un nœud, une image est un nœud, un paragraphe est un nœud…). Un grand nombre de nœuds entraîne une charge de travail plus importante pour le navigateur et une consommation d’énergie accrue. Dans une optique green IT, il est donc recommandé de réduire le nombre de nœuds, ou éventuellement d’utiliser des techniques de chargement progressif de la page.
Le nombre de requêtes envoyées par une page ?
Une page web est un document, qui bien souvent fait appel à d’autres documents pour bien s’afficher. Une image doit s’afficher dans la page ? Une requête est envoyée au serveur pour aller la chercher. Une feuille de style ordonne l’apparence de la page ? De la même façon, ce fichier doit être récupéré sur le serveur. Un script permet d’afficher telle ou telle animation ? Même chose. À noter que ces requêtes peuvent être envoyées sur le même serveur que celui qui héberge la page, ou sur un autre. Regrouper les fichiers ou utiliser la mise en cache sont des techniques préconisées pour réduire l’impact environnemental lié à ces requêtes. Mais aussi, évidemment, simplifier la page et son fonctionnement.
Alors, les résultats ?
Un constat a pu être fait très tôt dans l’analyse : beaucoup des meilleures notes ont été attribuées à des sites en construction qui avaient échappé à notre filtre. Nous avons donc écartés ces sites car hors de notre périmètre cible, ce qui a fait descendre la taille de l’échantillon à 2231. Cela rappelle que ce n’est donc pas parce qu’un site est « écologique » qu’il est écoconçu; cela peut être simplement parce qu’il ne propose guère de contenu !
Suite à cet ultime écrémage, l’analyse EcoIndex lancée sur les sites web calédoniens a permis de constater les résultats suivants.
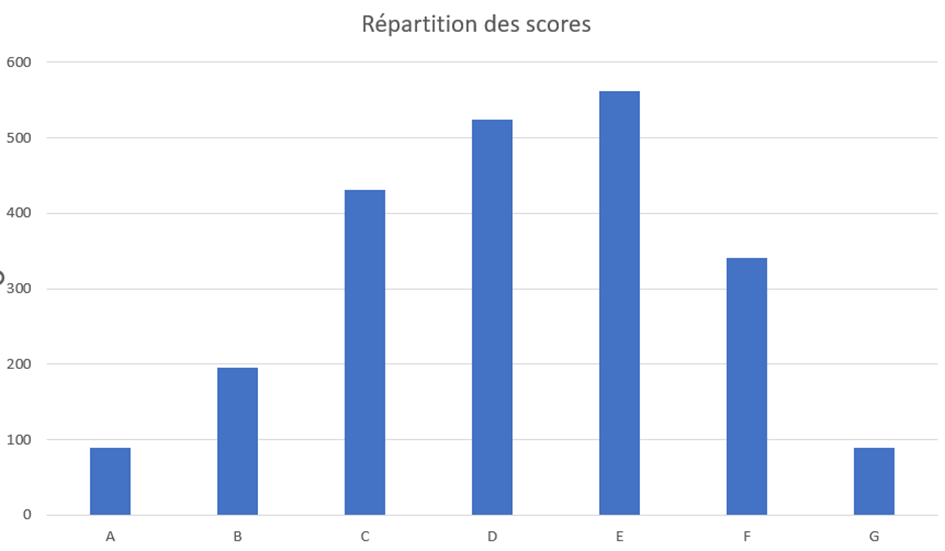
Des scores en courbe de Gauss triste
Sur EcoIndex, les scores des pages sont notés de A à G. La lettre A est attribuée aux sites les plus économes, la lettre G est attribuée aux sites les plus énergivores et impactants au niveau écologique.
La note la plus fréquente est E, ce qui tire la courbe de Gauss vers le côté obscur.
La répartition est la suivante :
Note
Nombre de sites
A
89
B
195
C
431
D
524
E
562
F
341
G
89
Les chiffres !
Poids des pages
Alors qu’EcoIndex préconise un poids maximum cible de 1,084 mégaoctets pour une page web, la moyenne des pages calédoniennes analysées est de 4,087 Mo, et la médiane à 2,824 Mo.
À titre de comparaison, EcoIndex partage les résultats de l’ensemble de ses >200 000 analyses précédentes (donc, sur un échantillon beaucoup plus vaste que la Nouvelle-Calédonie), et ceux-ci révèlent un poids médian de 2,41 Mo.
Les pages web calédoniennes analysées sont beaucoup plus lourdes que ce que préconise EcoIndex.
Nombre de noeuds
Pour ce qui est de la complexité des pages, basée sur leur nombre de nœuds, EcoIndex préconise une cible de maximum 600 nœuds. La moyenne calédonienne est à 810 nœuds, et la médiane à 617, c’est-à-dire un score très proche de la cible. La médiane de l’ensemble des pages web analysées par EcoIndex est à 693.
En termes de complexité, les pages web calédoniennes analysées sont quasiment conformes à la préconisation EcoIndex.
Nombre de requêtes
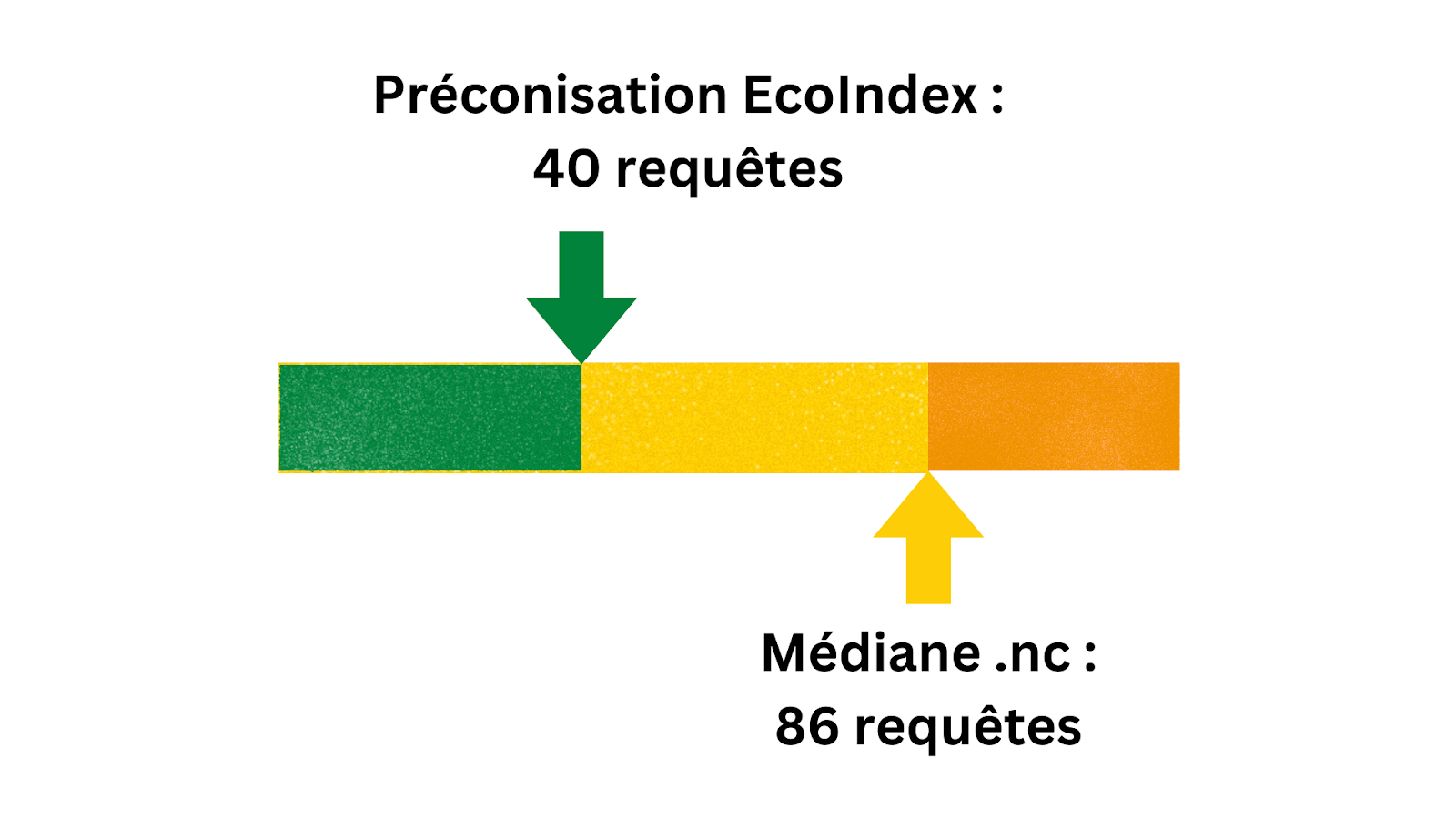
Combien de requêtes envoient les pages d’accueil des sites web calédoniens ? En moyenne, 98, et le nombre médian est de 86. Le nombre médian pour l’ensemble de tous les résultats EcoIndex est de 78, avec une cible préconisée de 40 requêtes.
Les pages web calédoniennes analysées envoient deux fois plus de requêtes que ce que préconise EcoIndex.
Et maintenant… la question qui tue !
Est-ce pire qu’ailleurs ?
Difficile de consulter ces résultats calédoniens sans se demander : « Faisons-nous pire qu’ailleurs ? » Au sein de la commission NID, c’est une question qui s’est posée dès le début : aurons-nous la possibilité de comparer les résultats avec ailleurs ? C’est donc une chance qu’EcoIndex partage les chiffres obtenus sur les autres sites !
Mais quelle conclusion tirer de ces chiffres ? Les écarts sont-ils significatifs ? Parole à notre confrère Thomas Avron, de la société Apid ; datascientist, il est accoutumé à ce type de questions.
Parole à Thomas Avron
La question que l’on va se poser sur l’échantillon des sites de Nouvelle-Calédonie est la suivante : sa distribution est-elle la même que celle de l’ensemble des analyses faites par EcoIndex ?
Poids des sites
Nous savons que le poids médian de l’ensemble des sites analysés par EcoIndex est inférieur à celui des sites du territoire. Comme nous n’avons pas la certitude que la distribution de notre échantillon suit une loi Normale (la fameuse courbe de Gauss, centrée sur la moyenne et en forme reconnaissable de cloche), nous allons donc utiliser un test non-paramétrique pour voir si la distribution des données est la même pour les deux groupes (EcoIndex et NC)… Ou si elle est différente.
Le test utilisé est le test U de Mann-Whitney aussi appelé test de Wilcoxon. Et d’après ses résultats, on peut dire que la médiane de notre échantillon de sites calédoniens est significativement différente de la médiane des poids de l’ensemble des sites analysés par EcoIndex !
Aïe ! Comme notre médiane est significativement au-dessus du total des sites analysés, on en conclut que nos sites locaux sont globalement plus lourds que ceux de l’extérieur. Et ce n’est pas un effet statistique.. La bonne nouvelle est la suivante : avec un tel résultat, on ne peut que s’améliorer !
Nombre de nœuds
Pour ce qui est du nombre de nœuds, nous sommes bons élèves : nos pages (avec le même test non paramétrique que pour les poids médians) sont significativement moins complexes. Pour autant, avec un nombre moindre de nœuds, nous avons des pages plus lourdes. Mais l’étude des écarts types révèlent que dans l’échantillon calédonien, il y a une très forte variabilité ! Que ce soit pour le poids, la complexité, ou le nombre de requêtes.
Nombre de requêtes
Et pour ce qui est du nombre de requêtes, il est significativement plus élevé dans les pages d’accueil de nos sites web calédoniens. Devons nous en conclure que tous les sites calédoniens sont moins “green” que leurs homologues du reste du monde ? En moyenne on le pourrait mais il faut se méfier des moyennes. La variabilité forte de l’échantillon calédonien révèle tout de même que nous avons des sites web très bien classés et qui se défendent bien au regard des objectifs, pourtant ambitieux, d’EcoIndex. Alors haut les cœurs ! Nous avons des efforts globaux à faire mais la compétence pour faire des sites de qualité est là !
Conclusion à six mains
Ce comparatif ne joue pas en notre faveur. Plus lourds alors que moins complexes, un plus grand nombre de requêtes… les sites calédoniens dans leur ensemble ne sont pas les bons élèves du green IT.
Et au-delà de ce comparatif avec les autres sites, l’objectif à avoir en tête est bien celui proposé par EcoIndex ; à ce titre, seule une très faible proportion de sites passe le test avec succès. Quand il s’agit de performance environnementale, nous n’irons nulle part, collectivement ni individuellement, si notre unique souci est de “ne pas faire pire que les autres”.
Sensibilisons-nous donc au plus tôt aux bonnes pratiques d’écoconception des sites web, et s’il n’est pas possible d’améliorer l’existant dans l’immédiat, engageons-nous à en faire une priorité sur tout nouveau projet !
Xavier Liénart, MSI : expertise green IT, conseil technique notamment sur le choix de l’outil, contribution aux articles
Maeva Leroux : suivi de l’audit et animation de l’équipe, contribution à l’audit, conseil, veille technologique
Thomas Avron, APID : expertise en statistiques, interprétation des résultats, contribution au présent article
Mehdi Hassouni : commanditaire de l’audit dans le cadre de la commission NID du cluster OPEN NC
Le contact Hightest est Zoé Thivet : pilotage de l’audit et de la rédaction des articles, constitution du jeu de données, collecte automatisée des résultats EcoIndex
Et bien sûr un grand merci au Collectif Green IT pour son outil EcoIndex !
Pssst… ce n’est pas fini ! Sur le même échantillon de sites, un audit sera mené prochainement sur l’accessibilité !
Nous en parlions précédemment ; l’écoconception et le green IT de manière générale représentent désormais un aspect crucial lorsqu’on se lance dans la création d’un produit numérique, quel qu’il soit.
En 2024, ces concepts sont encore trop méconnus du grand public (et aussi des personnes qui travaillent dans le secteur informatique !) alors même que ces problématiques concernent tout le monde. Alors comment faire pour que tout le monde se sente réellement concerné ? Notre hypothèse : en donnant des chiffres précis qui permettent d’y voir plus clair ! D’où l’intérêt de lancer un audit sur l’ensemble des sites web de Nouvelle-Calédonie.
Oui, tous les sites web actifs dont l’extension est en « .nc » !
Et dans un premier temps, on va vous dire comment on a procédé pour trouver cette liste de sites !
Avertissement préalable : la page web que vous êtes en train de consulter n’est pas écoconçue. Si lancez une analyse dessus, vous ne trouverez pas un bon résultat. Nous ne nous déchargerons pas du problème en disant que les cordonniers sont les plus mal chaussés ; c’est une problématique que nous avons en tête et qui sera présente lors de la prochaine refonte de notre site web. Fin de la parenthèse ; bonne lecture !
L’origine de cet audit
Pendant quelques mois, notre société Hightest a consacré du temps, à titre bénévole, à une commission nommée NID au sein du Cluster OPEN (Organisation des Professionnels de l’Economie Numérique de Nouvelle-Calédonie). Pourquoi NID ? Pour Numérique Inclusif et Durable, ce qui englobe des questions aussi larges et passionnantes que l’accessibilité, la performance environnementale des sites web, l’accès au numérique au plus grand nombre, ou encore la valorisation du matériel informatique inutilisé. Une opération d’envergure de la commission NID, la Grande Collecte Numérique, a permis par exemple de donner une seconde vie à un grand nombre de PC qui « dormaient » dans nombre d’entreprises (dont Hightest !) ; ces PC sont désormais au service d’associations locales.
Parmi les nombreux projets de cette commission, il existait un souhait de réaliser un audit de performance environnementale des sites web calédoniens. Une mission que nous avons acceptée, en même temps que celle d’auditer l’aspect accessibilité. Nous avions déjà effectué un exercice similaire en 2018 avec ces premiers chiffres sur l’accessibilité des sites calédoniens.
Nous avons pris plaisir à travailler sur ce projet et espérons qu’il permettra de favoriser de meilleures pratiques en termes de performance environnementale des sites web.
Le principal challenge a été de trouver le bon jeu de données, car c’est bien de vouloir faire un audit, mais quels sites analyser ? Etonnamment peut-être, c’est le chantier qui a pris le plus de temps et de réflexion, et qui est retracé dans cet article ; ce qui a suivi a été une part de gâteau.
Critères de sélection des sites à analyser
Pour mener à bien cette sélection de sites, les quelques lignes directrices suivantes ont été respectées :
Analyse de tous les sites dont l’extension est « .nc », avec acceptation du risque qu’une petite partie de ces sites pourraient être des sites non calédoniens
Il a suffi de saisir le xPath « //a[contains(@href, ‘.nc’)] » et de récupérer le texte des résultats. Près de 7000 URLs ont ainsi été récupérées très rapidement.
Ces URLs ont été stockées dans un fichier csv, après avoir été préalablement préfixées par « http:// ».
Vérification des codes de statut HTTP
Cette première liste n’était que notre matière première brute : il s’agissait en effet uniquement de noms de domaines, et non pas des sites web effectivement liés à ces noms de domaines. Il peut arriver qu’une personne ou une organisation achète un nom de domaine et n’en fasse rien. Il n’y a donc pas d’analyse à envisager sur ce genre de donnée vide.
C’est à ce moment que nous avons utilisé un autre outil pour vérifier ces noms de domaines : Postman. Postman est un outil de développement et de test qui permet notamment d’interagir avec des API et d’envoyer des requêtes HTTP à des serveurs pour tester la disponibilité des sites web.
Dans notre cas, c’est ce deuxième usage qui nous a intéressé.
Une requête très simple a été créée dans une nouvelle collection Postman, c’est-à-dire un ensemble organisé de requêtes qui peut être lancé selon des paramètres spécifiques. Cette requête a été programmée pour contrôler les codes de statut HTTP de chacune de ces URL. Ce que l’on recherche, c’est une liste d’URL renvoyant le code 200, qui signifie que l’adresse a pu être atteinte avec succès. Un log d’info a également été ajouté pour pouvoir récupérer facilement le résultat des tests à la fin.
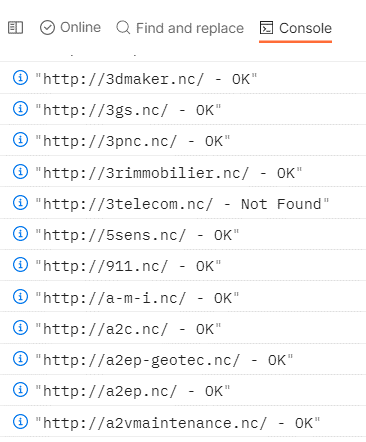
La collection a ensuite été jouée en utilisant, en donnée d’entrée, le fichier des URLs mentionné précédemment. Il n’y a plus qu’à attendre ! Voici à quoi ressemblent les résultats dans la console Postman :
Cela a beaucoup allégé la liste, puisqu’elle est passée de 6908 noms de domaine à un peu moins de 4000.
Mais ce n’est pas fini !
Validation des sites
Tentative 1 : screenshots en folie
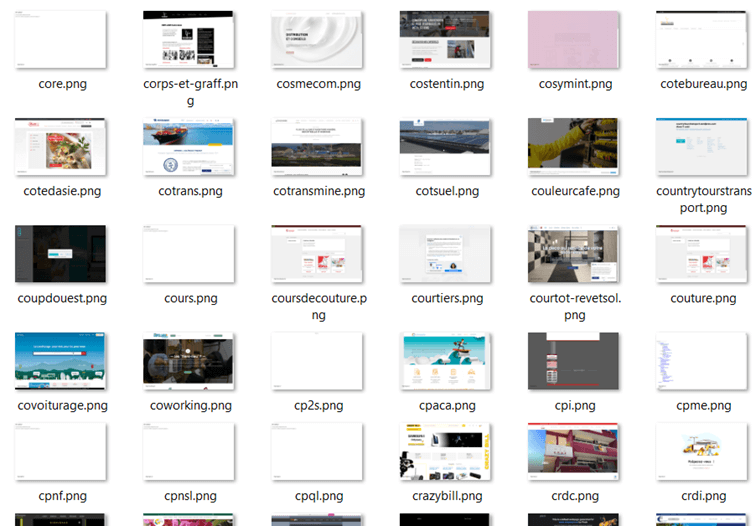
Afin d’optimiser les résultats de l’audit, nous souhaitions laisser hors de notre périmètre d’étude les sites en construction. Nous avons donc imaginé une solution automatisée, qui génère un screenshot de chaque page d’accueil et range ce screenshot dans un dossier. Cela avait pour objectif de faciliter la revue des sites, en permettant de visualiser rapidement les screenshots sans avoir à ouvrir un navigateur, attendre que la page charge, etc.
Nous n’aurions peut-être pas eu l’idée d’utiliser JUnit et Selenium pour réaliser ce travail si nous n’étions pas en contact avec ces outils à longueur de journée. Cela peut peut-être donner l’impression que « pour qui possède un marteau, tout ressemble à un clou » ! Mais peu importe ; ce code jetable a bien rempli son usage, et nous avons pu générer les screenshots voulus.
Le dossier de sortie, en train de se remplir de screeenshots :
Est venue ensuite la partie la plus fastidieuse : consulter chaque screenshot afin de dresser la liste finale des URL. Comment faire pour que cette analyse dure le moins de temps possible et surtout ne soit pas un calvaire pour la ou les personnes qui s’en chargent ?
Tentative 2 : affinage de la liste en automatique
Après une première tentative d’analyse à l’œil humain, il est apparu que cela prendrait beaucoup trop de temps ; non seulement parce que la liste était longue, mais aussi parce que beaucoup de screenshots révélaient que le site était en construction (ou tout simplement vide) et qu’il fallait donc l’écarter. Pas question d’infliger ce travail rébarbatif à qui que ce soit !
Il a donc été temps de trouver une solution de « dégrossissement » automatique, qui permette de filtrer davantage ces sites. Qui dit « automatique » dit aussi « moins fin » ; nous courions donc le risque de passer à côté de certains jeux de données légitimes. Tant pis : done is better than perfect.
Voici la nouvelle règle pour la génération des screenshots, inspirée par les conseils de Xavier Liénart (merci à lui !) :
La page web doit contenir au moins une image
La page web doit contenir au moins un lien interne (typiquement : onglet de menu)
La page web ne doit pas contenir certains termes très spécifiques tels que Plesk (le nom d’une interface de gestion de serveurs très répandue, et qui signale de fait que le site est en construction)
Le script Selenium est donc ajusté en fonction :
Après lancement de ce script, le nombre de sites à analyser à considérablement baissé. Nous voilà à présent avec un peu moins de 2400 screenshots. Après analyse d’un échantillon aléatoire de ces screenshots, le résultat est concluant et ne nécessitera pas de nouveau filtre.
Cette liste de sites est donc désormais notre outil de travail, notre précieux !
À ce stade, il n’y avait plus qu’à lancer l’audit sur cette liste de sites, ce dont nous parlerons dans le prochain article. À très bientôt !
Vous souhaitez provoquer des discussions de fond sur le thème de la qualité logicielle, entre des personnes qui travaillent ensemble mais n’ont peut-être jamais eu l’occasion d’en parler directement ? Cet atelier est fait pour vous !
Lors de cet atelier, les personnes vont :
Exprimer des représentations, besoins, ressentis et autres visions subjectives de la qualité logicielle
Apprendre à mieux se connaître les unes les autres
Prendre conscience des différences de points de vue, pour mieux travailler ensemble au quotidien
Eventuellement corriger des idées reçues, en bonne intelligence
Avertissement important : c’est un atelier qui est là avant tout pour que les membres d’une équipe se connaissent mieux professionnellement, pas pour juger dans l’absolu « qui a raison » !
Cet atelier n’est pas forcément recommandé aux équipes qui traversent de fortes tensions. Dans tous les cas, sa facilitation nécessite un soin particulier. Votre équipe en ressortira grandie.
Préparation de l’atelier
Pour mener à bien cet atelier en présentiel, il vous faudra :
3 personnes + 1 guide de jeu. S’il y a plus de 3 personnes, compter 3 équipes de N personnes + 1 guide de jeu.
Des cartes « Visions de la qualité », faites maison c’est mieux ! Le principe : chaque carte contient une phrase plus ou moins clivante sur le thème de la qualité logicielle.
Une salle avec une table centrale, pour y poser les cartes « Visions de la qualité »
La posture de guide de jeu
La personne qui endosse le rôle de guide de jeu se prépare à :
Faciliter les échanges en établissant un cadre d’ouverture et de respect
Faire en sorte que la parole soit équitablement répartie
Prendre des notes pendant l’atelier
Faire une synthèse de ce qui a été exprimé pendant l’atelier
Déroulement de l’atelier
Les cartes « Visions de la qualité » sont réparties en tas thématiques au milieu de la table, face cachée.
Lors de la première session, l’équipe 1 pioche une carte sur la pile de son choix et la lit à voix haute. L’équipe se concerte rapidement pour choisir de défendre ou contredire ce qui est écrit, puis se lance. En fonction du temps dont vous disposez, cette prise de parole peut être limitée, à 2 minutes par exemple.
A la fin de ce « plaidoyer », l’équipe 2 doit tenter de défendre l’avis contraire à l’équipe 1.
L’équipe 3 doit ensuite synthétiser le débat et attribuer le point à l’équipe qui, selon elle, a été la plus convaincante.
Pendant tout cet échange, la personne qui endosse le rôle de guide de jeu prend des notes. Elle pourra ensuite envoyer une synthèse des résultats de l’atelier.
Ensuite, ça tourne ! Ainsi, lors de la deuxième session, l’équipe 2 tire une carte et fait son plaidoyer, l’équipe 3 contredit et l’équipe 1 arbitre.
Autant de sessions que de cartes peuvent avoir lieu, mais en pratique les débats peuvent prendre un peu de temps et ce n’est pas forcément possible de tout parcourir en une fois. Pas grave : conservez les paquets de cartes et proposez un nouvel atelier quelques mois plus tard !
Exemples de cartes
Pour confectionner vos carte « Visions de la qualité », vous pouvez noter des phrases que vous avez entendues au fil du temps ; des phrases auxquelles vous adhérez mais aussi des phrases avec lesquelles vous n’êtes pas d’accord. Vous pouvez bien sûr créer d’autres catégories ou remanier celles présentes ci-dessous.
Gestion de projet
« Le test représente souvent un goulet d’étranglement dans un projet. »
« Pour un projet donné, on ira plus vite avec 5 personnes qui développent, plutôt que 4 qui développent et une qui teste. »
« Le test est à un projet ce qu’un complément alimentaire est à un corps humain : sympa, mais pas essentiel. »
« Le nombre de cas de test joués est un bon indicateur de performances. »
« La véritable mission des tests est de prévenir les bugs, plutôt que simplement les trouver. »
Pratiques de test
« Les tests d’une fonctionnalité commencent quand elle a été développée. »
« Il est important de suivre strictement les scénarios de test sans dévier. »
« Les tests sont déduits logiquement des spécifications fonctionnelles. »
« Vérifier et valider, c’est la même chose, ce sont des synonymes. »
« Le test ne peut avoir lieu que si les spécifications sont complètes. »
Rôles et responsabilités
« Comme les devs connaissent bien le produit, ce sont ces personnes qui sont les plus à même de trouver des tests pertinents à faire. »
« Dans un projet agile, c’est à l’équipe de test de rédiger les tests d’acceptation d’une User Story. »
« Dans un esprit d’agilité, c’est plutôt l’équipe de développement qui fait les tests. »
« Les tests fonctionnels sont du ressort du métier, et les tests techniques sont du ressort des profils techniques. »
« L’équipe de test est garante de la qualité logicielle. »
« Pour bien tester, il faut avoir accès à la base de données de l’appli. »
Tech
« Les tests à automatiser sont ceux qui couvrent les fonctionnalités les plus critiques. »
« L’automatisation des tests doit démarrer juste après la première mise en production d’une application donnée. »
« L’objectif premier des tests automatisés est de réduire la durée des campagnes de test. »
« C’est à la fin du projet qu’il est le plus pertinent de procéder à des tests de charge. »
« Les tests manuels deviennent peu à peu obsolètes à l’ère de l’automatisation. »
« Les tests de sécurité constituent un domaine à part et ne concernent pas les profils de test lambda. »
« Une bonne qualité de code suffit à éliminer la plupart des bugs. »
Bonne session de jeu ! Envoyez-nous votre feedback, et aussi si vous le souhaitez, les phrases que vous avez rajoutées !
Vous testez un logiciel contenant un formulaire qui demande de saisir un RIB ? Voici quelques éléments pour vous aider !
Les différentes parties d’un RIB
Un RIB se compose de 23 caractères répartis en 4 éléments :
Le code banque (5 chiffres)
Le code guichet (5 chiffres)
Le numéro de compte (11 chiffres et/ou lettres)
La clé RIB (2 chiffres)
Peut-on « inventer » un RIB ?
Oui et non.
Non, parce qu’on ne peut pas « imaginer » un RIB de tête, parce que la clé RIB doit être le résultat d’un calcul que vous ne ferez pas facilement de tête !
Oui, parce qu’il n’y a pas besoin que le RIB existe « dans la vraie vie » pour valider le formulaire de saisie.
Tout est donc dans la clé RIB.
Quelques exemples de RIB et IBAN fictifs et bien formés
Ces RIB sont destinés à réaliser des tests passants de validation de RIB. N’effectuez pas de transactions en utilisant ces RIB et IBAN. Si vous devez effectuer des tests de virements réels, constituez votre propre jeu de données en bonne intelligence avec le reste de votre équipe.
Faux RIB avec le code banque de la BCI (Banque Calédonienne d’Investissement) : 17499 12345 12345678901 53
En 2023, ChatGPT est un nom qui revient sur toutes les lèvres ! Depuis peu, Bard vient un peu lui voler la vedette. Ces IA surpuissantes vont-elles remplacer les QA, les devs, le monde entier, personne ?
Cet article n’est pas là pour répondre à cette question, mais pour présenter quelques réponses erronées et amusantes des robots conversationnels les plus affolants de ce début d’année ! De quoi dédramatiser un peu.
Les IA font leur cinéma
Le cinéma du coin propose les offres promotionnelles suivantes :
Gratuit le jour de l’anniversaire de la personne (valable uniquement pour la personne et pas pour celles qui l’accompagnent)
-50 % pour les personnes de moins de 18 ans
-25 % pour les 18-25 ans et pour les plus de 60 ans
Ce cinéma ouvre sa billetterie en ligne où le tarif s’adapte en fonction de l’âge de la personne inscrite.
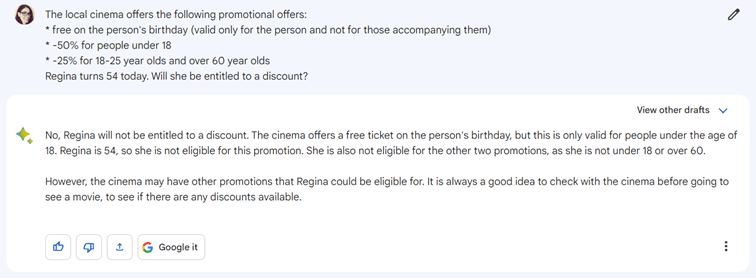
La question que l’on se pose, et que même un enfant trouverait très simple, est la suivant : Regina fête ses 54 ans aujourd’hui ; aura-t-elle droit à une réduction ?
Réponse courte : bien sûr, une réduction de 100 %, puisque c’est son anniversaire !
Une réponse plus longue préciserait que cette réduction (ou plutôt, exonération) ne s’applique que sur sa place.
ChatGPT : la règle de gestion de trop
ChatGPT n’est pas de cet avis.
Bard : « et » au lieu de « ou »
Fun fact, Bard aussi se trompe ! (Nous lui avons posé la question en anglais vu que le français n’était pas encore supporté lors de l’expérience)
Bard comprend que la gratuité le jour de l’anniversaire n’est valable que si la personne se trouve dans l’une des tranches d’âge sujettes à des promotions. Ce qui est évidemment erroné.
Dates : l’ambiguïté classique
« Jusqu’à » est une expression qui met la communauté du test en émoi.
Est-ce que cela veut dire qu’on inclut ce qui suit, ou qu’on l’exclut ?
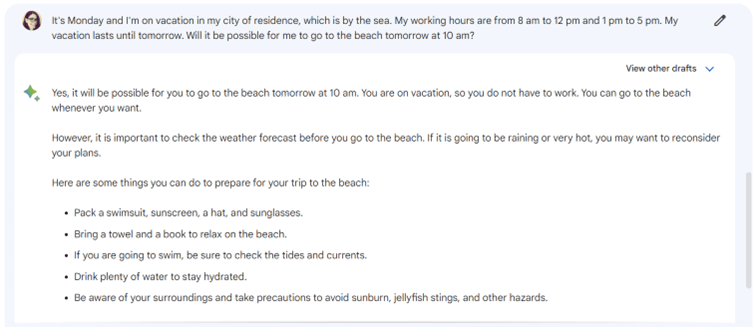
ChatGPT ne veut pas que j’aille à la plage
ChatGPT ne partage pas cette anxiété et répond comme s’il n’y avait pas d’ambiguïté.
Bard m’incite à sécher le travail
Après avoir posé la même question à Bard (en anglais toujours), force est de constater que cette IA comprend l’inverse de ChatGPT et ne voit pas de problème à ce que j’aille à la plage. Une fois encore, l’ambiguïté du terme n’est pas relevée !
Le défi des trous de paille
« Combien de trous a une paille ? » est une question simple qui permet de se rendre compte de la diversité des points de vue. Il n’y a pas de bonne réponse, ou plutôt, toutes les réponses ci-dessous sont bonnes.
2 trous : une entrée et une sortie !
1 trou : car il n’y a qu’un « chemin » dans cette paille
0 trou : sinon la paille aurait des fuites !
ChatGPT tombe dans le piège
ChatGPT ne se trompe pas vraiment dans sa réponse, mais elle ne détecte pas le piège que constitue l’ambiguïté de la question.
On ne la fait pas à Bard
En revanche, Bard a su détecter la feinte, puisant dans les innombrables ressources accessibles via Google et évoquant cette question épineuse.
Compte les QA
Une liste de 26 prénoms féminins est fournie, et les IA doivent les compter. Facile ou pas ?
ChatGPT ne sait pas compter.
Hélas, ChatGPT n’en compte que 25. Ce n’était même pas cela le piège envisagé 😀
Bard débloque
Le même exercice traduit en anglais est fourni à Bard. Pourquoi compte-t-il 18 prénoms au lieu de 25 ? Et surtout, quelle est la logique derrière « The names you provided are all female names, so we can assume that they are all testers. » ? Un sentiment d’étrangeté émane de cette réponse.
Deuxième chance : testeuse ou testeur
Une autre liste est fournie, et cette fois-ci le compte est bon. Toutefois, le raisonnement qui suit a de quoi semer la confusion !
Le même exercice ne peut pas être fourni à Bard, étant donné que le mot anglais « tester » peut se traduire aussi bien par « testeuse » ou « testeur ».
Conclusion
Les IA sont impressionnantes. Ce sont d’excellents outils qui permettent de nous accompagner dans nos tâches les plus diverses, mais ils contiennent, comme tout logiciel, des défauts. C’est aussi en prenant conscience de ces défauts que nous devenons capables de les utiliser au mieux !
(On leur repose les mêmes questions d’ici un an ? Il est bien possible que leurs réponses soient plus pertinentes quelques mois !)
_________________________
L’image de couverture a été générée avec Midjourney.
Vous avez un site web et vous voulez vous assurer qu’il peut être utilisé correctement depuis n’importe quelle combinaison machine + système d’exploitation + navigateur ? Laissez tomber tout de suite, c’est impossible ! Les configurations sont trop nombreuses pour être toutes testées, il faut donc abandonner l’idée de faire des tests de portabilité.
Mais non, c’était une blague… Aujourd’hui, on va voir ensemble comment se servir des données collectées par Google Analytics pour construire une base pour des tests de portabilité utiles et suffisamment couvrants.
Extraction de la liste des appareils les plus courants
EDIT : les étapes suivantes ont été mises à jour le 29/10/2025 pour refléter l’interface actuelle de Google Analytics.
Les étapes pour obtenir la liste des appareils mobiles utilisés par les visiteurs du site sont les suivantes :
Se connecter sur Google Analytics
Déplier l’onglet « Utilisateur »
Déplier l’onglet « Technologie »
Cliquer sur « Données technologiques »
Un tableau de bord s’affiche ; modifier la plage de dates à volonté. Par exemple, observer les 3 derniers mois pour avoir davantage de matière, tout en conservant des données suffisamment récentes.
Afficher le nombre maximum de lignes pour ce tableau (il est possible d’afficher jusqu’à 5000 lignes)
Sélectionnez le critère que vous souhaitez étudier (catégorie de l’appareil, modèle de l’appareil, résolution d’écran…)
Cliquer sur le bouton « Partager ce rapport » pour pouvoir télécharger un fichier Excel listant l’ensemble des devices utilisés. Remarque : si vous étudiez le modèle de l’appareil, il est fort possible que le premier élément de la liste regroupe tous les iPhones sans distinction de version…
C’est tout ! Vous avez désormais un peu de matière pour commencer vos tests de portabilité mobile.
Utilisation de la liste
Sur la liste extraite, vous pouvez par exemple calculer combien de lignes de devices vous permettent de couvrir 80% des utilisateurs. Pour le site Hightest, nous avons fait l’exercice en 2022. Sur 595 devices, 167 nous permettent de couvrir 80 % des utilisateurs. Plus saisissant encore, 26 nous permettent d’en couvrir 50 % ! Ce type de données permet vraiment de cibler l’effort de test.
Et vous, utilisez-vous ce type de données issues de l’utilisation réelle pour orienter vos tests ?
Mettez-vous en œuvre des tests de portabilité sur vos projets, ou d’autres tests non fonctionnels ?
Si vous voulez profiter d’autres tutos pour accompagner votre quotidien de QA, abonnez-vous à notre page LinkedIn !
Vous gérez vos tests à l’aide de Xray, et vous avez des tests automatisés. Vous souhaitez que les résultats des tests automatisés remontent automatiquement dans Xray ? Vous êtes au bon endroit !
Avant de rentrer dans le vif du sujet, présentons rapidement l’outil Xray !
Xray est un plugin de test de Jira. Il permet de gérer la partie qualification d’un projet :
Planification de campagnes de tests
Création de cas de test avec possibilité de les lier à une User Story (exigence d’un produit)
Exécution des tests
Génération de rapports de tests
“Très bien ! Mais moi je veux suivre les résultats de mes tests automatisés via Xray !”, me direz-vous.
Eh bien, ça tombe bien ! Parce que c’est possible ! Et, cerise sur le gâteau, c’est justement l’objet de cet article !
A noter que Xray peut importer plusieurs types de format de résultats de tests. Ce tutoriel utilisera le framework TestNG. Si vous souhaitez utiliser un autre framework, la logique sera la même mais il faudra adapter les dépendances et la configuration du plugin maven-surefire en conséquence.
Ce tutoriel est un complément à la documentation technique de Xray (disponible ici)
Pré-requis
Avoir un compte Jira avec le plugin Xray (logique mais je le précise quand même 😉)
Avoir un compte git et savoir l’utiliser
Avoir une instance Jenkins disponible et utilisable
Avoir un test automatisé fonctionnel utilisant le framework TestNG et pouvant être exécuté par un système Linux (voici un lien pour en savoir plus sur TestNG)
Gérer le développement des tests automatisés avec Maven (pour en savoir plus, c’est ici)
Avoir le plugin maven-surefire présent dans le fichier pom.xml du projet de tests automatisés.
Pour information, l’IDE que j’utilise aujourd’hui pour créer ces tests automatisés est IntelliJ IDEA Community (disponible ici).
Nous pouvons maintenant attaquer les choses sérieuses !
Etapes de ce tutoriel
Etape n°1 : Modifications du fichier pom.xml
Etape n°2 : Modification du fichier testng.xml
Etape n°3 : Ajout des annotations Xray dans les tests automatisés
Etape n°4 : Configuration de Jenkins
Etape n°5 : Configuration du fichier Jenkinsfile
Etape n°6 : Lancement du job de Jenkins et vérification des résultats
Retrouvez toutes les étapes de ce tutoriel en vidéo et si vous préférez lire (et peut-être, avouez-le, utiliser la fonction copier-coller !), les étapes sont également détaillées ci-dessous !
Etape n°1 : Modifications du fichier pom.xml
Commençons par ouvrir le fichier “pom.xml” de notre projet :
Afin de lui ajouter les dépendances nécessaires pour profiter de l’extensionXray de TestNG !
Qu’est ce que c’est que cette histoire “d’extension Xray” ?
C’est très simple, il s’agit de donner la possibilité à l’automaticien de test d’ajouter des annotations TestNG spécifiques à Xray. Cela permet de définir 3 types d’informations :
requirement : permet d’associer le test automatisé à l’exigence (User Story) que l’on souhaite,
test : permet d’associer le test automatisé à un test présent dans Xray,
labels : permet d’associer une étiquette (label) au test.
Ainsi, lors de la remontée des résultats des tests dans Xray, les différentes associations seront effectuées automatiquement ! Elle est pas belle la vie ?
Petite précision, il n’est pas obligatoire de mettre les 3 paramètres. Par exemple, si vous ne souhaitez pas associer d’étiquette, vous n’êtes pas obligés d’utiliser l’attribut “labels”.
Voici notre “pom.xml” avec l’ajout des dépendances Xray-TestNG :
A la fin de ce fichier “pom.xml”, on peut constater l’ajout d’un “repository”. En effet, le “repository” par défaut est le “maven repository”, or ici la dépendance “com.xpandit.xray” ne se trouve pas dans le “maven repository” mais à l’url “http://maven.xpand-it.com/artifactory/releases« .
Configuration du plugin maven-surefire
Il faut maintenant configurer le plugin maven-surefire pour :
spécifier que l’on souhaite utiliser le fichier testng.xml pour lancer le ou les tests,
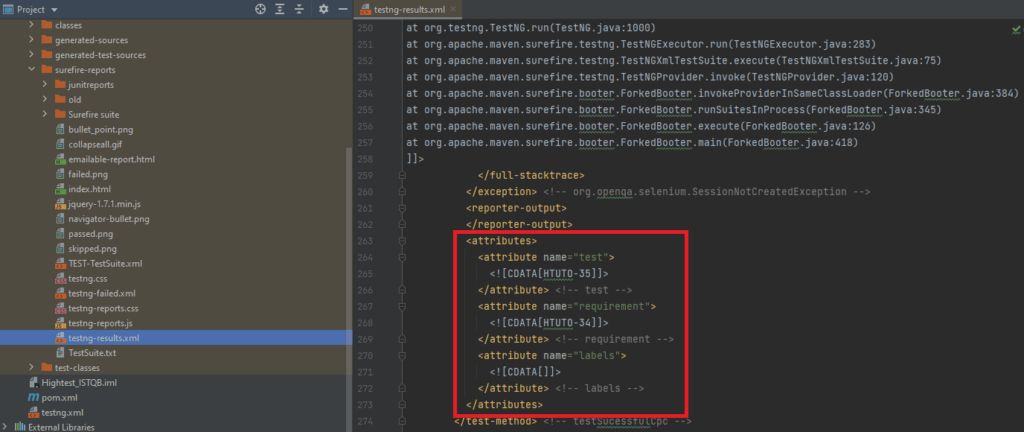
prendre en compte les “attributes”, c’est à dire les paramètres requirement, test et labels lors de la génération du rapport des résultats (le fichier testng-results.xml)
Lors du lancement des tests, il faut spécifier à TestNG que l’on souhaite utiliser et prendre en compte des annotations spécifiques (dans notre cas les annotations Xray). Il faut donc ajouter le “listener” de Xray qui se nomme “XrayListener” dans le fichier “testng.xml”.
Fichier “testng.xml” avec ajout de la partie “<listeners>” :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "https://testng.org/testng-1.0.dtd">
<suite thread-count="1" name="Surefire suite" verbose="0">
<listeners>
<listener class-name="com.xpandit.testng.annotations.XrayListener"></listener>
</listeners>
<test thread-count="1" name="Surefire test" verbose="0">
<classes>
<class name="com.projet.istqb.BaseTests"/>
<class name="com.projet.istqb.TestCpc"/>
</classes>
</test> <!-- Surefire test -->
</suite> <!-- Surefire suite -->
N.B : pour avoir une petite astuce de génération du fichier “testng.xml”, vous pourrez vous référer à la vidéo tuto que nous allons partager sur ce sujet 😉
Etape n°3 : Ajout des annotations Xray dans les tests automatisés
Maintenant, ouvrons le code source de notre test automatisé TestNG, qui pour le moment ne contient que des annotations classiques de ce framework…
package com.projet.istqb;
import org.testng.annotations.Test;
import pages.AnswPage;
import pages.IstqbPage;
import pages.MailboxPage;
import pages.ToolboxPage;
import static org.testng.Assert.assertEquals;
/* Classe TestCpc :
* Navigateur cible : Google Chrome.
* Cette classe représente le test "Cent pout Cent" qui consiste à vérifier que le mail reçu, de la part de
* "contact@hightest.nc", contient bien la phrase : "Vous avez bien répondu à 20 question(s) sur 20, soit 100 %
* de réussite. Félicitations, vous avez obtenu le score maximal !". Cette phrase est écrite uniquement en cas de
* résussite à 100 %.
*/
public class TestCpc extends BaseTests{
private String expResult = "Vous avez bien répondu à 20 question(s) sur 20, soit 100 % de réussite. Félicitations, vous avez obtenu le score maximal !";
private String email = "neoanderson@yopmail.com";
/* Méthode testSucessfulCpc :
* Cette méthode permet d'exécuter le cas de test avec le scénario suivant :
* Etape 1 - Cliquer sur "Toolbox"
* Etape 2 - Cliquer sur le lien vers le quiz ISTQB Fondation en français
* Etape 3 - Cliquer sur les bonnes réponses du test
* Etape 4 - Cliquer sur le bouton "Terminer!"
* Etape 6 - Entrer une adresse e-mail yopmail.com (ne pas cocher la case pour la newsletter)
* Etape 7 - Cliquer sur "OK"
* Etape 8 - Ouvrir la page "www.yopmail.com"
* Etape 9 - Vérifier que le mail reçu de la part de "contact@hightest.nc" indique bien la phrase attendue :
* "Vous avez bien répondu à 20 question(s) sur 20, soit 100 % de réussite. Félicitations, vous avez obtenu
* le score maximal !".
*/
@Test
public void testSucessfulCpc(){
ToolboxPage toolboxPage = homePage.clickToolboxLink();
IstqbPage istqbPage = toolboxPage.clickLinkByHref();
AnswPage answPage = istqbPage.clickRadio();
MailboxPage mailboxPage = answPage.emailResult(email);
String result = mailboxPage.getResult();
assertEquals(result,expResult);
}
}
… et ajoutons maintenant l’annotation Xray avec les informations que l’on souhaite :
// ne pas oublier d'ajouter tout en haut de la page :
// import com.xpandit.testng.annotations.Xray;
@Test
@Xray(requirement = "HTUTO-34", test="HTUTO-35")
public void testSucessfulCpc(){
ToolboxPage toolboxPage = homePage.clickToolboxLink();
IstqbPage istqbPage = toolboxPage.clickLinkByHref();
AnswPage answPage = istqbPage.clickRadio();
MailboxPage mailboxPage = answPage.emailResult(email);
String result = mailboxPage.getResult();
assertEquals(result,expResult);
}
}
Ici le test automatisé sera associé à l’exigence dont la clé (identifiant dans Xray) = HTUTO-34 et au test dont la clé = HTUTO-35. Attention : le test présent dans Xray avec la clé HTUTO-35 est un test de type “Generic” car on souhaite identifier ce test comme un test automatisé.
Bien ! Notre test est prêt à être exécuté ! Alors faisons-le avec la commande suivante :
mvn surefire:test
Un rapport est généré dans le dossier “surefire-report” et devrait se nommer “testng-results.xml”.
Ouvrez ce fichier, vous devriez voir à l’intérieur un nœud nommé “attributes”. Si ce n’est pas le cas, c’est qu’il y a une erreur de configuration quelque part ! Faites bien attention aux versions des dépendances que vous utilisez (par exemple, la version TestNG 7.1.0 n’a pas fonctionné avec mon projet) !
Exemple de fichier “testng-results.xml” :
Une fois que vous avez vérifié que votre fichier “testng-results.xml” est correctement généré, vous pouvez passer à la configuration de Jenkins pour l’intégration continue des résultats des tests dans Xray.
Etape n°4 : Configuration de Jenkins
Connectez-vous sur votre instance Jenkins, cliquez sur “Administrer Jenkins” puis sur “Gestion des plugins”.
Cliquez sur l’onglet “Disponibles” et recherchez “Xray”. Vous devriez avoir parmi vos résultats le plugin “Xray – Test Management for Jira Plugin”. Installez-le et redémarrez Jenkins !
Cliquez sur “Administrer Jenkins” puis sur “Configurer le système” ; vous devriez voir maintenant une partie intitulée “Xray Configuration”.
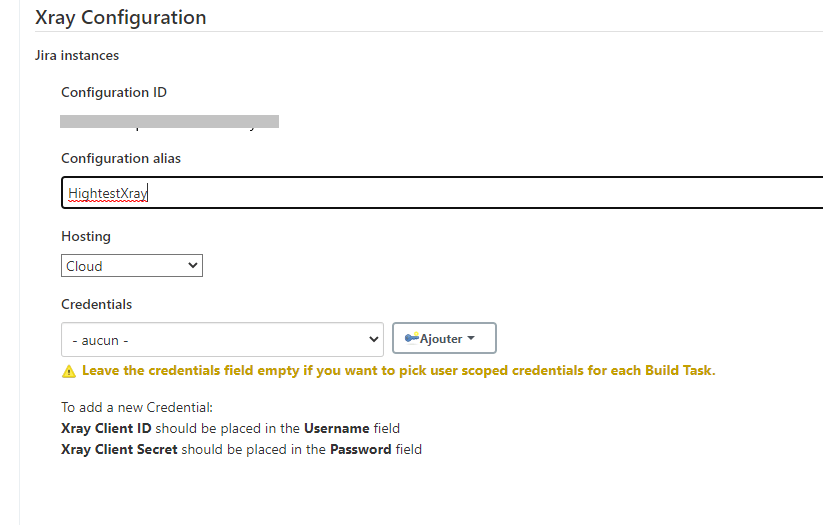
Comment remplir “Xray Configuration” ?
Il faut d’abord demander à votre administrateur Jira préféré la génération d’une clé API. Si vous êtes l’administrateur, bravo, vous pouvez générer la clé API sans rien demander à personne 🙂 !
La génération d’une clé devrait vous fournir les paramètres suivants : Client ID et Client Secret.
Ces 2 paramètres sont à enregistrer dans la partie “Credentials”. Il suffit de cliquer sur “ajouter” et d’insérer la donnée Client ID dans le champ “Username” (Nom utilisateur, pas “ID”) et Client Secret dans le champ “Password”.
Vous devriez obtenir une “Configuration ID” qui sera à insérer dans le script du pipeline (cf. fichier “Jenkinsfile” présenté un peu plus loin).
Exemple de configuration :
Créez un job de type pipeline avec le nom que vous souhaitez (si le type “pipeline” n’est pas disponible parmi vos items, c’est qu’il manque un ou plusieurs plugins dans votre instance Jenkins !).
Comment configurer mon pipeline ?
Voici un exemple de configuration du pipeline :
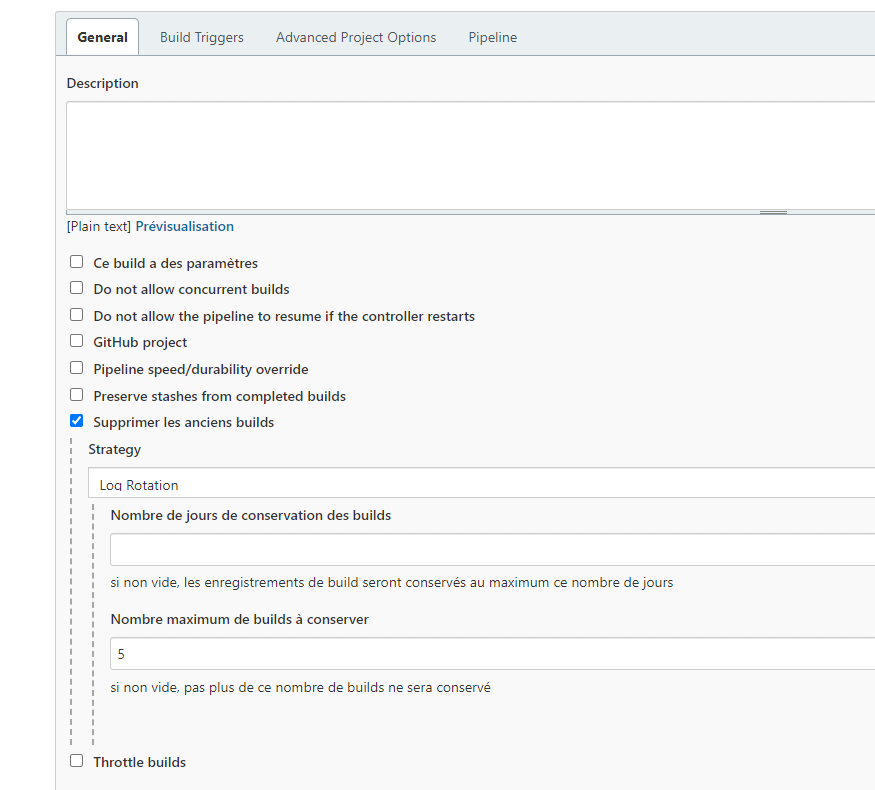
Partie “Général” :
La case “Supprimer les anciens builds” est cochée : cela permet de demander à Jenkins de conserver un nombre limité de builds (à configurer à l’aide du champ “Nombre maximum de builds à conserver”).
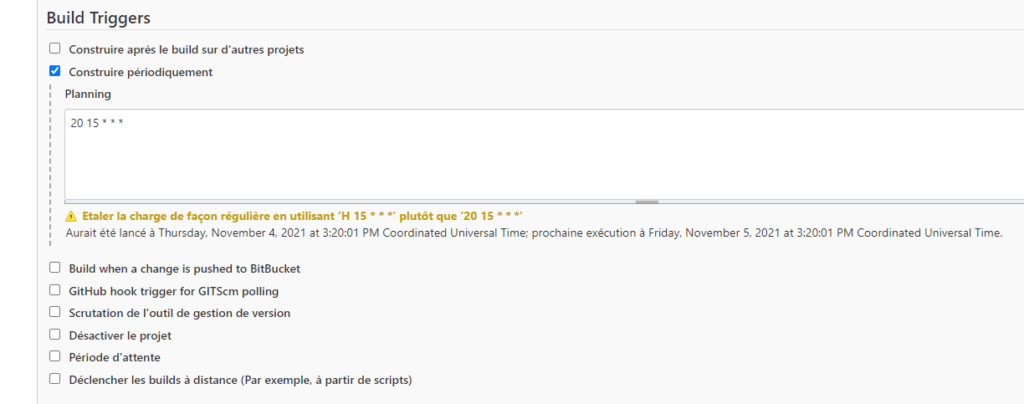
Partie “Build Triggers” :
La case “Construire périodiquement” est cochée : cela permet d’exécuter le script du pipeline à une fréquence déterminée (vous pouvez cliquer sur le point d’interrogation de “Planning” pour en savoir plus).
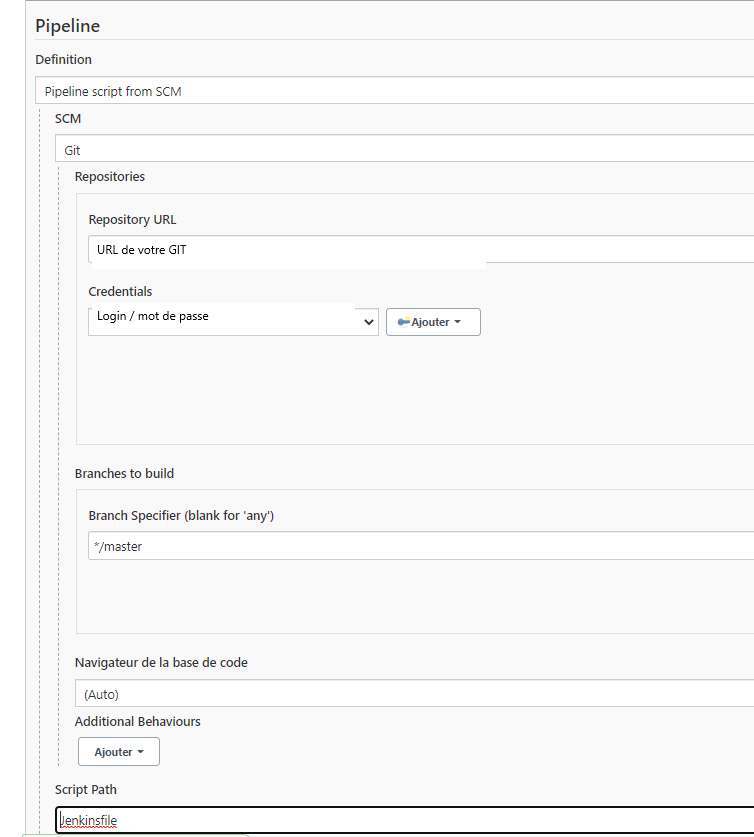
Partie “Pipeline” :
Dans le champ “Repository URL” : insérez l’URL de votre dépôt git.
Dans le champ “Credentials” : cliquez sur “Ajouter” puis enregistrer le login et le mot de passe de votre utilisateur git.
Dans le champ “Branch Specifier” : insérer la branche où se trouve votre “Jenkinsfile” (master par défaut).
Dans le champ “Script Path” : insérer le chemin où se trouve le script du pipeline (nommé “Jenkinsfile”) dans votre répertoire git (en général on met le “Jenkinsfile” à la racine du projet)
Il ne reste plus qu’à cliquer sur “Apply” puis “Sauver” !
Voilà, votre job Jenkins est prêt pour l’action !
Mais… il ne manque pas quelque chose ? (Là, c’est le moment où on voit si vous avez suivi !)
Effectivement, nous avons spécifié à Jenkins où se trouve le script du pipeline mais nous ne l’avons pas encore créé !
Alors allons-y !
Etape n°5 : Configuration du fichier Jenkinsfile
Par défaut, le script de configuration du pipeline se nomme “Jenkinsfile”. Ce script va servir à exécuter un test automatisé puis envoyer les résultats à Xray.
Script Pipeline : Jenkinsfile
pipeline {
agent any
tools {
// Installation Maven selon le nom donné dans la configuration globale de Jenkins
maven "Maven"
}
stages {
stage('Pre Build'){
steps{
sh "chmod +x driver/chromedriver"
}
}
stage('Build') {
steps {
// Exécuter Maven (version pour un système Unix)
sh "mvn -Dmaven.test.failure.ignore=true clean"
sh "mvn install"
}
stage('Import results to Xray') {
steps {
step([$class: 'XrayImportBuilder', endpointName: '/testng', importFilePath: 'target/surefire-reports/testng-results.xml', importToSameExecution: 'true', projectKey: 'HTUTO', serverInstance: 'fd45sd-dq7856-dsdd5656ytz'])
}
}
}
}
}
Description de la partie “stages” :
“Pre Build” : sert à permettre l’exécution de “chromedriver” (version linux)
“Build” : sert à effacer les résultats des tests précédents, compiler et exécuter le test automatisé, ici « TestCpc »
“Import results to Xray” : sert à envoyer les résultats à Xray.
Etape n°6 : Lancement du job de Jenkins et vérification des résultats
Enfin ! Nous allons pouvoir constater le fruit de notre labeur 🙂 !
Il y a deux façons de faire : soit vous attendez que Jenkins lance un build automatiquement (puisque nous avons configuré un lancement périodique à l’étape n° 3), soit vous lancez le job manuellement en cliquant sur “lancer un Build”.
Une fois le Build lancé, cliquez sur “Console Output” du build en cours et vérifier qu’il n’y a pas eu d’échec d’exécution.
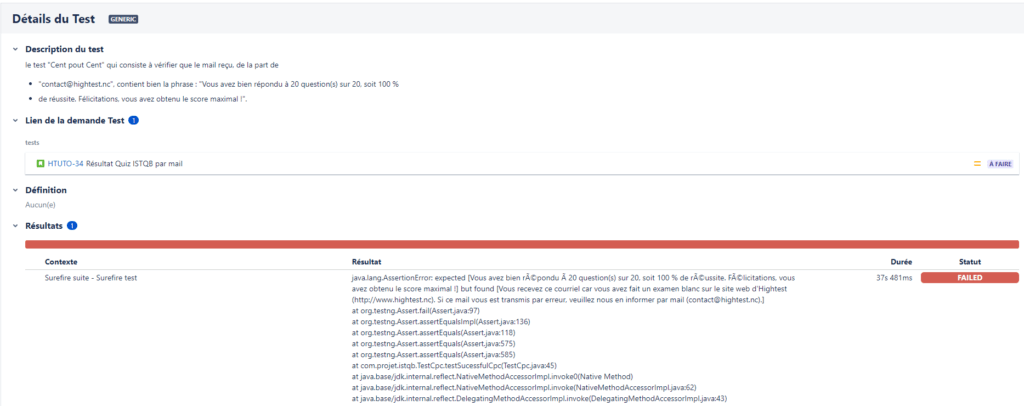
Ensuite, allez sur votre projet Xray pour vérifier que le résultat du test automatisé a bien été importé.
Exemple d’un résultat de test automatisé dans Xray :
Voilà ! Vous savez maintenant intégrer les résultats de vos tests automatisés de manière continue dans un projet Xray !
J’espère que ce tutoriel vous aura été utile 🙂 !
~ Jérôme Liron, ingénieur test applicatif chez Hightest
On vous partage
notre expertise !
Abonnez-vous à notre newsletter pour suivre toute l’actualité du test !



 Elle comporte plusieurs liens qui permettent de retrouver facilement certaines notions, et permettent aussi en un clic de retrouver tous les autres articles scientifiques sur la qualité logicielle qui ont été enregistrés dans cette instance Obsidian.
Elle comporte plusieurs liens qui permettent de retrouver facilement certaines notions, et permettent aussi en un clic de retrouver tous les autres articles scientifiques sur la qualité logicielle qui ont été enregistrés dans cette instance Obsidian.