« L’automatisation des tests, ça coûte cher ! »
Voilà une idée reçue qui freine bon nombre de personnes au moment de mettre en place une démarche d’automatisation des tests.
Il est vrai que les écueils existent, mais certaines démarches permettent de limiter ces risques et de mettre en œuvre, rapidement, des projets d’automatisation couronnés de succès. Dans cet article, nous allons présenter un moyen simple et efficace de maîtriser ces coûts… voire d’obtenir un ROI immédiat.
Le DDT, qu’est-ce que c’est ?
DDT est l’appellation courte de dichlorodiphényltrichloroéthane, mais nous ne parlons pas aujourd’hui de chimie et nous n’allons pas non plus vous suggérer de pulvériser de l’insecticides sur les bugs… car c’est aussi l’acronyme du Data Driven Testing !
Pourquoi implémenter le Data Driven Testing ?
Cette pratique présente au moins 3 avantages.
- Le code est plus clair et plus concis. Finis les doublons, finies les données en dur !
- L’ensemble des parties prenantes peut consulter et modifier les données sans avoir à lire le code. Cela rend ainsi plus accessible le sujet d’automatisation des tests aux personnes qui ne savent pas ou ne souhaitent pas développer.
- Et surtout… Ça permet de gagner beaucoup de temps.
Dans quel contexte mettre en œuvre cette pratique ?
Dans notre article précédent, nous donnions des axes de réflexion pour choisir quels tests automatiser. L’un des axes consiste à déterminer quels tests sont les plus répétitititititi…tifs. Vous voyez l’idée : vous avez un unique formulaire, des centaines de manières différentes de le remplir, et une ribambelle de champs à vérifier en sortie. Réaliser ces tests des heures d’affilée peut relever du supplice intellectuel, et les déléguer à quelqu’un d’autre n’est pas beaucoup plus sympathique.
Dans ce contexte, le Data Driven Testing est tout particulièrement pertinent.
Génial ! Par quoi commencer ?
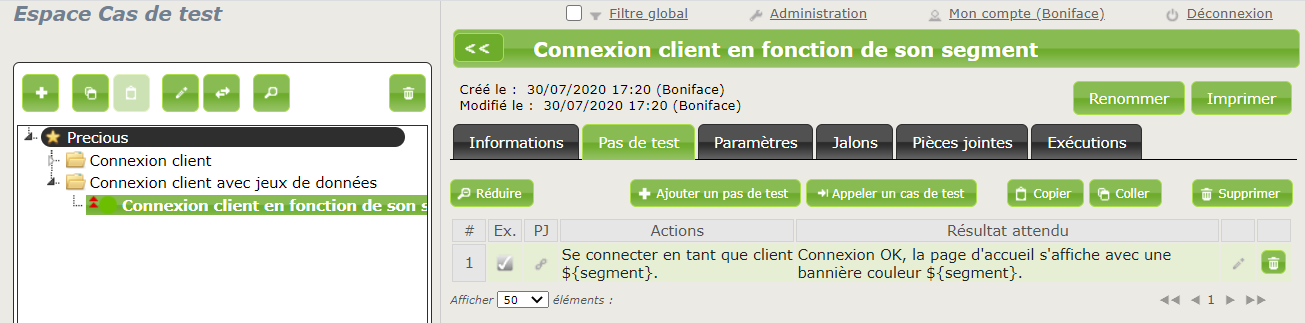
Quitte à faire une lapalissade, rappelons que le Data Driven Testing est… piloté par les données. Alors le mieux pour commencer, c’est de lister les jeux de données des tests que l’on va vouloir automatiser.
(Et si vous ne savez pas quels cas de test automatiser, nous vous suggérons de jeter un œil à cet article !)
Prenons un exemple simple : un cas de test dont l’objectif soit de vérifier qu’un champ de recherche fonctionne bien. Dans ce contexte, on peut créer un tableur, par exemple au format CSV, contenant ces 12 requêtes et leur résultat attendu.
Voici le contenu du fichier de jeux de données (qu’on appellera, pour la suite, requetes.csv) :
| requete | nb_resultats_attendus |
| Sandra Geffroid | 1 |
| Sandra | 2 |
| Sandra Géffroid | 1 |
| Sandr | 2 |
| Sandr Geffr | 1 |
| Sandro Geffroid | 1 |
| Sandro Geffroio | 0 |
| Sandrawa Geffroidwa | 0 |
| SANDRA GEFFROID | 1 |
| sandra geffroid | 1 |
| s a n d r a g e f f r o i d | 10 |
| S_a_n_d_r_a_G_e_f_f_r_o_i_d | 0 |
Ce fichier peut être rempli par les testeurs, les acteurs métiers, le PO, ou toute partie prenante souhaitant s’impliquer dans les tests. L’avantage du format tableur, c’est qu’il permet de collaborer en toute simplicité. On est bien loin de l’image intimidante d’une automatisation des tests « trop technique », inaccessible à la majorité de l’équipe projet !
Maintenant, à quoi ressemble le script ?
Nous avons listé 12 requêtes à vérifier dans le fichier dont on parlait précédemment. Il suffit maintenant de déclarer ce fichier comme source de données pour le test automatisé.
Voici un exemple sur JUnit 5, qui utilise l’annotation @ParameterizedTest :
@CsvFileSource(files = "src/test/resources/requetes.csv")
@ParameterizedTest
public void recherche_simple(String requete, int nb_resultats_attendus){
lancerRecherche(requete);
verifierNbResultatsAttendus(nb_resultats_attendus);
}
12 tests en un… c’est merveilleux, non ? 🙂
10, 100, 1000 cas de test… quelle est la limite ?
L’enfer est pavé de bonnes intentions
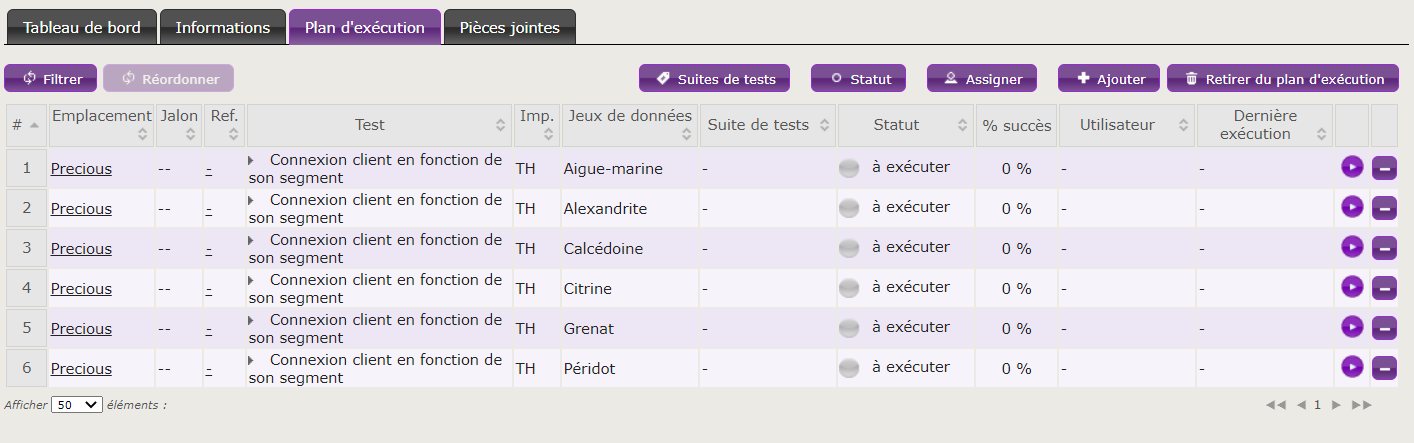
Vous l’aurez compris, avec le DDT, le coût de développement sera le même pour 10, 100 ou 1000 jeux de données. Dans cette mesure, il peut être séduisant de lancer l’automate sur le plus de cas possible.
Nous avons développé le test en 1 heure, il va jouer 1000 tests qui durent chacun 1 minute, nous aurons donc forcément atteint notre ROI au bout de la première exécution du 61ème test ! C’est vertigineux !
Halte là ! Une belle peau de banane vient de se mettre dans votre chemin : l’envie (consciente ou non) de prouver le ROI à tout prix.
Dans l’exemple précédent, nous vérifions que la requête « Sandrawa Geffroidwa » ne remonte aucun résultat. Il serait possible, au même coût de développement, de vérifier aussi que « Sandrawo Geffroidwo » produit le même résultat, et ainsi de suite avec n’importe quel suffixe.
De même, on pourrait imaginer un test de création d’utilisateur avec comme pseudo « Julie », et un autre identique, avec cette fois un pseudo différent, « Marie ». Pourquoi pas… mais pourquoi ? Les 2 pseudos tiennent sur 5 caractères ASCII, quel intérêt cela apporte-t-il de tester ces deux cas ?
Rien ne sert de gonfler artificiellement le nombre de jeux de données, même si cela donne l’impression d’atteindre plus vite le ROI.
Les risques à avoir en tête
Certains paramètres doivent en effet être pris en compte en-dehors du coût de développement :
- Le test va mettre un certain temps à s’exécuter. Peut-être quelques secondes… mais une flopée de tests inutiles peut faire perdre à la longue de précieuses minutes voire de longues heures !
- Le test va produire des résultats que des personnes vont analyser, surtout si le test est en erreur. Or, dans cet exemple, les deux tests produiront (très très certainement) le même résultat. Il n’est pas question de faire perdre de temps d’analyse sur ce type de tests en doublon.
- Comme les résultats seront identiques, le rapport global des tests sera biaisé.
- Le test va vivre et devra être maintenu… peut-être par une autre personne que vous. Cette personne va devoir se plonger dans les jeux de données afin de savoir pour quelle raison ils ont été conçus comme tels, et se demandera pourquoi tant de tests se ressemblent.
Bref, avec ou sans DDT, l’automatisation des tests reste en grande partie une pratique d’optimisation du temps de cerveau humain, et il ne faut pas perdre de vue cet aspect !
Solution simple
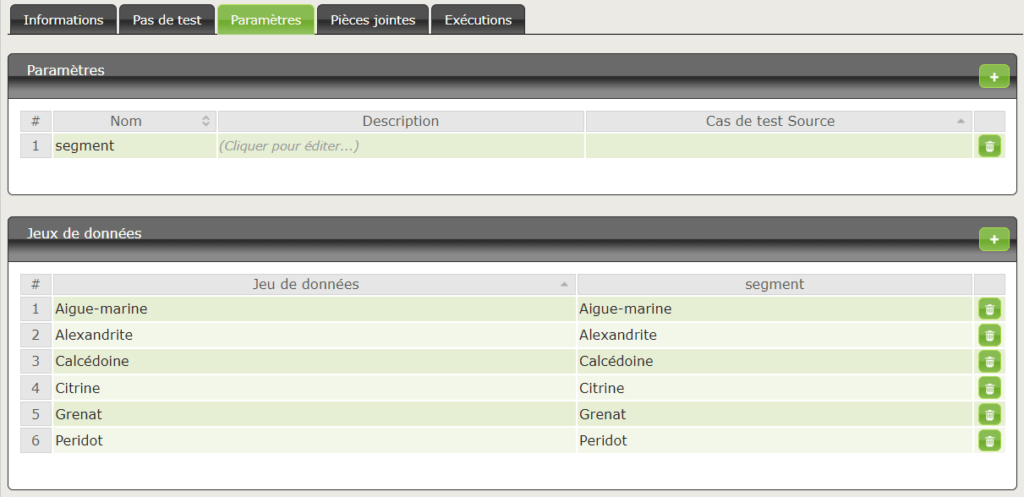
Nous préconisons donc de donner un nom à chacun des jeux de données, afin que quiconque soit en mesure de comprendre son sens et son utilité. Et si vous vous apprêtez à créer un jeu de données à faible valeur ajoutée, vous vous en rendrez compte d’autant mieux.
Votre tableur ressemblera donc plutôt à cela :
| nom_test | requete | nb_resultats_attendus |
| Prénom et nom | Sandra Geffroid | 1 |
| Prénom seul | Sandra | 2 |
| Prénom et nom avec accent superflu | Sandra Géffroid | 1 |
| Prénom tronqué | Sandr | 2 |
| Prénom et nom tronqués | Sandr Geffr | 1 |
| Prénom incorrect et nom correct | Sandro Geffroid | 1 |
| Prénom et nom incorrects | Sandro Geffroio | 0 |
| Prénom et nom corrects mais accolés d’un suffixe | Sandrawa Geffroidwa | 0 |
| Prénom et nom en majuscules | SANDRA GEFFROID | 1 |
| Prénom et nom en minuscules | sandra geffroid | 1 |
| Prénom et nom éclatés par des espaces | s a n d r a g e f f r o i d | 10 |
| Prénom et nom éclatés par des soulignés | S_a_n_d_r_a_G_e_f_f_r_o_i_d | 0 |
Et voilà, la peau de banane est écartée !
Quels outils permettent de faire du DDT ?
Cette approche est tellement efficace que rares sont les outils d’automatisation des tests qui ne permettent pas de la mettre en œuvre. De notre côté, nous l’utilisons aussi bien sur nos projets Selenium (avec JUnit 5), UFT, Protractor, Postman…
Si vous voulez un tutoriel pour mettre en oeuvre le Data Driven Testing avec JUnit 5, nous vous conseillons cette vidéo présente sur Test Automation University.
Le Data Driven Testing est une pratique incontournable : l’essayer, c’est l’adopter.
Et vous, utilisez-vous le Data Driven Testing ?









 Aaaaah on les veut toutes !!!!!!
Aaaaah on les veut toutes !!!!!!